
目次
1. librosaとは
– librosaのモジュール一覧
2. librosaの実験
2.1 librosaの環境構築
2.2 音声ロード
2.3 音楽情報検索
2.4 beat tracker
2.5 音声の可視化
2.6 harmonic-percussive
2.7 スペクトログラム
1. librosaとは
librosaは音楽・オーディオの処理と解析をするPythonパッケージです。
– librosaのモジュール一覧
librosa : ibrosaのコア
librosa.beat : テンポ、ビートを検出する機能
librosa.decompose: 調波打楽器音分離とスペクトログラムの分解に関する機能
librosa.display: 音声データの可視化する機能
librosa.effects: ピッチシフトとタイムストレッチといった音声処理機能
librosa.feature: 音声の特徴抽出機能
librosa.filters: フィルタバンクを生成する機能
librosa.onset: オンセット検出とオンセット強度計算に関する機能
librosa.segment: 再帰行列の構築、逐次制約付きクラスタリングなどのための関数の機能
librosa.sequence: ビタビ復号化、遷移行列といった逐次モデリングのために必要な関数の機能
librosa.util: 正規化、パディング、センタリングといった関数の機能
資料:https://librosa.org/doc/latest/index.html
Github:https://github.com/librosa/librosa
2. librosaの実験
2.1 librosaの環境構築
PyPIでのインストール
| pip install librosa |
Anacondaでのインストール
| conda install -c conda-forge librosa |
今回はGoogle Colabで実験します。Librosaがインストールされています。
2.2 音声ロード
Nutcrackerのサンプルデータをロードします。yの音声のデータとsrのサンプルレートを出力します。
サンプリングレートは、1秒間に実行する標本化処理の回数です。例えば、標準的なサンプリングレートである44.1kHzの場合、毎秒44100回標本化を行うということです。
| # Load example import librosa
filename = librosa.example(‘nutcracker’) y, sr = librosa.load(filename, duration=20.0) |
音声を確認します。
| import IPython.display
IPython.display.Audio(data=y, rate=sr) |
2.3 音楽情報検索
結果を確認します。
22050のサンプルレート、441000のサンプルデータ、20秒です。
| print(sr) # sampling rate print(y) print(len(y)) # total sample print(len(y)/sr) # second |
22050
[ 2.2716861e-06 5.3327208e-06 -7.2473290e-06 … 7.9551965e-02
7.2584212e-02 6.9123745e-02]
441000
20.0
ビット深度(びっとしんど)は、ある単位あたりのビット数です。 ビットの深さ、ビットデプス (bit depth) とも表現します
これらは、以下の対応あります。
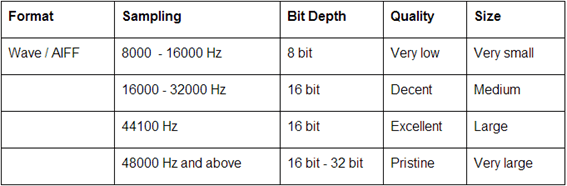
ただし以下の場合はビットレートで、下記のような音声の品質表です。
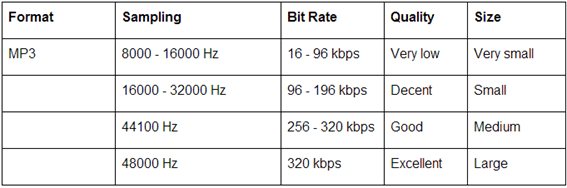
2.4 beat tracker
テンポ、ビートを検出するができます。
112 ビート・パー・ミニッツになります。
ビート・パー・ミニッツ(BPM:Beat Per Minute)は1分間の拍数を示す値で曲のテンポを示す数値。
| # Run beat tracker tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
# tempo beats per minute print(f’Estimate tempo {tempo :.2f} beats per minute’) |
Estimate tempo 112.35 beats per minute
2.5 音声の可視化
Matplotlibで音声の可視化します。
| import matplotlib.pyplot as plt import librosa.display
plt.figure() plt.subplot(3, 1, 1) librosa.display.waveplot(y, sr=sr) plt.title(‘Monophonic’) |
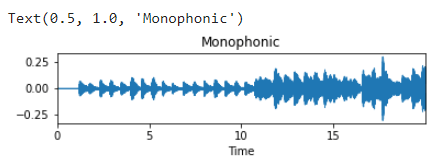
2.6 harmonic-percussive
HPSS(Harmonic/Percussive Sound Separation)というのは、音源中の調波音/打楽器音が、それぞれ時間方向に滑らか/周波数方向に滑らかという異った性質を持つことを利用して、両者を分離する方法のことです。
y_harm, y_perc とのharmonic-percussiveの音声を簡単にできます。
| # Separate harmonics and percussives into two waveforms import librosa.display
y_harm, y_perc = librosa.effects.hpss(y)
print(y_harm.shape) print(y_harm) |
harmonic-percussiveの可視化
| plt.subplot(3, 1, 3) librosa.display.waveplot(y_harm, sr=sr, alpha=0.25) librosa.display.waveplot(y_perc, sr=sr, color=’r’, alpha=0.5) plt.title(‘Harmonic + Percussive’) plt.tight_layout() plt.show() |
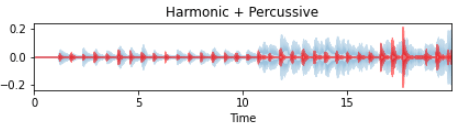
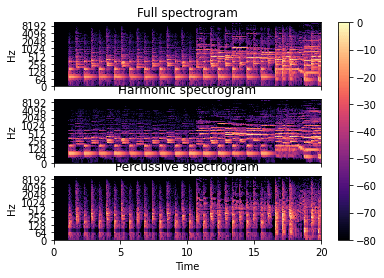
2.7 スペクトログラム
音声信号に「短時間フーリエ変換(Short-time Fourier transform : STFT)」を行うことでスペクトログラムが得られます。
harmonic-percussiveのスペクトログラムを可視化します。スペクトログラムの画像データは画像の深層学習ネットワークに入力することができます。
| import numpy as np import matplotlib.pyplot as plt
from IPython.display import Audio
import librosa import librosa.display
D = librosa.stft(y)
D_harmonic, D_percussive = librosa.decompose.hpss(D)
# Pre-compute a global reference power from the input spectrum rp = np.max(np.abs(D))
fig, ax = plt.subplots(nrows=3, sharex=True, sharey=True)
img = librosa.display.specshow(librosa.amplitude_to_db(np.abs(D), ref=rp), y_axis=’log’, x_axis=’time’, ax=ax[0]) ax[0].set(title=’Full spectrogram’) ax[0].label_outer()
librosa.display.specshow(librosa.amplitude_to_db(np.abs(D_harmonic), ref=rp), y_axis=’log’, x_axis=’time’, ax=ax[1]) ax[1].set(title=’Harmonic spectrogram’) ax[1].label_outer()
librosa.display.specshow(librosa.amplitude_to_db(np.abs(D_percussive), ref=rp), y_axis=’log’, x_axis=’time’, ax=ax[2]) ax[2].set(title=’Percussive spectrogram’) fig.colorbar(img, ax=ax) |

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト