
目次
1. TensorFlowのFairness Indicators
1.1 公平性指標(Fairness Indicators)とは
1.2 Fairness IndicatorsのAPI
2. 実験
2.1 環境構築
2.2 データセット
2.3 公平性指標
関連記事:
1. TensorFlowのFairness Indicators
1.1 公平性指標(Fairness Indicators)とは
Fairness Indicators はTensorFlow Model Analysis (TFMA)のパッケージにあり、公平性メトリックの計算するライブラリです。既存のツールの多くは、大規模なデータセットやモデルではうまく機能しません。しかしTensorflowのFairness Indicatorsでは、10億ユーザーのシステムで動作できるツールで大規模に強いのが特徴です。
公平性指標でやることは、
- データセットの分布
- 定義されたユーザーグループ間のモデルのパフォーマンスを評価
- 個々のスライスを深く掘り下げて、根本的な原因で改善
です。
1.2 Fairness IndicatorsのAPI
パッケージ:
- Tensorflowデータ検証(TFDV)
- Tensorflowモデル分析(TFMA)公平性指標
- What-Ifツール(WIT)
資料https://www.tensorflow.org/tfx/guide/fairness_indicators#render_fairness_indicators
GitHub: https://github.com/tensorflow/fairness-indicators
2. 実験
環境:Google Colab
データセット:kaggleでの毒性の言葉の分類分析のデータセットです。性別、性的指向、宗教、民族などの特徴量と毒性の言葉のラベルの200万件のコメントのデータセットです。
https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data
2.1 環境構築
ライブラリをインストールします。
| !pip install -q -U pip==20.2 !pip install -q fairness-indicators !pip install -q witwidget |
ライブラリのインポート
| import os import tempfile import apache_beam as beam import numpy as np import pandas as pd from datetime import datetime import pprint
from google.protobuf import text_format
import tensorflow_hub as hub import tensorflow as tf import tensorflow_model_analysis as tfma import tensorflow_data_validation as tfdv
from tfx_bsl.tfxio import tensor_adapter from tfx_bsl.tfxio import tf_example_record
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators from tensorflow_model_analysis.addons.fairness.view import widget_view
from fairness_indicators.tutorial_utils import util
from witwidget.notebook.visualization import WitConfigBuilder from witwidget.notebook.visualization import WitWidget
from tensorflow_metadata.proto.v0 import schema_pb2 |
2.2 データセット
ファイルをよみこみます。
| download_original_data = False #@param {type:”boolean”}
if download_original_data: train_tf_file = tf.keras.utils.get_file(‘train_tf.tfrecord’, ‘https://storage.googleapis.com/civil_comments_dataset/train_tf.tfrecord’) validate_tf_file = tf.keras.utils.get_file(‘validate_tf.tfrecord’, ‘https://storage.googleapis.com/civil_comments_dataset/validate_tf.tfrecord’)
train_tf_file = util.convert_comments_data(train_tf_file) validate_tf_file = util.convert_comments_data(validate_tf_file)
else: train_tf_file = tf.keras.utils.get_file(‘train_tf_processed.tfrecord’, ‘https://storage.googleapis.com/civil_comments_dataset/train_tf_processed.tfrecord’) validate_tf_file = tf.keras.utils.get_file(‘validate_tf_processed.tfrecord’, ‘https://storage.googleapis.com/civil_comments_dataset/validate_tf_processed.tfrecord’) |
2.3 公平性指標
Tfdvで統計データ、欠損値、データ分布、不均衡性のどを確認できます。
92%の0ラベルの不均衡データを明らかにします。
| stats = tfdv.generate_statistics_from_tfrecord(data_location=train_tf_file) tfdv.visualize_statistics(stats) |
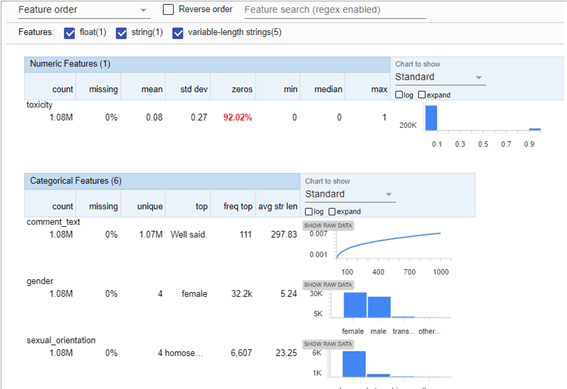
特徴量マップを作成します。
| BASE_DIR = tempfile.gettempdir()
TEXT_FEATURE = ‘comment_text’ LABEL = ‘toxicity’ FEATURE_MAP = { # Label: LABEL: tf.io.FixedLenFeature([], tf.float32), # Text: TEXT_FEATURE: tf.io.FixedLenFeature([], tf.string),
# Identities: ‘sexual_orientation’:tf.io.VarLenFeature(tf.string), ‘gender’:tf.io.VarLenFeature(tf.string), ‘religion’:tf.io.VarLenFeature(tf.string), ‘race’:tf.io.VarLenFeature(tf.string), ‘disability’:tf.io.VarLenFeature(tf.string), } |
不均衡データに重み列を追加するために、モデルの入力関数を作成します。
| def train_input_fn(): def parse_function(serialized): parsed_example = tf.io.parse_single_example( serialized=serialized, features=FEATURE_MAP) # Adds a weight column to deal with unbalanced classes. parsed_example[‘weight’] = tf.add(parsed_example[LABEL], 0.1) return (parsed_example, parsed_example[LABEL]) train_dataset = tf.data.TFRecordDataset( filenames=[train_tf_file]).map(parse_function).batch(512) return train_dataset |
モデル学習
深層学習モデルを学習します。
| model_dir = os.path.join(BASE_DIR, ‘train’, datetime.now().strftime( “%Y%m%d-%H%M%S”))
embedded_text_feature_column = hub.text_embedding_column( key=TEXT_FEATURE, module_spec=’https://tfhub.dev/google/nnlm-en-dim128/1′)
classifier = tf.estimator.DNNClassifier( hidden_units=[500, 100], weight_column=’weight’, feature_columns=[embedded_text_feature_column], optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.003), loss_reduction=tf.losses.Reduction.SUM, n_classes=2, model_dir=model_dir)
classifier.train(input_fn=train_input_fn, steps=1000) |
INFO:tensorflow:loss = 59.34302, step = 0
INFO:tensorflow:loss = 59.34302, step = 0
INFO:tensorflow:global_step/sec: 19.5454
INFO:tensorflow:global_step/sec: 19.5454
…
INFO:tensorflow:Loss for final step: 51.04924.
INFO:tensorflow:Loss for final step: 51.04924.
SavedModelをエクスポートします。
| def eval_input_receiver_fn(): serialized_tf_example = tf.compat.v1.placeholder( dtype=tf.string, shape=[None], name=’input_example_placeholder’)
# This *must* be a dictionary containing a single key ‘examples’, which # points to the input placeholder. receiver_tensors = {‘examples’: serialized_tf_example}
features = tf.io.parse_example(serialized_tf_example, FEATURE_MAP) features[‘weight’] = tf.ones_like(features[LABEL])
return tfma.export.EvalInputReceiver( features=features, receiver_tensors=receiver_tensors, labels=features[LABEL])
tfma_export_dir = tfma.export.export_eval_savedmodel( estimator=classifier, export_dir_base=os.path.join(BASE_DIR, ‘tfma_eval_model’), eval_input_receiver_fn=eval_input_receiver_fn) |
公平性メトリクスを計算します。
ドロップダウンを使用して、メトリックを計算するIDと、信頼区間で実行するかどうかを選択します。
| #@title Fairness Indicators Computation Options tfma_eval_result_path = os.path.join(BASE_DIR, ‘tfma_eval_result’)
#@markdown Modify the slice_selection for experiments on other identities. slice_selection = ‘sexual_orientation’ #@param [“sexual_orientation”, “gender”, “religion”, “race”, “disability”] print(f’Slice selection: {slice_selection}’) #@markdown Confidence Intervals can help you make better decisions regarding your data, but as it requires computing multiple resamples, is slower particularly in the colab environment that cannot take advantage of parallelization. compute_confidence_intervals = False #@param {type:”boolean”} print(f’Compute confidence intervals: {compute_confidence_intervals}’)
# Define slices that you want the evaluation to run on. eval_config_pbtxt = “”” model_specs { label_key: “%s” } metrics_specs { metrics { class_name: “FairnessIndicators” config: ‘{ “thresholds”: [0.1, 0.3, 0.5, 0.7, 0.9] }’ } } slicing_specs {} # overall slice slicing_specs { feature_keys: [“%s”] } options { compute_confidence_intervals { value: %s } disabled_outputs { values: “analysis” } } “”” % (LABEL, slice_selection, compute_confidence_intervals) eval_config = text_format.Parse(eval_config_pbtxt, tfma.EvalConfig()) eval_shared_model = tfma.default_eval_shared_model( eval_saved_model_path=tfma_export_dir)
schema = text_format.Parse( “”” tensor_representation_group { key: “” value { tensor_representation { key: “comment_text” value { dense_tensor { column_name: “comment_text” shape {} } } } } } feature { name: “comment_text” type: BYTES } feature { name: “toxicity” type: FLOAT } feature { name: “sexual_orientation” type: BYTES } feature { name: “gender” type: BYTES } feature { name: “religion” type: BYTES } feature { name: “race” type: BYTES } feature { name: “disability” type: BYTES } “””, schema_pb2.Schema()) tfxio = tf_example_record.TFExampleRecord( file_pattern=validate_tf_file, schema=schema, raw_record_column_name=tfma.ARROW_INPUT_COLUMN) tensor_adapter_config = tensor_adapter.TensorAdapterConfig( arrow_schema=tfxio.ArrowSchema(), tensor_representations=tfxio.TensorRepresentations())
with beam.Pipeline() as pipeline: (pipeline | ‘ReadFromTFRecordToArrow’ >> tfxio.BeamSource() | ‘ExtractEvaluateAndWriteResults’ >> tfma.ExtractEvaluateAndWriteResults( eval_config=eval_config, eval_shared_model=eval_shared_model, output_path=tfma_eval_result_path, tensor_adapter_config=tensor_adapter_config))
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path) |

What-ifツールで視覚化します。
| DEFAULT_MAX_EXAMPLES = 1000
# Load 100000 examples in memory. When first rendered, # What-If Tool should only display 1000 of these due to browser constraints. def wit_dataset(file, num_examples=100000): dataset = tf.data.TFRecordDataset( filenames=[file]).take(num_examples) return [tf.train.Example.FromString(d.numpy()) for d in dataset]
wit_data = wit_dataset(train_tf_file) config_builder = WitConfigBuilder(wit_data[:DEFAULT_MAX_EXAMPLES]).set_estimator_and_feature_spec( classifier, FEATURE_MAP).set_label_vocab([‘non-toxicity’, LABEL]).set_target_feature(LABEL) wit = WitWidget(config_builder) |
データポイントエディタのタブ
データ分布の確認と部分依存プロットの可視化
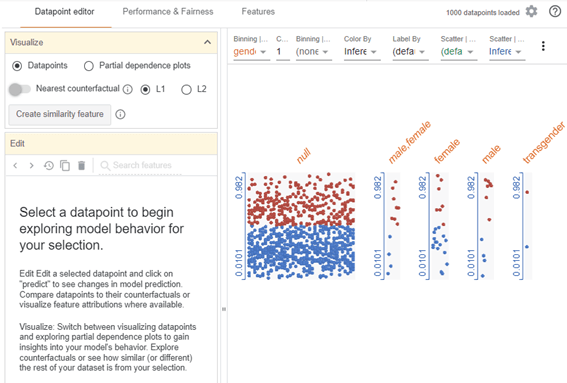
パフォーマンスと公平性のタブ
公平性を確認できます。
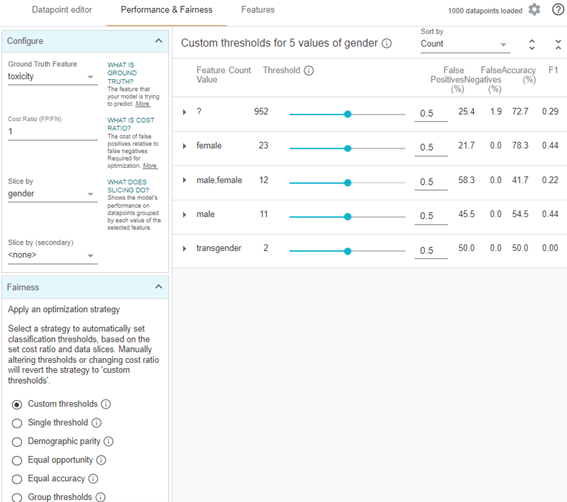
特徴量のタブ
特徴量の分布、欠損値などの確認です。
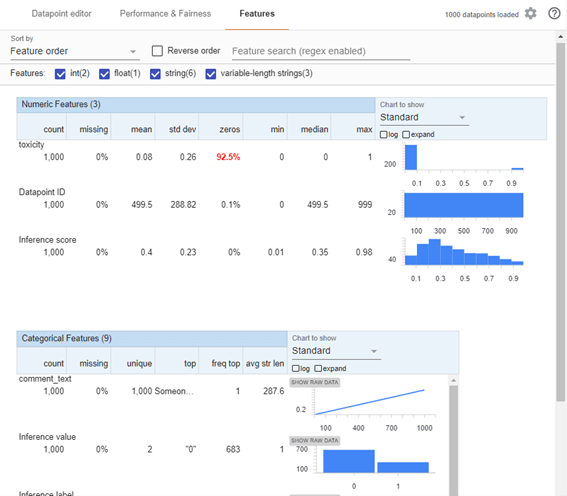
それぞれの特徴量が確認し、公平かどうかがわかるのが特徴です。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト