
目次
1. ChatGPTとは
2. ChatGPTが日本語でできること、できないこと
3. ChatGPTモデル
4. ChatGPT4の成長
5. ChatGPT作成方法
6. まとめ
1. ChatGPTとは
ChatGPTは、OpenAIが開発した大規模言語モデルの一種であり、GPT-3.5アーキテクチャーに基づいています。GPTとは、「Generative Pre-trained Transformer」の略称で、自然言語処理のタスクにおいて、最先端の性能を発揮するモデルの一つです。ChatGPTは、GPTの日本語版とも言えます。ChatGPTは、文章生成、文章の翻訳、文章の要約、文章の質問応答、文章の感情分析、文章の自動修正、文章の自動生成など、多様な言語タスクを実行できるように設計されています。
すべてのチャットボットがChatGPTのようにAIを使用しているわけではありません。一部のチャットボットは、単にキーワードを使用して、役に立つかどうかわからない応答を作成するだけです。例えば、非AIチャットボットに荷物が配達済みと表示されているにもかかわらず届かなかったことを伝えると、チャットボットは単に玄関先をチェックするよう促すかもしれません。一方、ChatGPTのような他のチャットボットは、非常に高度なAIを使用しています。
2. ChatGPTが日本語でできること、できないこと
ChatGPTは、日本語を含む複数の言語に対応しており、日本語でも文章生成、翻訳、要約、質問応答などのタスクを実行することができます。ただし、日本語においては、日本語特有の文法や表現方法に対する理解が不十分なため、時には不自然な回答を生成する場合があります。また、日本語の表記揺れや略語に対しても対応していないため、正確性に欠ける場合があります。ただし、ChatGPTは学習に使用したデータの質や量によって性能が大きく異なるため、今後の改善が期待されます。
ChatGPTが最も得意とする5つのタスク
ChatGPTがビジネス生産性を向上するのに最適な5つのタスクを見てみましょう。
2.1 タスクとワークフローを自動化する
ChatGPTは、ルーチンやワークフローを処理することができます。時間のかかる日々の繰り返し作業を管理できます。たとえば、ミーティングのスケジュール管理、イベントのリマインダーの生成、溢れる受信トレイの管理、電子メール、レビュー、またはソーシャルメディアのコメントに対する返信などがあります。
2.2 コーディングアシスタント
ChatGPTは、C ++、Python、JavaScriptなどのプログラミング言語に堪能なプログラマーのコーディングアシスタントとして機能します。コードを書き、デバッグすることができます。イングランドのファイナンス、テクノロジー、および起業家精神のセンターがLinkedInプラットフォームで実施したPythonに関するコーディングアセスメントテストによると、ChatGPTは、テストを受けた400万人のプログラマーのうち、約85%を上回る成績を収めました。
2.3検索エンジン
ChatGPTは、従来の検索エンジンのようにリンクを共有するのではなく、ユーザーの質問に文脈的に関連する回答を提供できる高度な検索エンジンとして機能します。ChatGPTは新しいテクノロジーなので、2021年までのデータでトレーニングされています。ただし、2023年2月にMicrosoftのBing検索エンジンとの統合が行われたため、Bingが最新のデータを利用して正確な結果を提供できるようになりました。
2.4 コンテンツ作成
ChatGPTは、アイデアを出し、コンテンツを作成することができます。例えば、YouTubeチャンネルのコンテンツの作成にアイデアを与えたり、友人の誕生日の祝い方についてのプロンプトを提供したり、会社の生産性を向上させるビジネスアイデアを提供したりすることができます。
2.5 映画の脚本、ストーリー、歌詞の生成
ChatGPTは、希望する映画のジャンルや登場人物の詳細を提供すると、映画の脚本をシナリオ形式で生成することができます。さらに、ChatGPTは、どんなトピックにも簡単に歌や詩を書くことができます。
3.ChatGPTモデルデル
ChatGPTは、GPT-3.5アーキテクチャーに基づいています。このモデルは、トランスフォーマーと呼ばれる機械学習のアーキテクチャーを使用しており、自然言語処理のタスクにおいて驚異的な性能を発揮しています。ChatGPTは、数十億のパラメータを持ち、大量の文章データを学習することで、自然な文章生成や多様な言語タスクを高精度で実行することができます。ChatGPTは、トークナイズ(単語や文章を分割する処理)された文章を入力とし、それに対する回答や生成結果を出力します。
4. ChatGPT4の成長
GPT-4 は、画像とテキストの入力を処理し、テキスト出力を生成できる大規模なマルチモーダル モデルです。
その機能にもかかわらず、GPT-4 には以前の GPT モデルと同様の制限があります。 最も重要なことは、まだ完全に信頼できるわけではないということです。 GPT-4 は、以前の GPT-3.5 モデルに比べて幻覚を大幅に軽減します。
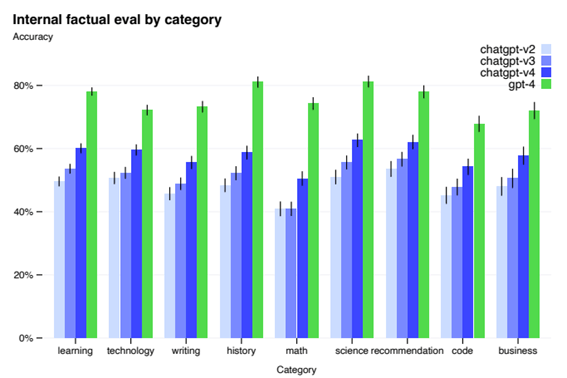
敵対的に設計された 9 つの内部事実性評価に対する GPT-4 のパフォーマンス。 精度は y 軸に表示され、高いほど優れています。 1.0 の精度は、モデルの回答が、評価のすべての質問に対する人間の理想的な回答と一致していると判断されたことを意味します。
5. ChatGPT作成方法
ChatGPTは、GPT-3の改良版であり、微調整が施されました。この微調整プロセスでは、人間からのフィードバックを受け取って強化学習を行うRLHF(Reinforcement Learning from Human Feedback)という手法が使用され、教師あり学習と強化学習の両方を活用しました。これらのアプローチの両方が、人間のトレーナーを使ってモデルのパフォーマンスを改善するのに役立ちました。
教師あり学習の場合、モデルには、トレーナーがユーザーと AI アシスタントの両方を演じる会話が提供されました。 強化学習のステップでは、まず人間のトレーナーが、モデルが以前の会話で作成した応答をランク付けしました。 これらのランキングは、Proximal Policy Optimization (PPO) を数回繰り返してモデルをさらに微調整した「報酬モデル」を作成するために使用されました。 近接ポリシー最適化アルゴリズムは、信頼領域ポリシー最適化アルゴリズムに費用対効果の高い利点をもたらします。 より高速なパフォーマンスで、計算コストの高い操作の多くを無効にします。
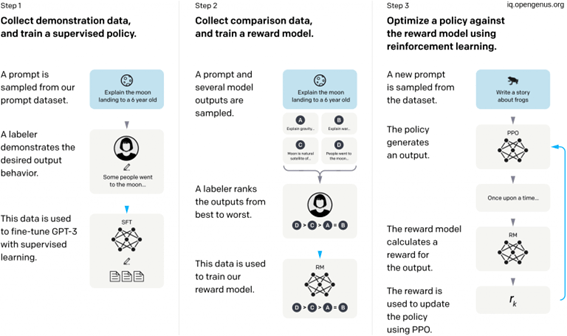
人間のフィードバックからの強化学習
この方法は、次の3つの異なるステップで構成されています。
1. 監視付き微調整ステップ:事前にトレーニングされた言語モデルを比較的少量のデモデータで微調整し、選択した一覧から出力を生成する監視付きポリシー(SFTモデル)を学習します。これは基本ラインモデルを表します。
2. 「人間の好みを模倣する」ステップ:ラベラーによって比較的多数のSFTモデルの出力に投票してもらい、これにより比較データが作成されます。このデータセットを使用して新しいモデルをトレーニングします。これは報酬モデル(RM)と呼ばれます。
3. Proximal Policy Optimization(PPO)ステップ:報酬モデルを使用して、SFTモデルをさらに微調整して改善します。このステップの結果がポリシーモデルと呼ばれます。
ステップ1は1回だけ行われますが、ステップ2と3は継続的に反復することができます。現在の最良のポリシーモデルでさらに比較データを収集し、それを使用して新しい報酬モデルをトレーニングし、その後新しいポリシーをトレーニングすることができます。
GPT3は公開されていません。同様に大きな言語モデルがたくさんあります。
mT5 は、mC4 コーパスで Google によって事前トレーニングされており、101 の言語をカバーしています。
以下の例は、XNLI ゼロショット タスクで mT5-Large モデルを微調整する方法を示しています。
(https://github.com/google-research/multilingual-t5)
| export PROJECT=yourproject export ZONE=yourzone export BUCKET=yourbucket export TPU=yourtpu
ctpu up –name=$TPU –project=$PROJECT –zone=$ZONE –tpu-size=v3-256 –tpu-only –noconf
TASK=mt5_xnli_zeroshot SEQUENCE_LENGTH_GIN=xnli PRETRAINED_DIR=gs://t5-data/pretrained_models/mt5/large PRETRAINED_STEPS=1000000 FINETUNE_STEPS=20000 MODEL_DIR=”${BUCKET}${TASK}”
# Run fine-tuning python -m t5.models.mesh_transformer_main \ –tpu=”${TPU}” \ –gcp_project=”${PROJECT}” \ –tpu_zone=”${ZONE}” \ –model_dir=”${MODEL_DIR}” \ –gin_file=”${PRETRAINED_DIR}/operative_config.gin” \ –gin_file=”sequence_lengths/${SEQUENCE_LENGTH_GIN}.gin” \ –gin_param=”utils.tpu_mesh_shape.tpu_topology = ‘v3-256′” \ –gin_param=”MIXTURE_NAME = ‘${TASK}'” \ –gin_param=”utils.run.train_steps=$((PRETRAINED_STEPS+FINETUNE_STEPS))” \ –gin_param=”utils.run.init_checkpoint=’${PRETRAINED_DIR}/model.ckpt-${PRETRAINED_STEPS}'” \ –t5_tfds_data_dir=”${BUCKET}/t5-tfds” \ –module_import=”multilingual_t5.tasks” \ –gin_param=”utils.run.batch_size = (‘tokens_per_batch’, 1048576)” \ –gin_location_prefix=”multilingual_t5/gin/” |
BLOOMは、オープンアクセスの多言語モデルで、176Bパラメータを持ちます。BLOOMは、46の自然言語と13のプログラミング言語でテキストを生成できます。
以下のコードは、モードを微調整するための例です。 高い GPU メモリが必要でした。
| !python run_qa.py \ –model_name_or_path bigscience/bloom-560m \ –dataset_name squad_v2 \ –do_train \ –per_device_train_batch_size 12 \ –learning_rate 3e-5 \ –num_train_epochs 2 \ –max_seq_length 384 \ –doc_stride 128 \ –output_dir /tmp/debug_seq2seq_squad/ \ –eval_accumulation_steps 1 \ –version_2_with_negative \ –overwrite_output_dir |
X-MOD モデルは META として提案され、81 の言語でサポートされています。X-MOD は XLM-R に似ていますが、正しい言語アダプターをアクティブにするには、入力言語を指定する必要があるという違いがあります。
このコードを使用して、モデルを微調整できます。
| from transformers import XmodModel
model = XmodModel.from_pretrained(“facebook/xmod-base”) model.set_default_language(“en_XX”)
model.freeze_embeddings_and_language_adapters() |
6. まとめ
ChatGPTは、OpenAIが開発した大規模言語モデルであり、日本語を含む複数の言語に対応しています。ChatGPTは、文章生成、文章の翻訳、文章の要約、文章の質問応答、文章の感情分析、文章の自動修正、文章の自動生成など、多様な言語タスクを実行できるように設計されています。ただし、日本語においては、日本語特有の文法や表現方法に対する理解が不十分なため、時には不自然な回答を生成する場合があります。ChatGPTは、GPT-3の改良版であり、微調整が施され、人間からのフィードバックを受け取って強化学習を行うRLHF(Reinforcement Learning from Human Feedback)という手法が使用され、教師あり学習と強化学習の両方を活用しました。GPT-4は、画像とテキストの入力を処理し、テキスト出力を生成できる大規模なマルチモーダルモデルです。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属