
librosa-Pythonで音声処理, 音楽解析
librosaは音楽・オーディオの処理と解析ためのPythonパッケージです。librosaの実験 | 音声ロード | 音楽情報検索 | beat tracker | 音声の可視化 | harmonic-percussive | スペクトログラム
librosaは音楽・オーディオの処理と解析ためのPythonパッケージです。librosaの実験 | 音声ロード | 音楽情報検索 | beat tracker | 音声の可視化 | harmonic-percussive | スペクトログラム

AdaBeliefの最適化アルゴリズムとは、アダムとSGDに匹敵する一般化として高速収束を実現します。 勾配方向の「信念」に応じてステップサイズを適応させます。予測された勾配と観測された勾配の差によってステップサイズを適応的にスケーリングします。 Pythonの実験

Jupyter Notebook拡張機能「Move selected cell」、「Hinterland」
、「Snippets Menu」、「Runtools」、「Hide input」、「Hide input all」、「Table of Contents (2)」、Collapsible Headings」、絵文字
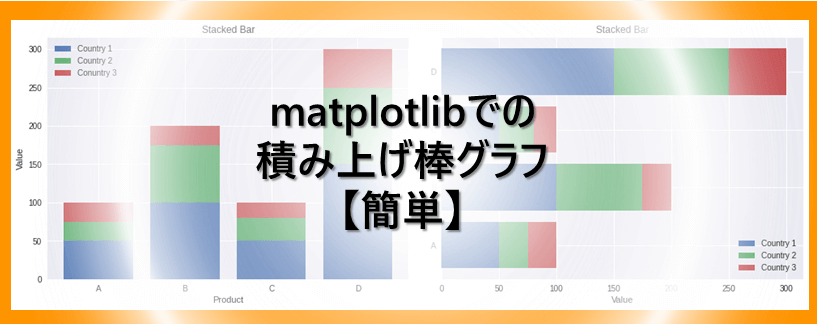
Matplotlib での積み上げ棒グラフを作成する方法について解説します。積み上げ縦棒グラフ | 積み上げ縦棒グラフ (割合) |積み上げ棒グラフ |積み上げ横棒グラフ (割合)

sklearn.feature_extraction.textのモジュールは、テキストの特徴を抽出することができます。| CountVectorizer | HashingVectorizer | TfidfTransformer| TfidfVectorizer

kaggle1位の解析手法:Help Protect the Great Barrier Reef:Googleが協力してサンゴ礁の水中ビデオで物体検出のコンペ|1位のパイプライン|データセット作成|モデル作成|モデル評価

kaggle1位の解析手法:Help Protect the Great Barrier Reef:Googleが協力してサンゴ礁の水中ビデオで物体検出のコンペ|概要|評価|タイムライン|データ|探索的データ分析(EDA)

mlxtendの可視化の紹介と実験です。主成分分析(PCA Correlation)|学習曲線(Learning Curve)|混同行列(Confusion Matrix)|決定境界(Decision Regions)|線形回帰(Linear Regression)

目次 1. TensorFlowのFairness Indicators 1.1 公平性指標(Fairness Indicators)とは 1.2 Fairness IndicatorsのAPI 2. 実験 2.1 環境構築 2.2 データセット 2.3 公平性指標 関連記事: 機械学習モデルを解釈するSHAP eli5でモデルの解釈 1. TensorFlowのFairness Indicators 1.1 公平性指標(Fairness Indicators)とは Fairness Indicators はTensorFlow Model Analysis (TFMA)のパッケージにあり、公平性メトリックの計算するライブラリです。既存のツールの多くは、大規模なデータセットやモデルではうまく機能しません。しかしTensorflowのFairness Indicatorsでは、10億ユーザーのシステムで動作できるツールで大規模に強いのが特徴です。 公平性指標でやることは、 データセットの分布 定義されたユーザーグループ間のモデルのパフォーマンスを評価 個々のスライスを深く掘り下げて、根本的な原因で改善 です。 1.2 Fairness IndicatorsのAPI パッケージ: Tensorflowデータ検証(TFDV) Tensorflowモデル分析(TFMA)公平性指標 What-Ifツール(WIT) 資料https://www.tensorflow.org/tfx/guide/fairness_indicators#render_fairness_indicators GitHub: https://github.com/tensorflow/fairness-indicators 2. 実験 環境:Google Colab …

目次 1. Mlxtendの概要 1.1 Mlxtendとは 1.2 頻繁なパターンのモジュール 1.3 mlxtendのインストール 2. Apriori 2.1 Aprioriのアルゴリズム 2.2 Aprioriの実験 3. 相関ルール 2.1 Association Rulesのアルゴリズム 2.2 Association Rulesの実験 関連記事: 協調フィルタリング(Collaborative filtering)レコメンドエンジン レコメンドのランキングの評価指標 (PR曲線とAUC, MRR, MAP, nDCG) 1. Mlxtendの概要 1.1 Mlxtendとは Mlxtendは machine learning extensionsの英語略称で、データサイエンティストの作業のライブラリです。サンプルデータ、前処理、モデル作成、モデル評価、可視化などのモジュールを提供しています。今回はfrequent_patternsのモジュールを解説したいと思います。 Mlxtendのモジュール:http://rasbt.github.io/mlxtend/USER_GUIDE_INDEX/ Mlxtendのgithub:https://github.com/rasbt/mlxtend 1.2 頻繁なパターンのモジュール 頻繁なパターン(frequent_patterns)のモジュールはapriori、association_rules、fpgrowth、fpmaxがあります。一緒に何が変われるかというパターンを理解するために、アソシエーション分析のアルゴリズムのモジュールです。 1.3 mlxtendのインストール Colabの環境で、mlxtendを更新します。 !pip install mlxtend –upgrade import mlxtend mlxtend.__version__ 0.19.0 …