
目次
1 ADABELIEF最適化アルゴリズムの概要
1.1 ADABELIEF最適化アルゴリズムとは
1.2 ADABELIEF定義
2. 実験
2.1 データロード
2.2 データ前処理
2.3 ADABELIEF最適化アルゴリズムのモデル作成
2.4 Adam最適化アルゴリズムのモデル作成
2.5 まとめ
1 ADABELIEF最適化アルゴリズムの概要
1.1 ADABELIEF最適化アルゴリズムとは、アダムとSGDに匹敵する一般化として高速収束を実現します。 勾配方向の「信念」に応じてステップサイズを適応させます。予測された勾配と観測された勾配の差によってステップサイズを適応的にスケーリングします。
AdaBeliefの直感は、現在の勾配方向の「信念」に従ってステップサイズを適応させることです。 ノイズの多い勾配の指数移動平均(EMA)を次のタイムステップでの勾配の予測として表示し、観測された勾配が予測から大幅に逸脱している場合、現在の観測を信用せず、小さなステップを実行します。 観測された勾配が予測に近い場合、それを信頼し、大きな更新をおこなっていきます。
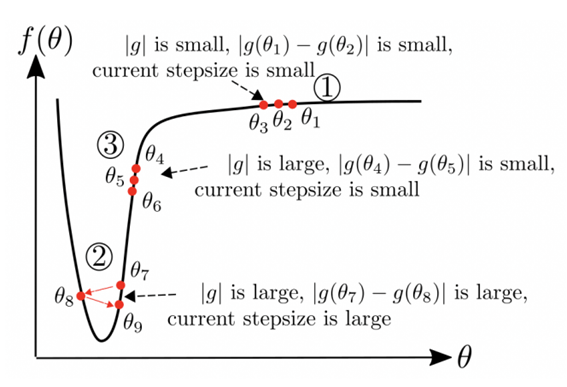
ADABELIEFの特徴:
1)アダプティブメソッドのように高速コンバージェンス
2)SGDのように良い一般化
3)トレーニングの安定性
AdamとAdaBeliefの計算の比較:
違いは青色になります。

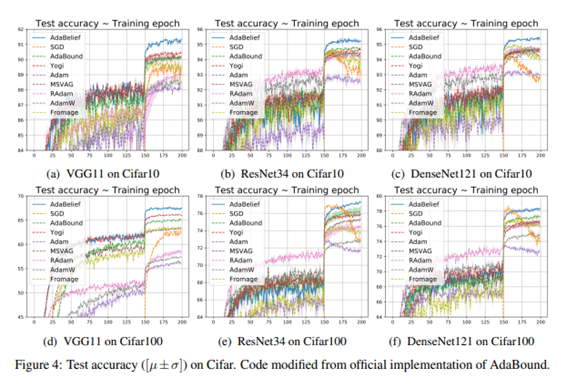
Cifar10に対して、複数モデルと最適化アルゴリズムの結果
AdaBelief は確かに論文中では良い結果が得られています。
論文:
https://arxiv.org/abs/2010.07468
Tensorflow:
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/AdaBelief
PyTorch:
https://github.com/juntang-zhuang/Adabelief-Optimizer
2. 実験
データセット:cifar10: 60000枚の32ピクセルx32ピクセルの画像。10クラス([0] airplane (飛行機)、[1] automobile (自動車)、[2] bird (鳥)、[3] cat (猫)、[4] deer (鹿)、[5] dog (犬)、[6] frog (カエル)、[7] horse (馬)、[8] ship (船)、[9] truck (トラック))
モデル:CNN Ranger最適化アルゴリズム(TensorFlowアドオン)vs CNN Adam最適化アルゴリズム
| !pip install tensorflow-addons |
ライブラリのインポート
| import tensorflow as tf import tensorflow_addons as tfa from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.1 データロード
keras.datasetsからcifar10のデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
サンプル画像データを表示します。
| # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |

2.2 データ前処理
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.3 ADABELIEF最適化アルゴリズム
| ADABELIEF = tfa.optimizers.AdaBelief(lr=1e-3) |
ADABELIEF最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’))
model.compile(optimizer=ADABELIEF, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 48s 6ms/step – loss: 2.1823 – accuracy: 0.2001 – val_loss: 1.7953 – val_accuracy: 0.3593
…
Epoch 50/50
500/500 [==============================] – 3s 5ms/step – loss: 0.6084 – accuracy: 0.7908 – val_loss: 0.9479 – val_accuracy: 0.6949
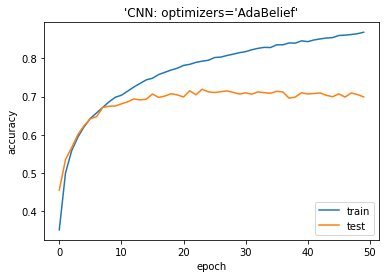
モデル評価
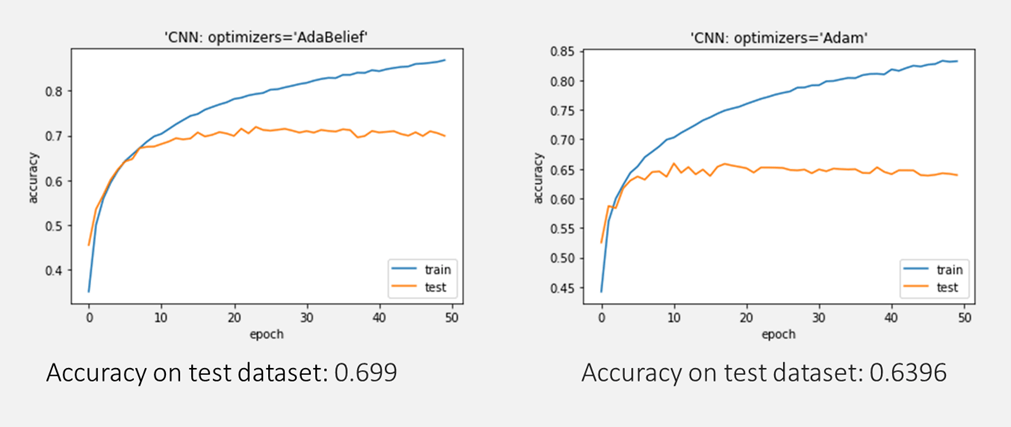
ADABELIEFの最適化アルゴリズムは良い結果になります。
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=’ADABELIEF'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
| from sklearn.metrics import accuracy_score import numpy as np
y_pred_p = model.predict(X_test) y_pred = np.argmax(y_pred_p,axis=1) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.699
2.4 Adam最適化アルゴリズムのモデル作成
Adam最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’selu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’selu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_2”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test))
|
Epoch 1/50
500/500 [==============================] – 3s 5ms/step – loss: 1.7548 – accuracy: 0.3765 – val_loss: 1.3548 – val_accuracy: 0.5202
…
Epoch 50/50
500/500 [==============================] – 2s 5ms/step – loss: 0.4620 – accuracy: 0.8419 – val_loss: 1.3445 – val_accuracy: 0.6396
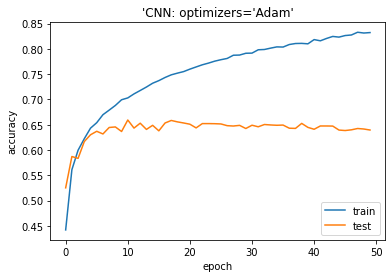
モデル評価
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=Adam'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show()
y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
| y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score)
|
Accuracy on test dataset: 0.6396
2.5 まとめ
cifar10データセットでADABELIEF最適化アルゴリズムのCNNモデルとAdam最適化アルゴリズムのCNNモデルを作成しました。Adamに比べて、ADABELIEFは良い結果になりました。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属