
目次
1. Mlxtendの概要
1.1 Mlxtendとは
1.2 頻繁なパターンのモジュール
1.3 mlxtendのインストール
2. Apriori
2.1 Aprioriのアルゴリズム
2.2 Aprioriの実験
3. 相関ルール
2.1 Association Rulesのアルゴリズム
2.2 Association Rulesの実験
関連記事:
協調フィルタリング(Collaborative filtering)レコメンドエンジン
レコメンドのランキングの評価指標 (PR曲線とAUC, MRR, MAP, nDCG)
1. Mlxtendの概要
1.1 Mlxtendとは
Mlxtendは machine learning extensionsの英語略称で、データサイエンティストの作業のライブラリです。サンプルデータ、前処理、モデル作成、モデル評価、可視化などのモジュールを提供しています。今回はfrequent_patternsのモジュールを解説したいと思います。
Mlxtendのモジュール:http://rasbt.github.io/mlxtend/USER_GUIDE_INDEX/
Mlxtendのgithub:https://github.com/rasbt/mlxtend
1.2 頻繁なパターンのモジュール
頻繁なパターン(frequent_patterns)のモジュールはapriori、association_rules、fpgrowth、fpmaxがあります。一緒に何が変われるかというパターンを理解するために、アソシエーション分析のアルゴリズムのモジュールです。
1.3 mlxtendのインストール
Colabの環境で、mlxtendを更新します。
| !pip install mlxtend –upgrade import mlxtend mlxtend.__version__ |
0.19.0
2. Apriori
2.1 Aprioriのアルゴリズム
Aprioriは、相関ルール学習のために頻繁なアイテムセットを抽出するための一般的なアルゴリズムです。店舗の顧客による購入などのトランザクションを含むデータベースで動作するように設計されています。 アイテムセットは、ユーザー指定のサポートしきい値を超える場合、「頻繁」にします。 たとえば、サポートしきい値が0.5(50%)に設定されている場合、頻繁なアイテムセットは、データベース内のすべてのトランザクションの少なくとも50%で一緒に買うアイテムのセットとして定義されます。
2.2 Aprioriの実験
データ作成
| dataset = [[‘Milk’, ‘Onion’, ‘Nutmeg’, ‘Kidney Beans’, ‘Eggs’, ‘Yogurt’], [‘Dill’, ‘Onion’, ‘Nutmeg’, ‘Kidney Beans’, ‘Eggs’, ‘Yogurt’], [‘Milk’, ‘Apple’, ‘Kidney Beans’, ‘Eggs’], [‘Milk’, ‘Unicorn’, ‘Corn’, ‘Kidney Beans’, ‘Yogurt’], [‘Corn’, ‘Onion’, ‘Onion’, ‘Kidney Beans’, ‘Ice cream’, ‘Eggs’]] |
前処理
| import pandas as pd from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder() te_ary = te.fit(dataset).transform(dataset) df = pd.DataFrame(te_ary, columns=te.columns_) df |
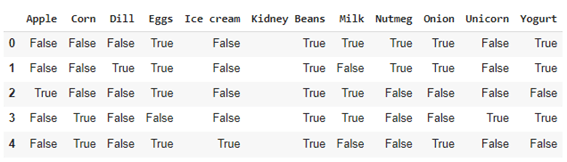
Aprioriアルコール
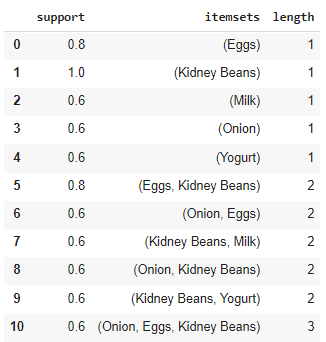
| from mlxtend.frequent_patterns import apriori
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True) frequent_itemsets[‘length’] = frequent_itemsets[‘itemsets’].apply(lambda x: len(x)) frequent_itemsets |
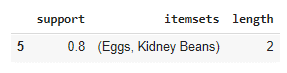
サポートしきい値が0.7にして、頻繁なアイテムセットを出します。
| frequent_itemsets[ (frequent_itemsets[‘length’] == 2) & (frequent_itemsets[‘support’] >= 0.7) ] |
3. 相関ルール
2.1 相関ルールのアルゴリズム
相関ルールは、頻繁なパターンのマイニングにおける一般的なタスクです。 相関ルールは、X→Yの形式の含意式です。ここで、XとYは互いに素なアイテムセットです[1]。 消費者行動に基づくより具体的な例は、{おむつ}→{ビール}であり、おむつを購入する人はビールも購入する可能性が高いことを示唆しています。 このような相関ルールの「関心」を評価するために、信頼度とリフトの指標などを作成できます。
支持度(support)
支持度とは、全体の中で、AとCが同時に買われる確率です。
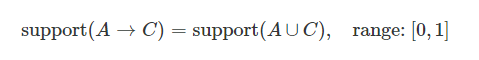
確信度(confidence)
信頼度とは、(A⇒C)とすると、Aが買われた中で、Cが買われた確率です。
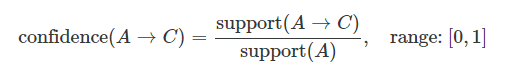
リフト(lift)
リフト値とは、Aと一緒にCも購入した人の割合(信頼度(A⇒C))は、全てのデータの中でCを購入した人の割合よりどれだけ多いかを倍率で示したものです。
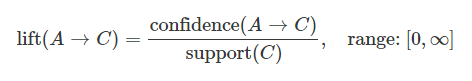
影響度(leverage)
影響度とは、Aと一緒にCも購入した人の割合、AとCが独立している場合に予想される頻度との差を計算します。
![]()
![]()
確信度(conviction)
確信度は逆リフト値の反対で、前提のサポートと結論以外のサポートの積を、ルール「前提→結論以外」のサポートで割った値です。前提をA、結論をCとし、結論以外の事象を B’としたと場合です。

2.2 Association Rulesの実験
データ前処理
| import pandas as pd from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth
te = TransactionEncoder() te_ary = te.fit(dataset).transform(dataset) df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = fpgrowth(df, min_support=0.6, use_colnames=True)
frequent_itemsets |
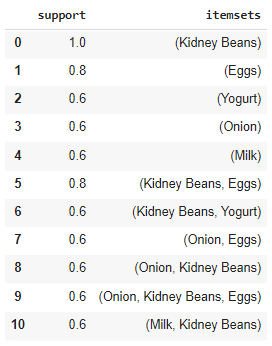
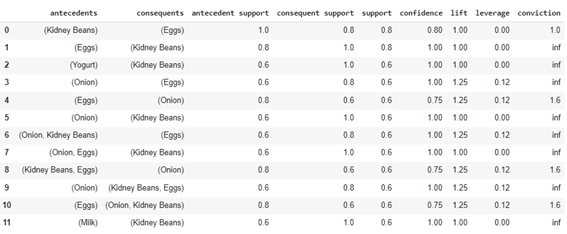
相関ルールを作成します。支持度(support)、確信度(confidence)、リフト(lift)、影響度(leverage)、確信度(conviction)を計算されました。
| from mlxtend.frequent_patterns import association_rules association_rules(frequent_itemsets, metric=”confidence”, min_threshold=0.7) |
antecedent_len >= 2、confidence > 0.75、lift > 1.2]のルールで、セットを出します。
| rules = association_rules(frequent_itemsets, metric=”lift”, min_threshold=0.7)
rules[“antecedent_len”] = rules[“antecedents”].apply(lambda x: len(x))
rules[ (rules[‘antecedent_len’] >= 2) & (rules[‘confidence’] > 0.75) & (rules[‘lift’] > 1.2) ] |
![]()
![]()

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属