
目次
1. 最適化アルゴリズムとは
2. 最適化アルゴリズムのまとめ
・確率的勾配降下法(SGD)
・Adams
・Adamax
・Nadam
・AMSGrad
・AdamW
3.その他
AdaDelta, AdaGrad, A2GradExp, A2GradInc, A2GradUni, AccSGD, AdaBelief, AdaMod, Adafactor, Adahessian, AdamP, AggMo, Apollo, DiffGrad, RMSProp, AveragedOptimizerWrapper, ConditionalGradient, CyclicalLearningRate, ExponentialCyclicalLearningRate, extend_with_decoupled_weight_decay, LAMB, LazyAdam, Lookahead, MovingAverage, NovoGrad, ProximalAdagrad, RectifiedAdam, SGDW, SWA, Triangular2CyclicalLearningRate, TriangularCyclicalLearningRate, Yogi, AdaBound, AMSBound, Shampoo, SWATS, SGDP, Ranger, RangerQH, RangerVA, PID, QHAdam, QHM, COCOB
1 最適化アルゴリズムとは
最適化アルゴリズム(Optimizer algorithm)とは、損失を最小限に抑えるアルゴリズムです。深層学習には、最初に損失関数することです。 最急降下法の派生で、最急降下法さえ理解すれば他の最適化アルゴリズムです。
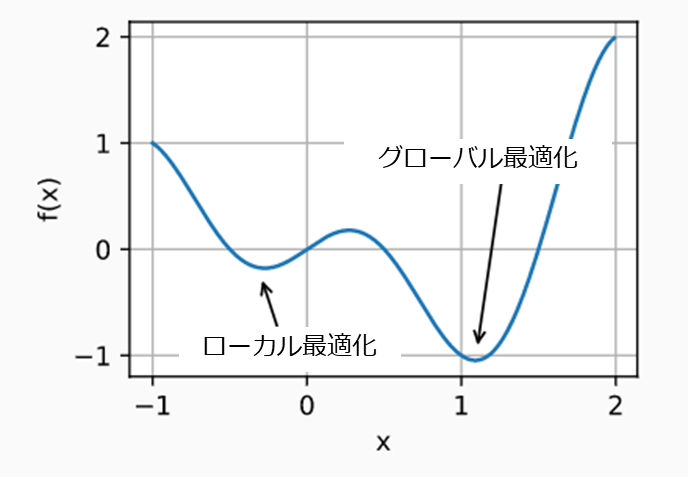
下記の図は複数の最適化アルゴリズムの損失を最小限の計算を表示します。
この記事は最適化アルゴリズムを解説します。

https://developer.nvidia.com/blog/deep-learning-nutshell-history-training/
ローカル最適化(local optimization) とグローバル最適化(global optimization)
最適化の計算においてはローカルの最小値を求めても、それが可能な範囲内においての最小の値とは限りません。ローカルの最小値で満足できない場合にはグローバルの最小値を見つける必要がありますが、これにはより多くの計算量が必要となります。
2. 最適化手法のまとめ
確率的勾配降下法は Stochastic Gradient Descent(SGD)
目的関数は通常、トレーニングデータセットの各例の損失関数の平均です。
目的関数式:
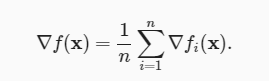
fi(x)は、n個の説明変数、iのインデックス、およびxのパラメーターベクトルを含むトレーニングデータセットの損失関数です。学習率(learning rates)は、最適な解決策を見つけるための補助です。
トレーニングデータセットにさらに多くになる場合、勾配降下法の各イテレーションを計算するためにより多くの計算量かがかかるため、これらの場合にはSGDを利用します。
Tensorflow:
https://www.tensorflow.org/swift/api_docs/Classes/SGD
Adams
AdamsはAdaptive Moment Estimation の略称で、各パラメーターの変化率を計算するアルゴリズムです。momentumと同じように、過去の二乗勾配の指数関数的に減衰する平均を保存し、過去の勾配の指数関数的に減衰する平均を保持します。momentumは斜面を走るボールとして見ることができますが、Adamは摩擦のある重いボールのように振る舞うため、エラーサーフェスでフラットな最小値を優先します。そのためローカルな局所解に陥りやすいことがわかっています。
過去と過去の二乗勾配mtとvtの減衰平均をそれぞれ次のように計算します。
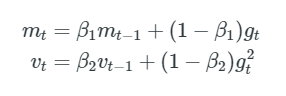
それらは、バイアス補正された一次および二次モーメントの推定値を計算することにより、これらのバイアスを打ち消します。
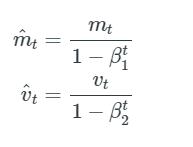
これらを使用してパラメーターを更新します。これにより、Adam更新ルールが生成されます。

Adamsが実際にうまく機能し、他の適応学習法アルゴリズムと比べて遜色がないことを経験的に示しています。
Tensorflow:
https://www.tensorflow.org/swift/api_docs/Classes/Adam
Adamax
Adam更新ルールのvt係数は、過去の勾配(vt-1項を介して)と現在の勾配のℓ2ノルムに反比例して勾配をスケーリングします。この更新をℓpノルムに一般化できます。 KingmaとBaもパラメータ化することです。

これをAdamの更新式に組み込むことができます。
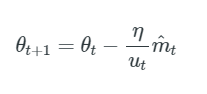
Tensorflow:
https://www.tensorflow.org/swift/api_docs/Classes/AdaMax
Nadam
Nadam (Nesterov-accelerated Adaptive Moment Estimation)はAdamとNAGを組み合わせます。
これで、前のタイムステップmt-1の運動量ベクトルのこのバイアス補正された推定値を置き換えるだけで、以前と同じようにネステロフ運動量を追加できます。
現在の運動量ベクトルmtのバイアス補正された推定値を使用して、Nadam更新ルールを取得します。

Tensorflow:
https://www.tensorflow.org/swift/api_docs/Classes/RAdam
AMSGrad
適応学習率法がニューラルネットワークのトレーニングの標準になっているため、開業医は、場合によっては、 オブジェクト認識または機械翻訳の場合、それらは最適解に収束できず、勢いのあるSGDよりも優れています。
指数平均ではなく過去の二乗勾配vtの最大値を使用してパラメーターを更新するAMSGrad。 vtはAdamと同じように定義されています
AMSGradの結果、ステップサイズが大きくならず、Adamが抱える問題を回避できます。 簡単にするために、著者は、Adamで見たバイアス除去ステップも削除します。
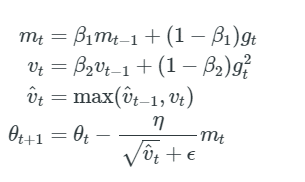
Tensorflow:
https://www.tensorflow.org/swift/api_docs/Classes/AMSGrad
AdamW(Adaptive Moment Estimation with Weight decay)
重みの減衰は、重みの値を小さく保とうとするニューラルネットワークをトレーニングする手法です。 直感的には、ウェイトが大きいとオーバーフィットする傾向があり、ウェイトを大きくするのには十分な理由が必要です。 これは通常、重みの値の関数である損失関数に項を追加することによって実装されます。このように、重みが大きいと、総損失が大幅に増加します。
特に、AdamのL2正則化は通常、以下の変更を加えて実装されます。ここで、wtは時間tでの重量減衰率です。
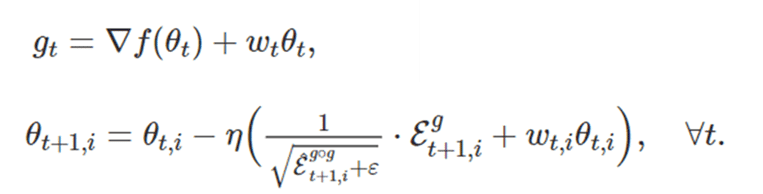
Tensorflow:
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/AdamW
3. その他
AdaDelta
論文:ADADELTA: An Adaptive Learning Rate Method
https://www.tensorflow.org/swift/api_docs/Classes/AdaDelta
https://pytorch.org/docs/stable/optim.html
AdaGrad
https://www.tensorflow.org/swift/api_docs/Classes/AdaGrad
A2GradExp
https://arxiv.org/abs/1810.00553
A2GradInc
https://arxiv.org/abs/1810.00553
A2GradUni
https://arxiv.org/abs/1810.00553
AccSGD
https://arxiv.org/abs/1803.05591
AdaBelief
https://arxiv.org/abs/2010.07468
AdaMod
https://arxiv.org/abs/1910.12249
Adafactor
https://arxiv.org/abs/1804.04235
Adahessian
https://arxiv.org/abs/2006.00719
AdamP
https://arxiv.org/abs/2006.08217
AggMo
https://arxiv.org/abs/1804.00325
Apollo
https://arxiv.org/abs/2009.13586
AdaBound
https://github.com/Luolc/AdaBound
https://data-analysis-stats.jp/tag/adabound/?amp
AMSBound
https://paperswithcode.com/method/amsbound
DiffGrad
https://arxiv.org/abs/1909.11015
RMSProp
https://www.tensorflow.org/swift/api_docs/Classes/RMSProp
AveragedOptimizerWrapper
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/AveragedOptimizerWrapper
ConditionalGradient
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/ConditionalGradient
CyclicalLearningRate
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/CyclicalLearningRate
ExponentialCyclicalLearningRate
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/ExponentialCyclicalLearningRate
extend_with_decoupled_weight_decay
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/extend_with_decoupled_weight_decay
LAMB
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/LAMB
LazyAdam
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/LazyAdam
Lookahead
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/Lookahead
MovingAverage
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/MovingAverage
NovoGrad
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/NovoGrad
ProximalAdagrad
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/ProximalAdagrad
RectifiedAdam
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/RectifiedAdam
SGDW
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/SGDW
SWA
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/SWA
Triangular2CyclicalLearningRate
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/Triangular2CyclicalLearningRate
TriangularCyclicalLearningRate
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/TriangularCyclicalLearningRate
Yogi
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/Yogi
https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization
Shampoo
https://arxiv.org/abs/1802.09568
SWATS
https://arxiv.org/abs/1712.07628
SGDP
https://arxiv.org/abs/2006.08217
Ranger
記事:Rangerの最適化アルゴリズムの解説 LINK
RangerQH
https://arxiv.org/abs/1810.06801
RangerVA
https://arxiv.org/abs/1908.00700v2
PID
https://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf
QHAdam
https://arxiv.org/abs/1810.06801
COCOB
Tensorflow:COCOB
論文:https://arxiv.org/abs/1705.07795
QHM
https://arxiv.org/abs/1810.06801

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属