
目次
1.TabNetの概要
1.1TabNetとは
1.2TabNetの手法
2.TabNetの実験
2.1環境構築
2.2データセット
2.3 TabNetモデル
2.4XGBoost
3.まとめ
1.TabNetの概要
1.1TabNetとは
TabNetとは、Google Researchで発表された表形式データ向けの新しい深層学習です。TabNetは、シーケンシャルアテンションメカニズムを使用して、各決定ステップで処理する意味がある特徴量を選択します。インスタンスごとの特徴選択により、モデルの容量が最も顕著な特徴に完全に使用されるため、効率的な学習が可能になります。また、選択マスクの視覚化により、より解釈しやすい意思決定が可能になります。TabNetが、さまざまなドメインの表形式のデータセット全体で以前の作業よりも優れていると言われています。
1.2TabNetの手法
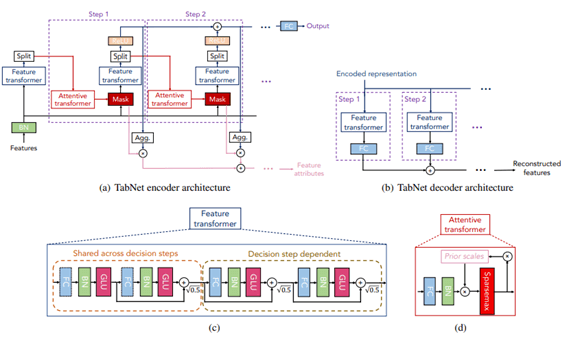
TabNetは、推論のために入力特徴のサブセットを処理することに焦点を当てた複数の決定ブロックを利用しています。
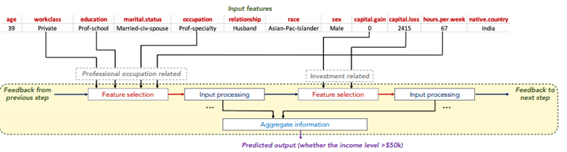
マスクされた自己監視学習による教師なし表現学習は、教師あり学習タスクのエンコーダーモデルを改善します。
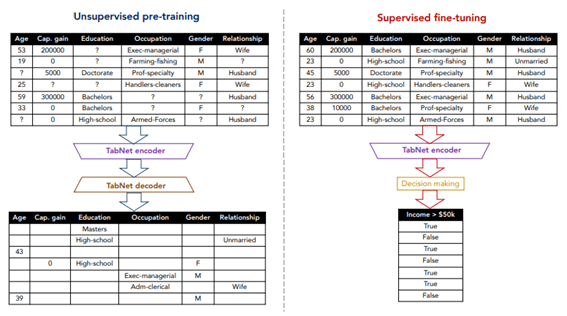
TabNetエンコーダー。機能トランスフォーマー、注意深いトランスフォーマー、および機能マスキングで構成されています。分割ブロックは、処理された表現を分割して、後続のステップの注意深いトランスフォーマーと全体の出力で使用します。各ステップで、特徴選択マスクはモデルの機能に関する解釈可能な情報を提供し、マスクを集約してグローバルな特徴の重要な属性を取得できます。
論文:TabNet: Attentive Interpretable Tabular Learning
https://arxiv.org/abs/1908.07442
Github: google-research/tabnet/
https://github.com/google-research/google-research/tree/master/tabnet
2.TabNetの実験
環境:Google Colab
データセット:frmgham Framingham Studyは、男性と女性の心血管疾患の発症に影響を与える体質的および環境的要因の縦断的調査です。
モデル:TabNet vs XGBoost
モデル評価:Accuracy
2.1環境構築
TabNetのライブラリをインストールします。
| !pip install pytorch-tabnet |
ライブラリのインポート
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
sns.set_style(“white”) |
2.2データセット
データセットをダウンロードします。
| df = pd.read_csv(‘frmgham2.csv’) df.head() |

2.3 TabNetモデル
| from pytorch_tabnet.pretraining import TabNetPretrainer
# TabNetPretrainer unsupervised_model = TabNetPretrainer( optimizer_fn=torch.optim.Adam, optimizer_params=dict(lr=2e-2), mask_type=’entmax’, # “sparsemax”, #n_shared_decoder=1, # nb shared glu for decoding #n_indep_decoder=1, # nb independent glu for decoding ) |
| unsupervised_model.fit( x_train, eval_set=[x_val], max_epochs=1000 , patience=50, batch_size=256, virtual_batch_size=128, num_workers=0, drop_last=False, pretraining_ratio=0.8, ) |
epoch 0 | loss: 5.4957 | val_0_unsup_loss: 1.51399 | 0:00:00s
…
epoch 228| loss: 0.90625 | val_0_unsup_loss: 0.71082 | 0:00:54s
Early stopping occurred at epoch 228 with best_epoch = 178 and best_val_0_unsup_loss = 0.69857
Best weights from best epoch are automatically used!
| # Make reconstruction from a dataset reconstructed_X, embedded_X = unsupervised_model.predict(x_val) assert(reconstructed_X.shape==embedded_X.shape) |
モデルを解説します。
| unsupervised_explain_matrix, unsupervised_masks = unsupervised_model.explain(x_val) fig, axs = plt.subplots(1, 3, figsize=(20,20))
for i in range(3): axs[i].imshow(unsupervised_masks[i][:50]) axs[i].set_title(f”mask {i}”) |

モデルを保存します。
| unsupervised_model.save_model(‘./test_pretrain’) loaded_pretrain = TabNetPretrainer() loaded_pretrain.load_model(‘./test_pretrain.zip’) |
| clf2 = TabNetClassifier(optimizer_fn=torch.optim.Adam, optimizer_params=dict(lr=2e-2), scheduler_params={“step_size”:10, # how to use learning rate scheduler “gamma”:0.9}, scheduler_fn=torch.optim.lr_scheduler.StepLR, mask_type=’sparsemax’ # This will be overwritten if using pretrain model )
clf2.fit( x_train, y_train, eval_set=[(x_train, y_train), (x_val, y_val)], eval_name=[‘train’, ‘valid’], eval_metric=[‘auc’, ‘accuracy’], max_epochs=1000 , patience=50, batch_size=256, virtual_batch_size=128, num_workers=0, weights=1, drop_last=False, from_unsupervised=loaded_pretrain ) |
epoch 0 | loss: 0.67844 | train_auc: 0.71025 | train_accuracy: 0.56918 | valid_auc: 0.73169 | valid_accuracy: 0.57669 | 0:00:00s
…
epoch 80 | loss: 0.27868 | train_auc: 0.95902 | train_accuracy: 0.88573 | valid_auc: 0.723 | valid_accuracy: 0.77301 | 0:00:20s
Early stopping occurred at epoch 80 with best_epoch = 30 and best_valid_accuracy = 0.80982
Best weights from best epoch are automatically used!
| # plot accuracy plt.plot(clf2.history[‘train_accuracy’]) plt.plot(clf2.history[‘valid_accuracy’]) |
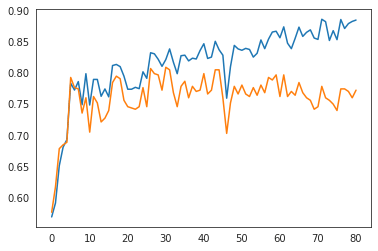
モデルの精度
| preds = clf2.predict_proba(x_test) test_auc = roc_auc_score(y_score=preds[:,1], y_true=y_test)
preds_valid = clf2.predict_proba(x_val) valid_auc = roc_auc_score(y_score=preds_valid[:,1], y_true=y_val)
print(f”BEST VALID SCORE FOR THIS DATASET : {clf2.best_cost}”) print(f”FINAL TEST SCORE FOR THIS DATASET : {test_auc}”) |
BEST VALID SCORE FOR THIS DATASET : 0.8098159509202454
FINAL TEST SCORE FOR THIS DATASET : 0.8072926274365123
モデルを開設します。
| explain_matrix, masks = clf2.explain(x_test)
fig, axs = plt.subplots(1, 3, figsize=(20,20))
for i in range(3): axs[i].imshow(masks[i][:50]) axs[i].set_title(f”mask {i}”) |

2.4XGBoost
XGBoostのモデルを作成しまs。
| from xgboost import XGBClassifier
clf_xgb = XGBClassifier(max_depth=8, learning_rate=0.1, n_estimators=1000, verbosity=0, silent=None, objective=’binary:logistic’, booster=’gbtree’, n_jobs=-1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=0.7, colsample_bytree=1, colsample_bylevel=1, colsample_bynode=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None,)
clf_xgb.fit(x_train, y_train, eval_set=[(x_val, y_val)], early_stopping_rounds=40, verbose=10) |
モデル評価
| preds = clf_xgb.predict(x_test) test_acc = accuracy_score(preds, y_test)
preds_valid = clf_xgb.predict(x_val) valid_acc = accuracy_score(preds_valid, y_val)
print(f”BEST ACCURACY SCORE ON VALIDATION SET : {valid_acc}”) print(f”BEST ACCURACY SCORE ON TEST SET : {test_acc}”) |
BEST ACCURACY SCORE ON VALIDATION SET : 0.7832310838445807
BEST ACCURACY SCORE ON TEST SET : 0.7326530612244898
3.まとめ
TabNetとXGBoostのモデルを作成しました。XGBoost に比べて、TabNetはよりよい精度のモデルができ、解釈可能なモデルでした。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト