
目次:
- FRESHLLMSとは
- 研究の背景と目的
- FRESHLLMSの主な特徴
- FRESHPROMPTの効果
- 実験(コードの説明)
- まとめ
1. FRESHLLMSとは
FRESHLLMS(Refreshing Large Language Models with Search Engine Augmentation)は、大規模言語モデル(LLMs)を検索エンジンのデータで動的に更新し、それらの事実性を強化するための新たな試みです。このアプローチでは、最新の情報に基づいてモデルが自己更新することで、世界の変化に迅速に対応できるように設計されています。これにより、従来の一度学習後は更新されないLLMsの問題点を解決し、より信頼性の高い情報源としての利用が可能となります。
大規模言語モデルは、その訓練データが古くなるにつれて、その効果が低下します。FRESHLLMSは、リアルタイムの検索エンジン結果を取り入れることで、モデルの知識を常に最新の状態に保つことを目指しています。この研究の主な目的は、モデルが古い情報に基づいて誤った回答を生成することなく、最新の事実やデータに基づいて正確な情報を提供できるようにすることです。
論文: https://arxiv.org/abs/2310.03214
GitHub: https://github.com/freshllms/freshqa?tab=readme-ov-file#freshqa
2.FRESHLLMSの主な特徴
動的な知識更新: 最新の検索エンジンの情報を直接モデルに組み込むことで、情報が古くなることなく、常に最新の状態を保ちます。
FRESHQAベンチマーク: 新しく開発されたベンチマークを通じて、様々な種類の問題に対するモデルの反応を評価します。
FRESHPROMPT技術: 検索結果を用いたプロンプティング技術を用いて、モデルが情報を最大限に活用する方法を学びます。
3. FRESHPROMPの効果
FRESHPROMPTは、検索エンジンから得た情報を基に、モデルに質問の前提を理解させ、適切な回答を導き出すよう訓練する方法です。この技術を用いることで、モデルは特に情報が頻繁に更新されるトピックに関して、高い精度で回答を生成することが可能になります。初期のテストでは、従来のモデルと比較して大幅に事実性が向上したことが示されています。
FRESHQAは600問の質問からなる動的な質問応答(QA)ベンチマークです。このベンチマークは、変わりやすい情報(「最新のニュースは何か?」など)、偽の前提を持つ質問(「2022年にトランプがツイートした内容は?」)、一般的な知識問題など、多岐にわたるカテゴリーを含んでいます。これにより、モデルが現実世界のデータにどれだけ迅速かつ正確に対応できるかを評価します。
FRESHLLMSプロジェクトでは、50,000件以上の人間による評価が行われ、新しい技術がモデルの性能に与える影響が広範囲に渡って検証されました。この評価から、特に最新情報を必要とする質問において、顕著な改善が見られたことが分かります。
4. 実験(コードの説明)
Freshpromptは下記のノートブックです。
https://github.com/freshllms/freshqa/blob/main/freshprompt.ipynb
| def freshprompt_format( question, search_data, reasoning_and_answer, num_organic_results, num_related_questions, num_questions_and_answers, num_retrieved_evidences, ): “””Build FreshPrompt for each question
Args: question: The question to process. search_data: Search data. reasoning_and_answer: The reasoning and answer. num_organic_results: Number of organic results to keep. num_related_questions: Number of related questions to keep. num_questions_and_answers: Number of questions and answers to keep. num_retrieved_evidences: Number of retrieved evidences to keep.
Returns: A prompt that incorporates retrieved evidences for each question. “””
df = pd.DataFrame(columns=[‘source’, ‘date’, ‘title’, ‘snippet’, ‘highlight’])
# Organic results organic_results = [None] * num_organic_results for k in range(num_organic_results): if ( ‘organic_results’ in search_data and len(search_data[‘organic_results’]) > k ): organic_results[k] = format_search_results( search_data[‘organic_results’][k] ) else: organic_results[k] = format_search_results({})
for d in organic_results[::-1]: df = pd.concat([df, pd.DataFrame([d])], ignore_index=True)
# Related questions related_questions = [None] * num_related_questions for k in range(num_related_questions): if ( ‘related_questions’ in search_data and len(search_data[‘related_questions’]) > k ): related_questions[k] = format_search_results( search_data[‘related_questions’][k], title_field=’question’ ) else: related_questions[k] = format_search_results({})
for d in related_questions[::-1]: df = pd.concat([df, pd.DataFrame([d])], ignore_index=True)
# Questions and Answers questions_and_answers = [None] * num_questions_and_answers for k in range(num_questions_and_answers): if ( ‘questions_and_answers’ in search_data and len(search_data[‘questions_and_answers’]) > k ): questions_and_answers[k] = format_questions_and_answers( search_data[‘questions_and_answers’][k] ) else: questions_and_answers[k] = format_questions_and_answers({})
for d in questions_and_answers[::-1]: df = pd.concat([df, pd.DataFrame([d])], ignore_index=True)
# Knowledge graph knowledge_graph = None if ‘knowledge_graph’ in search_data: knowledge_graph = format_knowledge_graph(search_data[‘knowledge_graph’]) else: knowledge_graph = format_knowledge_graph({}) df = pd.concat([df, pd.DataFrame([knowledge_graph])], ignore_index=True)
# Answer box answer_box = None if ‘answer_box’ in search_data: answer_box = format_search_results( search_data[‘answer_box’], highlight_field=’answer’ ) else: answer_box = format_search_results({}) df = pd.concat([df, pd.DataFrame([answer_box])], ignore_index=True)
# Sort by date df[‘date’] = df[‘date’].apply(lambda x: format_date(x)) df[‘datetime’] = pd.to_datetime(df[‘date’], errors=’coerce’) df = df.sort_values(by=’datetime’, na_position=’first’) df.replace({pd.NaT: None}, inplace=True) df = df.dropna(how=’all’)
# Select top_k supporting evidences overall evidences = []
for _, row in df.tail(num_retrieved_evidences).iterrows(): evidences.append( f”””\n\nsource: {row[‘source’]}\ndate: {row[‘date’]}\ntitle: {row[‘title’]}\nsnippet: {row[‘snippet’]}\nhighlight: {row[‘highlight’]}””” )
return ( ”.join( [ f’\n\n\nquery: {question}’, ] + evidences ) + f’\n\nquestion: {question}{reasoning_and_answer}’ )
|
freshprompt_format は、特定の質問に対して、関連する検索結果とそれに基づく推論と回答を組み合わせた「FRESHPROMPT」を生成するために設計されています。このプロンプトは、大規模言語モデル(LLM)を使用して質問に答える際に、より精確で情報に基づいた回答を導くのに役立つように構築されます。以下に関数の各部分について詳しく説明します。
引数
question: 処理する質問のテキスト。
search_data: 質問に関連する検索データ。これには有機検索結果、関連質問、Q&Aなどが含まれるかもしれません。
reasoning_and_answer: 質問に対する推論と答えのテキスト。
num_organic_results: 保持する有機検索結果の数。
num_related_questions: 保持する関連質問の数。
num_questions_and_answers: 保持する質問と回答の数。
num_retrieved_evidences: 結果的に保持する証拠の数。
プロセスの説明
データフレームの初期化:
初期化された空のデータフレーム df は、検索結果を格納するために使用されます。
有機検索結果の処理:
指定された数 (num_organic_results) の有機検索結果が処理され、それぞれが format_search_results 関数を使用してフォーマットされ、df に追加されます。
関連質問の処理:
指定された数の関連質問が同様に処理され、データフレームに追加されます。
質問と回答の処理:
質問とそれに対する回答も同様に処理されてデータフレームに追加されます。
知識グラフの処理:
もし存在するなら、知識グラフも処理されてデータフレームに追加されます。
回答ボックスの処理:
回答ボックスがある場合、それも同様に処理されます。
データの並べ替えと選択:
全ての検索結果は日付に基づいて並べ替えられ、最新のものから指定された数 (num_retrieved_evidences) の証拠が選択されます。
プロンプトの構築:
最終的なプロンプトは、選択された証拠とともに質問とその推論と回答が組み合わされて形成されます。このプロンプトは、言語モデルが質問に対して情報に基づいた回答を生成するために使用されます。
実験の結果
検索エンジンの拡張機能はデータを取得できる場合とできない場合があります。情報が見つからない場合は、でたらめを言わないようにしてください。情報が見つかった場合は、その情報を使って回答を支援します。
情報が見つからない場合:
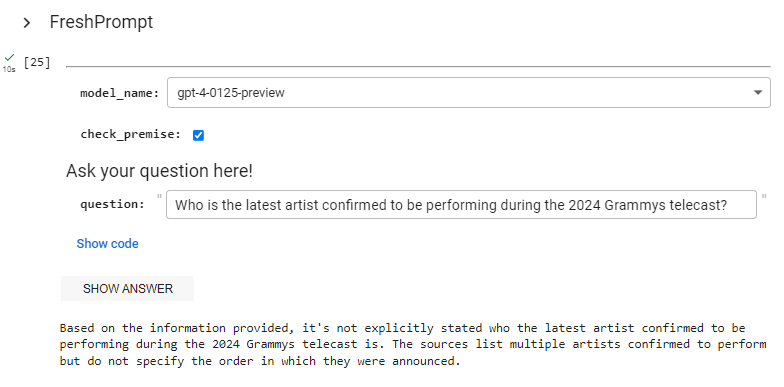
情報が見つかった場合:

5. まとめ
FRESHLLMSは、大規模言語モデルの可能性を拡張し、現代の情報に基づいた知識をモデルに提供するための有効な手段を提供します。このアプローチにより、モデルはより信頼性の高い情報源として活用できるようになり、最新のデータを反映した正確な回答を提供することが可能です。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト