
目次
1. Nadam最適化アルゴリズムの概要
1.1 Nadam最適化アルゴリズムとは
1.2 TensorflowのNadam関数
2. 実験
2.1 ライブラリインポート
2.2 データ読み込み
2.3 データ加工
2.4 Nadamの最適化アルゴリズムを作成
2.3 Adamの最適化アルゴリズムを作成
2.5 まとめ
前回の記事は「最適化アルゴリズムのまとめ」を解説しました。今回の記事はNadamを解説と実験したいと思います。
1. Nadam
1.1 Nadam最適化アルゴリズムとは
Nadam (Nesterov-accelerated Adaptive Moment Estimation)はAdamとNAGを組み合わせます。
このことにより、前のタイムステップmt-1の運動量ベクトルにおけるバイアス補正された推定値を置き換えるだけで、以前と同じようにネステロフ運動量を追加できます。
現在の運動量ベクトルmtのバイアス補正された推定値を使用するのが、Nadam更新ルールを取得します。
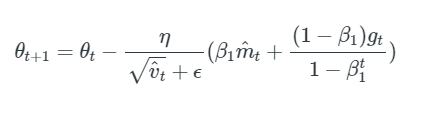
1.2 TensorflowのNadam関数
| tf.keras.optimizers.Nadam( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, name=’Nadam’, **kwargs ) |
Learning_rate
テンソルまたは浮動小数点値。 学習率。
beta_1
浮動小数点値または定数浮動小数点テンソル。 一次モーメント推定の指数関数的減衰率。
beta_2
浮動小数点値または定数浮動小数点テンソル。 指数関数的に重み付けされた無限大ノルムの指数関数的減衰率。
イプシロン
数値安定性のための小さな定数。
nameグラデーションを適用するときに作成される操作のオプションの名前。 デフォルトは「Nadam」です。
** kwargsキーワード引数。
「clipnorm」または「clipvalue」のいずれかになります。 「clipnorm」(フロート)は、ノルムによってグラデーションをクリップします。 「clipvalue」(フロート)は、グラデーションを値でクリップします。
2. 実験
環境:Google colab
データセット:Beansは、スマートフォンのカメラを使用して畑で撮影された
豆植物の画像のデータセットです。 それは3つのクラスで構成されています:2つの病気のクラスと健康なクラス。 病気には、Angular Leaf Spot とBean Rustの病が含まれます。 データは、ウガンダの国立作物資源研究所(NaCRRI)の専門家によって注釈が付けられ、マケレレAI研究所によって収集されました。

モデル:多クラス分類のDenseネットワーク
最適化アルゴリズム:Nadam vs. Adam
モデル評価:Accuracy
2.1 ライブラリインポート
データセット、Tensorflowの深層学習、可視化などのライブラリをインポートします。
| # Import Tensorflow Datasets import tensorflow_datasets as tfds tfds.disable_progress_bar()
import tensorflow as tf
# Helper libraries import math import numpy as np import matplotlib.pyplot as plt
# Logging import logging logger = tf.get_logger() logger.setLevel(logging.ERROR) |
2.2 データ読み込み
Tensorflowのデータセットを読み込みます。
| dataset, metadata = tfds.load(‘beans’, as_supervised=True, with_info=True) train_dataset, test_dataset = dataset[‘train’], dataset[‘test’] |
| dataset |
{‘test’: <PrefetchDataset shapes: ((500, 500, 3), ()), types: (tf.uint8, tf.int64)>,
‘train’: <PrefetchDataset shapes: ((500, 500, 3), ()), types: (tf.uint8, tf.int64)>,
‘validation’: <PrefetchDataset shapes: ((500, 500, 3), ()), types: (tf.uint8, tf.int64)>}
2.3 データ加工
ラベルデータを設定します。
| class_names = [‘Angular Leaf Spot’, ‘Bean Rust’, ‘Healthy’] |
学習とテストのデータを分けます。テストデータは128枚、学習データは1,034枚のデータになりました。
| num_train_examples = metadata.splits[‘train’].num_examples num_test_examples = metadata.splits[‘test’].num_examples print(“Number of training examples: {}”.format(num_train_examples)) print(“Number of test examples: {}”.format(num_test_examples)) |
Number of training examples: 1034
Number of test examples: 128
データを正規化します。
| def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
# Normalize train_dataset = train_dataset.map(normalize) test_dataset = test_dataset.map(normalize)
# Caching train_dataset = train_dataset.cache() test_dataset = test_dataset.cache() |
データを確認します。
| # Take a single image, and remove the color dimension by reshaping for image, label in test_dataset.take(2): break image = image.numpy().reshape((500,500,3))
# Plot the image – voila a piece of fashion clothing plt.figure() plt.imshow(image, cmap=plt.cm.binary) plt.colorbar() plt.grid(False) plt.show() |

2.4 Nadamの最適化アルゴリズムを作成
| # Create Model model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(500, 500, 3)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(3, activation=tf.nn.softmax) ])
model.compile(optimizer=’nadam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
BATCH_SIZE = 32 EPOCHS = 50 train_dataset = train_dataset.cache().repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.cache().batch(EPOCHS)
history = model.fit(train_dataset, epochs=EPOCHS, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
|
Epoch 1/50
33/33 [==============================] – 7s 121ms/step – loss: 234.7843 – accuracy: 0.3399
Epoch 2/50
33/33 [==============================] – 4s 120ms/step – loss: 47.5587 – accuracy: 0.4854
…
Epoch 50/50
33/33 [==============================] – 4s 121ms/step – loss: 1.1075 – accuracy: 0.3497
モデルを確認します。
| model.summary() |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
==============================================
flatten_1 (Flatten) (None, 750000) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 96000128
_________________________________________________________________
dense_3 (Dense) (None, 3) 387
===============================================
Total params: 96,000,515
Trainable params: 96,000,515
Non-trainable params: 0
モデル評価
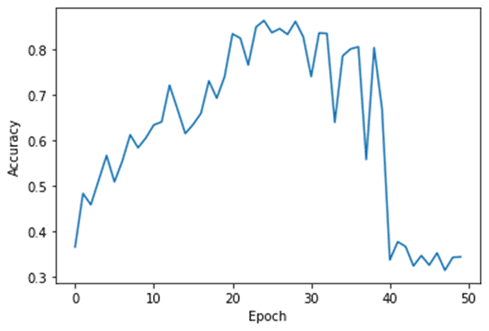
| # Plot loss plt.xlabel(‘Epoch’) plt.ylabel(‘Accuracy’) plt.plot(history.history[‘accuracy’])
|
2.3 Adamの最適化アルゴリズムを作成
Adamの最適化アルゴリズム
| # Create Model model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(500, 500, 3)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(3, activation=tf.nn.softmax) ])
model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
BATCH_SIZE = 32 EPOCHS = 50 train_dataset = train_dataset.cache().repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.cache().batch(EPOCHS)
history = model.fit(train_dataset, epochs=EPOCHS, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE)) |
Epoch 1/50
33/33 [==============================] – 6s 72ms/step – loss: 193.5633 – accuracy: 0.3534
Epoch 2/50
33/33 [==============================] – 2s 73ms/step – loss: 43.2139 – accuracy: 0.5086
…
Epoch 50/50
33/33 [==============================] – 2s 73ms/step – loss: 9.3892 – accuracy: 0.7412
モデル評価
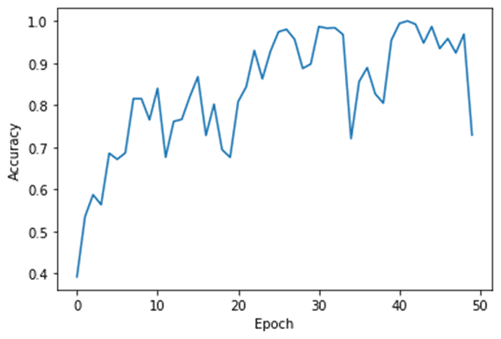
| # Plot loss plt.xlabel(‘Epoch’) plt.ylabel(‘Accuracy’) plt.plot(history.history[‘accuracy’])
|
2.5 まとめ
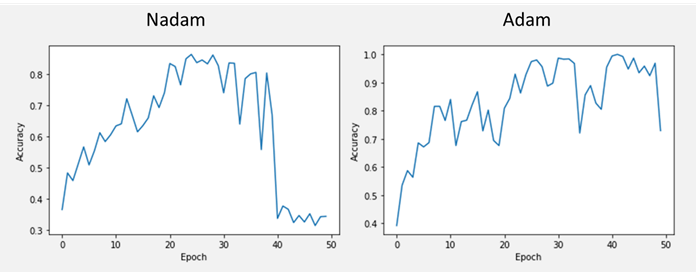
植物の画像のデータセットのNadamの最適化アルゴリズムとAdamのの最適化アルゴリズムのDense多クラス分類ネットワークを実験しました。最初はNadamとAdamはよく学習しました。ただNadamは40 EpochでAccuracyが落として、過学習にしまいました。過学習の対策は下記の記事をご参照ください。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属
Pingback: 深層学習の最適化アルゴリズムまとめ – S-Analysis