
目次
1 Autovizの概要
1.1 Autovizとは
1.2 Autovizのライブラリ
2. 実験
2.1 データロード
2.2 Autovizの探索的データ解析のEDA
3 まとめ
1 Autovizの概要
1.1 Autovizとは
Autovizはデータセットを自動可視化するライブラリです。データのファイルタイプとしては、Pandasのデータフレーム、CSV、 txt、 json等のファイルから1行のコードで自動可視化できます。
1.2 Autovizのライブラリ
AutoViz(filename, sep, depVar, dfte, header, verbose, lowess, chart_format¸ max_rows_analyzed, max_cols_analyzed)
AutovizのAPI:
filename- ファイル名を入力し、データフレームを使用する場合は、filenameを空の文字列(””)として指定します。
sep- ファイル内の区切り文字です。
depVar- データセット内のターゲット変数
dfte- パンダのデータフレーム
header- ファイル内のヘッダー行の行番号
verbose- 0、1、または2の3つの許容値があります。
lowess- ターゲット変数に対する連続変数の各ペアの回帰直線の設定。小さなデータセットに非常に適しています。
chart_format- SVG、PNG、またはJPGに設定することができます。
max_rows_analyzed- チャートの表示に使用される行の最大数を制限します。
max_cols_analyzed- 分析できる連続変数の数を制限します。
Github:
https://github.com/AutoViML/AutoViz
2. 実験
環境:Google Colab
データセット:ボストン住宅価格データセット(13つの説明変数と1つの目的変数)
ライブラリのインストール
| !pip install autoviz |
ライブラリのインポート
| import pandas as pd %matplotlib inline |
2.1 データロード
csvファイルを読み込んで、データフレームを作成します。
| sep = ‘,’ target = ‘medv’ datapath = ” filename = ‘https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/MASS/Boston.csv’ df = pd.read_csv(datapath+filename,sep=sep,index_col=None) df = df.sample(frac=1.0,random_state=42) print(df.shape) df.head(1) |

2.2 Autovizの探索的データ解析のEDA
| from autoviz.AutoViz_Class import AutoViz_Class %matplotlib inline AV = AutoViz_Class() |
| dft = AV.AutoViz(datapath+filename, sep=sep, depVar=target, dfte=df, header=0, verbose=2, lowess=False,chart_format=’svg’,max_rows_analyzed=1500,max_cols_analyzed=30) |
データのサマリー
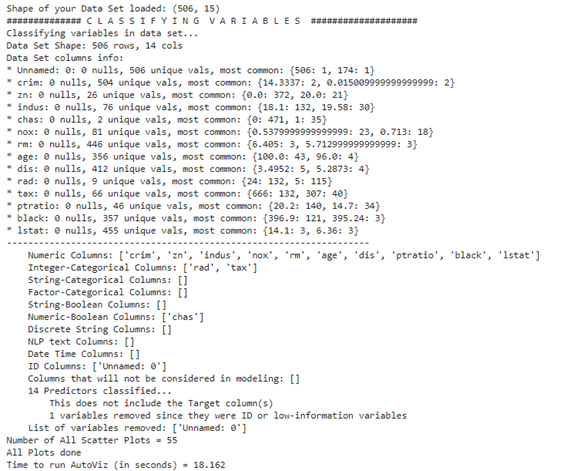
連続説明変数と目的変数の散布図
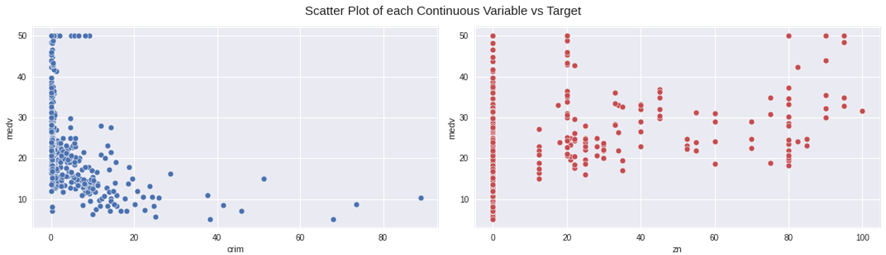
各連続説明変数の散布図
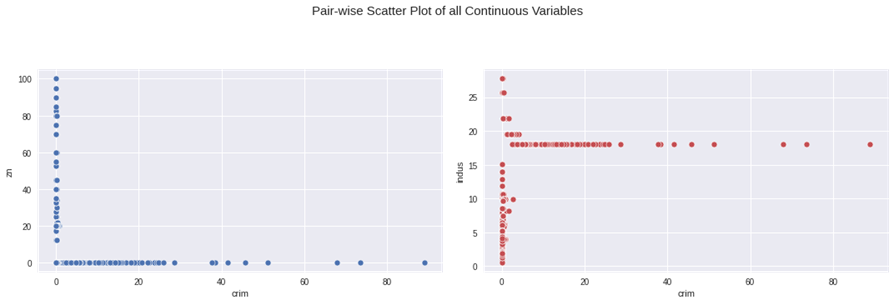
データ分配
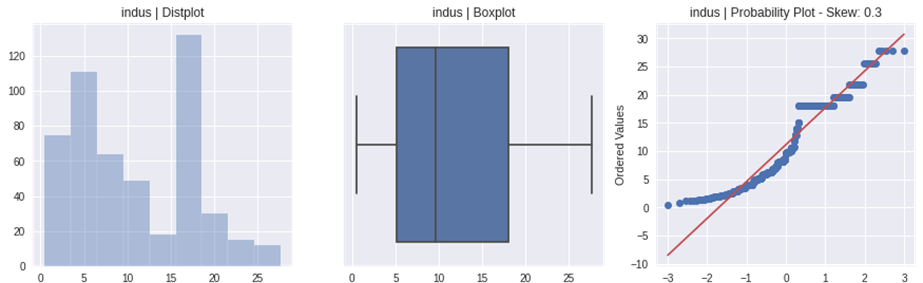
連続説明変数のヒストグラム
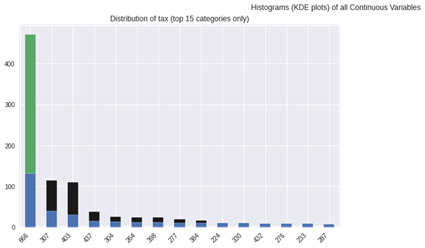
連続説明変数のバイオリン図

連続説明変数のヒートマップ
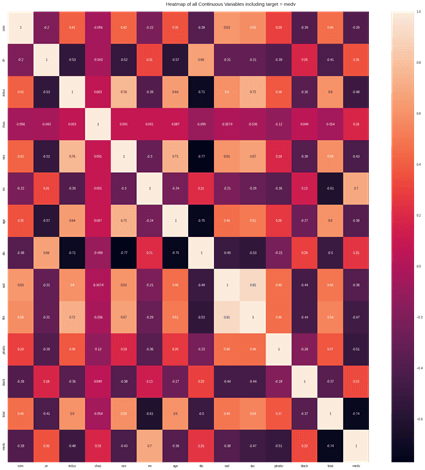
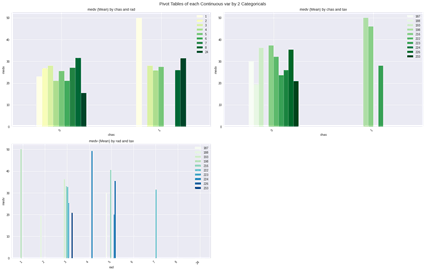
連続説明変数のピボットテーブル
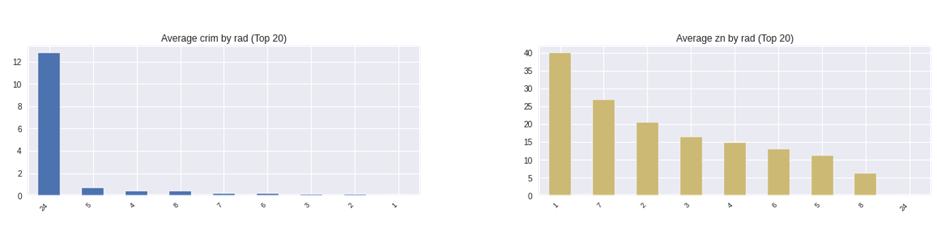
連続説明変数の棒グラフ
3 まとめ
Autovizの自動可視化するライブラリを実験しました。数行のコードで、散布図、ヒストグラム図、バイオリン図、棒グラフを作成することができました。使いやすい可視化のライブラリだと思います。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属