
目次
1 NOVOGRAUD最適化アルゴリズムの概要
1.1 NOVOGRAUD最適化アルゴリズムとは
1.2 NOVOGRAUD定義
2. 実験
2.1 データロード
2.2 データ前処理
2.3 NOVOGRAUD最適化アルゴリズムのモデル作成
2.4 Adam最適化アルゴリズムのモデル作成
2.5 まとめ
1 NOVOGRAUD最適化アルゴリズムの概要
1.1 NOVOGRAUD最適化アルゴリズムとは、層ごとの勾配正規化と分離された重み減衰を使用した適応確率的勾配降下法です。論文より、画像分類、音声認識、機械翻訳、言語モデリングのためのニューラルネットワークの実験では、SGD、Adam、AdamWと同等かそれ以上のパフォーマンスの結果になりました。今回私達も評価とサンプルコードを紹介していきます。
NOVOGRAUDの特徴:
- 学習率と重みの初期化の選択に適しています
- 大規模なバッチ設定でうまく対応できます。
- Adamに対しての半分のメモリフットプリントになります。
アルゴリズム:
NovoGradは3つのアイデアを組み合わせています。
- 層ごとの2次モーメントを使用します。
- 層ごとの2次モーメントで正規化された勾配を使用して1次モーメントを計算します
- 重量減衰を切り離します。

論文:Training Deep Networks with Stochastic Gradient Normalized by Layerwise
Adaptive Second Moments
https://arxiv.org/pdf/1905.11286.pdf
Tensorflow:
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/NovoGrad?hl=ja
PyTorch:
https://pytorch-optimizer.readthedocs.io/en/latest/_modules/torch_optimizer/novograd.html
2. 実験
データセット:cifar10: 60000枚の32ピクセルx32ピクセルの画像。10クラス([0] airplane (飛行機)、[1] automobile (自動車)、[2] bird (鳥)、[3] cat (猫)、[4] deer (鹿)、[5] dog (犬)、[6] frog (カエル)、[7] horse (馬)、[8] ship (船)、[9] truck (トラック))
モデル:CNN Ranger最適化アルゴリズム(TensorFlowアドオン)vs CNN Adam最適化アルゴリズム
| !pip install tensorflow-addons |
ライブラリのインポート
| import tensorflow as tf import tensorflow_addons as tfa from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.1 データロード
keras.datasetsからcifar10のデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
サンプル画像データを表示します。
| # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |

2.2 データ前処理
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.3 NOVOGRAUD最適化アルゴリズム
| NOVOGRAUD =tfa.optimizers.NOVOGRAUD( learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, epsilon = 1e-06, weight_decay_rate = 0.0, exclude_from_weight_decay = None, exclude_from_layer_adaptation = None, name = ‘NOVOGRAUD’, ) |
NOVOGRAUD最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’))
model.compile(optimizer=NOVOGRAUD, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 48s 6ms/step – loss: 2.1823 – accuracy: 0.2001 – val_loss: 1.7953 – val_accuracy: 0.3593
…
Epoch 50/50
500/500 [==============================] – 3s 5ms/step – loss: 0.6084 – accuracy: 0.7908 – val_loss: 0.9479 – val_accuracy: 0.6949
モデル評価
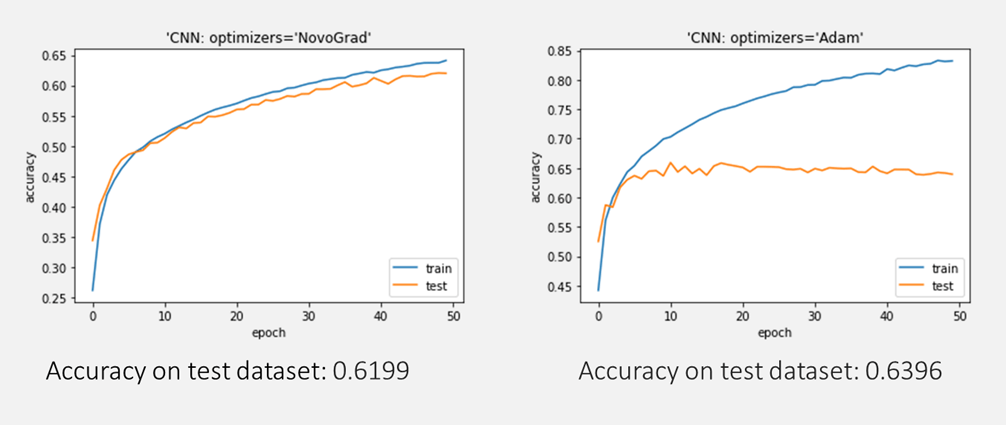
NOVOGRAUDの最適化アルゴリズムは良い結果になります。
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=’NOVOGRAUD'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
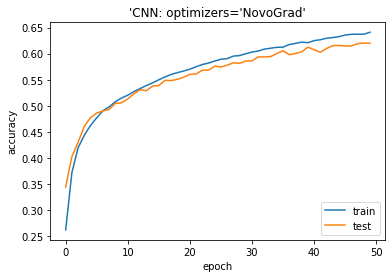
| from sklearn.metrics import accuracy_score import numpy as np
y_pred_p = model.predict(X_test) y_pred = np.argmax(y_pred_p,axis=1) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6199
2.4 Adam最適化アルゴリズムのモデル作成
Adam最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’selu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’selu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_2”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 3s 5ms/step – loss: 1.7548 – accuracy: 0.3765 – val_loss: 1.3548 – val_accuracy: 0.5202
…
Epoch 50/50
500/500 [==============================] – 2s 5ms/step – loss: 0.4620 – accuracy: 0.8419 – val_loss: 1.3445 – val_accuracy: 0.6396
モデル評価
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=Adam'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |

| y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6396
2.5 まとめ
cifar10データセットでNOVOGRAUD最適化アルゴリズムのCNNモデルとAdam最適化アルゴリズムのCNNモデルを作成しました。Adamに比べて、NOVOGRAUDは安定に学習しました。しかし収束がやや遅くEpoch50ではまだまだって感じの様でした。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト