
目次
1. 協調フィルタリングの概要
_1.1 協調フィルタリング(Collaborative Filtering)とは
_1.2 協調フィルタリングの長所・短所
2. 実験:
_2.1 環境設定
_2.2 データロード
_2.3 データ確認
_2.4 モデル作成
_2.5 レコメンドエンジンで距離計算
_2.6 入力したデータからレコメンドエンジン利用
1. 協調フィルタリングの概要
前回はTensorFlowでのレコメンダー【tensorflow-recommenders (TFRS)】を話しました。レコメンドエンジンは複数アルゴリズムがあります。今回の記事は協調フィルタリング(Collaborative filtering)を解説したいと思います。例えば、Google Playでのアプリのインストールの40%は、推奨事項によるものです。YouTubeの総再生時間の60%は、おすすめによるものです。レコメンドエンジンは非常に大切なことです。
1.1 協調フィルタリング(Collaborative Filtering)とは
協調フィルタリング(Collaborative Filtering、CF)は、多くのユーザの過去の行動履歴と嗜好情報を蓄積し、あるユーザの行動履歴から嗜好を推論するレコメンドエンジンです。

Items:システムが推奨するエンティティ。 Google Playストアの場合、Itemsはインストールするアプリです。
Query:システムが推奨を行うために使用する情報。 クエリは、次の組み合わせにすることができます。
Embedding:離散セット(この場合は、クエリのセット、または推奨するアイテムのセット)から埋め込みスペースと呼ばれるベクトル空間へのマッピングであり、次元削減した結果です。 通常、埋め込みスペースは低次元です。
Similarity Measures:類似性は、二つのユーザーやアイテムのペアを取得し、それらの類似性を測定する値を返す関数です。
距離と類似度の解説の詳細はこちらです。
1.2 協調フィルタリングの長所・短所
長所
・ドメイン知識は必要ありません。
・セレンディピティ:このモデルは、ユーザーが新しい興味を発見するのに役立ちます。
・優れた出発点:ある程度、システムは行列因数分解モデルをトレーニングするためにフィードバック行列のみを必要とします。
短所
・新しいアイテムを処理できません(コールドスタートの問題)。WALSおよびHeuristicsの手法が必要です。
・クエリ/アイテムのサイド機能(クエリまたはアイテムID以外の機能)を含めるのは難しいです。
2. 実験
環境:google colab
データセット:MovieLens 100K Dataset
ミネソタ大学のユーザが好きに映画の情報を眺めたり評価するデータセット
MovieLens 100K Dataset
1700本の映画で1000人のユーザーから100,000件の評価。 1998年リリース。
詳細:http://grouplens.org/datasets/movielens/
モデル: 協調フィルタリングのレコメンドエンジン
2.1 環境設定
ライブラリインストールとライブラリインポート
| from __future__ import print_function
import numpy as np import pandas as pd import collections from mpl_toolkits.mplot3d import Axes3D from IPython import display from matplotlib import pyplot as plt import sklearn import sklearn.manifold import tensorflow.compat.v1 as tf tf.disable_v2_behavior() tf.logging.set_verbosity(tf.logging.ERROR)
# PandasDataFrameにいくつかの便利な関数を追加します。pd.options.display.max_rows = 10 pd.options.display.float_format = ‘{:.3f}’.format def mask(df, key, function): “””Returns a filtered dataframe, by applying function to key””” return df[function(df[key])]
def flatten_cols(df): df.columns = [‘ ‘.join(col).strip() for col in df.columns.values] return df
pd.DataFrame.mask = mask pd.DataFrame.flatten_cols = flatten_cols
# Altairをインストールし、そのcolabレンダラーをアクティブにします。 print(“Installing Altair…”) !pip install git+git://github.com/altair-viz/altair.git import altair as alt alt.data_transformers.enable(‘default’, max_rows=None) alt.renderers.enable(‘colab’) print(“Done installing Altair.”)
# スプレッドシートをインストールし、認証モジュールをインポートします。 USER_RATINGS = False !pip install –upgrade -q gspread from google.colab import auth import gspread from oauth2client.client import GoogleCredentials |
2.2 データロード
MovieLensのデータセットを読み込みます。 users、ratings、moviesのデータフレームを作成します。
| # Download MovieLens データセット from urllib.request import urlretrieve import zipfile
urlretrieve(“http://files.grouplens.org/datasets/movielens/ml-100k.zip”, “movielens.zip”) zip_ref = zipfile.ZipFile(‘movielens.zip’, “r”) zip_ref.extractall() print(“Done. Dataset contains:”) print(zip_ref.read(‘ml-100k/u.info’))
# users データフレーム users_cols = [‘user_id’, ‘age’, ‘sex’, ‘occupation’, ‘zip_code’] users = pd.read_csv( ‘ml-100k/u.user’, sep=’|’, names=users_cols, encoding=’latin-1′)
# ratingsデータフレーム作成 ratings_cols = [‘user_id’, ‘movie_id’, ‘rating’, ‘unix_timestamp’] ratings = pd.read_csv( ‘ml-100k/u.data’, sep=’\t’, names=ratings_cols, encoding=’latin-1′)
# movies データフレーム作成 genre_cols = [ “genre_unknown”, “Action”, “Adventure”, “Animation”, “Children”, “Comedy”, “Crime”, “Documentary”, “Drama”, “Fantasy”, “Film-Noir”, “Horror”, “Musical”, “Mystery”, “Romance”, “Sci-Fi”, “Thriller”, “War”, “Western” ] movies_cols = [ ‘movie_id’, ‘title’, ‘release_date’, “video_release_date”, “imdb_url” ] + genre_cols movies = pd.read_csv( ‘ml-100k/u.item’, sep=’|’, names=movies_cols, encoding=’latin-1′) |
モデル用のデータ加工
・IDは1から始まるので、0から始まるようにシフトします。
・ジャンルが割り当てられている映画の数を計算します。
・all_genres:映画のすべてのアクティブなジャンル。
・genre:アクティブなジャンルからランダムにサンプリングされます。
| # IDは1から始まる変更 users[“user_id”] = users[“user_id”].apply(lambda x: str(x-1)) movies[“movie_id”] = movies[“movie_id”].apply(lambda x: str(x-1)) movies[“year”] = movies[‘release_date’].apply(lambda x: str(x).split(‘-‘)[-1]) ratings[“movie_id”] = ratings[“movie_id”].apply(lambda x: str(x-1)) ratings[“user_id”] = ratings[“user_id”].apply(lambda x: str(x-1)) ratings[“rating”] = ratings[“rating”].apply(lambda x: float(x))
# ジャンルの件数 genre_occurences = movies[genre_cols].sum().to_dict()
# all_genresとgenreのカラムを作成 def mark_genres(movies, genres): def get_random_genre(gs): active = [genre for genre, g in zip(genres, gs) if g==1] if len(active) == 0: return ‘Other’ return np.random.choice(active) def get_all_genres(gs): active = [genre for genre, g in zip(genres, gs) if g==1] if len(active) == 0: return ‘Other’ return ‘-‘.join(active) movies[‘genre’] = [ get_random_genre(gs) for gs in zip(*[movies[genre] for genre in genres])] movies[‘all_genres’] = [ get_all_genres(gs) for gs in zip(*[movies[genre] for genre in genres])]
mark_genres(movies, genre_cols)
# movielensのデータフレーム movielens = ratings.merge(movies, on=’movie_id’).merge(users, on=’user_id’) |
学習とテストデータをかける関数
| def split_dataframe(df, holdout_fraction=0.1): test = df.sample(frac=holdout_fraction, replace=False) train = df[~df.index.isin(test.index)] return train, test |
2.3 データ確認
Usersデータ確認
| users.describe(include=[np.object]) |
user_id sex occupation zip_code
count 943 943 943 943
unique 943 2 21 795
top 419 M student 55414
freq 1 670 196 9
moviesデータ確認
| movies.describe(include=[np.object]) |
movie_id title release_date imdb_url year genre all_genres
count 1682 1682 1681 1679 1682 1682 1682
unique 1682 1664 240 1660 72 19 216
top 1303 Ice Storm, The (1997) 01-Jan-1995 http://… 1996 Drama Drama
freq 1 2 215 2 355 547 376
ratingsデータ確認
| ratings.describe(include=[np.object]) |
user_id movie_id
count 100000 100000
unique 943 1682
top 404 49
freq 737 583
2.4 モデル作成
映画の評価するユーザーが少ないです。効率的な表現のために、tf.SparseTensor を使用します。
| def build_rating_sparse_tensor(ratings_df): indices = ratings_df[[‘user_id’, ‘movie_id’]].values values = ratings_df[‘rating’].values return tf.SparseTensor( indices=indices, values=values, dense_shape=[users.shape[0], movies.shape[0]])
|
Mean Squared Errorのモデル評価
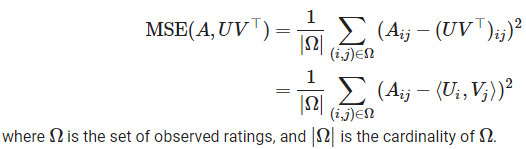
| def sparse_mean_square_error(sparse_ratings, user_embeddings, movie_embeddings): predictions = tf.gather_nd( tf.matmul(user_embeddings, movie_embeddings, transpose_b=True), sparse_ratings.indices) loss = tf.losses.mean_squared_error(sparse_ratings.values, predictions) return loss |
| # CFModel helper class class CFModel(object): self._embedding_vars = embedding_vars self._loss = loss self._metrics = metrics self._embeddings = {k: None for k in embedding_vars} self._session = None
@property def embeddings(self): “””The embeddings dictionary.””” return self._embeddings
def train(self, num_iterations=100, learning_rate=1.0, plot_results=True, optimizer=tf.train.GradientDescentOptimizer): with self._loss.graph.as_default(): opt = optimizer(learning_rate) train_op = opt.minimize(self._loss) local_init_op = tf.group( tf.variables_initializer(opt.variables()), tf.local_variables_initializer()) if self._session is None: self._session = tf.Session() with self._session.as_default(): self._session.run(tf.global_variables_initializer()) self._session.run(tf.tables_initializer()) tf.train.start_queue_runners()
with self._session.as_default(): local_init_op.run() iterations = [] metrics = self._metrics or ({},) metrics_vals = [collections.defaultdict(list) for _ in self._metrics]
# Train and append results. for i in range(num_iterations + 1): _, results = self._session.run((train_op, metrics)) if (i % 10 == 0) or i == num_iterations: print(“\r iteration %d: ” % i + “, “.join( [“%s=%f” % (k, v) for r in results for k, v in r.items()]), end=”) iterations.append(i) for metric_val, result in zip(metrics_vals, results): for k, v in result.items(): metric_val[k].append(v)
for k, v in self._embedding_vars.items(): self._embeddings[k] = v.eval()
if plot_results: # Plot the metrics. num_subplots = len(metrics)+1 fig = plt.figure() fig.set_size_inches(num_subplots*10, 8) for i, metric_vals in enumerate(metrics_vals): ax = fig.add_subplot(1, num_subplots, i+1) for k, v in metric_vals.items(): ax.plot(iterations, v, label=k) ax.set_xlim([1, num_iterations]) ax.legend() return results
|
| # マトリックス因数分解モデルを構築し、学習します。 def build_model(ratings, embedding_dim=3, init_stddev=1.): # Split the ratings DataFrame into train and test. train_ratings, test_ratings = split_dataframe(ratings) # SparseTensor representation of the train and test datasets. A_train = build_rating_sparse_tensor(train_ratings) A_test = build_rating_sparse_tensor(test_ratings) # Initialize the embeddings using a normal distribution. U = tf.Variable(tf.random_normal( [A_train.dense_shape[0], embedding_dim], stddev=init_stddev)) V = tf.Variable(tf.random_normal( [A_train.dense_shape[1], embedding_dim], stddev=init_stddev)) train_loss = sparse_mean_square_error(A_train, U, V) test_loss = sparse_mean_square_error(A_test, U, V) metrics = { ‘train_error’: train_loss, ‘test_error’: test_loss } embeddings = { “user_id”: U, “movie_id”: V } return CFModel(embeddings, train_loss, [metrics])
|
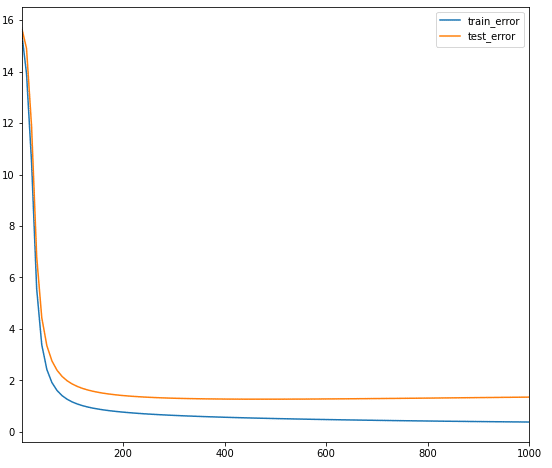
協調フィルタリングを学習します。
| # Build the CF model and train it. model = build_model(ratings, embedding_dim=30, init_stddev=0.5) model.train(num_iterations=1000, learning_rate=10.)
|
2.5 レコメンドエンジンで距離計算
Aladdinを入力すると、一番似ている映画が表示します。
| movie_neighbors(reg_model, “Aladdin”, COSINE) |
cosine score titles genres
94 1.000 Aladdin (1992) Animation-Children-Comedy-Musical
587 0.848 Beauty and the Beast (1991) Animation-Children-Musical
70 0.830 Lion King, The (1994) Animation-Children-Musical
81 0.816 Jurassic Park (1993) Action-Adventure-Sci-Fi
417 0.749 Cinderella (1950) Animation-Children-Musical
173 0.746 Raiders of the Lost Ark (1981) Action-Adventure
2.6 入力したデータからレコメンドエンジン利用
Google driveを接続して、スプレッドシートにデータを入力します。
| USER_RATINGS = True #@param {type:”boolean”}
# 実行してスプレッドシートを作成し、それを使用して評価を入力します。 if USER_RATINGS: auth.authenticate_user() gc = gspread.authorize(GoogleCredentials.get_application_default()) # Create the spreadsheet and print a link to it. try: sh = gc.open(‘MovieLens-test’) except(gspread.SpreadsheetNotFound): sh = gc.create(‘MovieLens-test’)
worksheet = sh.sheet1 titles = movies[‘title’].values cell_list = worksheet.range(1, 1, len(titles), 1) for cell, title in zip(cell_list, titles): cell.value = title worksheet.update_cells(cell_list) print(“Link to the spreadsheet: ” “https://docs.google.com/spreadsheets/d/{}/edit”.format(sh.id))
|
下記のようなデータを入力します。
入力したデータをロードします。
| # スプレッドシートから評価をロードし、DataFrameを作成します。 if USER_RATINGS: my_ratings = pd.DataFrame.from_records(worksheet.get_all_values()).reset_index() my_ratings = my_ratings[my_ratings[1] != ”] my_ratings = pd.DataFrame({ ‘user_id’: “943”, ‘movie_id’: list(map(str, my_ratings[‘index’])), ‘rating’: list(map(float, my_ratings[1])), }) # Remove previous ratings. ratings = ratings[ratings.user_id != “943”] # Add new ratings. ratings = ratings.append(my_ratings, ignore_index=True) # Add new user to the users DataFrame. if users.shape[0] == 943: users = users.append(users.iloc[942], ignore_index=True) users[“user_id”][943] = “943” print(“Added your %d ratings; you have great taste!” % len(my_ratings)) ratings[ratings.user_id==”943″].merge(movies[[‘movie_id’, ‘title’]])
|
Added your 15 ratings; you have great taste!
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:18: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
入力データから推奨事項と最近傍を提供する
| # Matrix Factorization model DOT = ‘dot’ COSINE = ‘cosine’ def compute_scores(query_embedding, item_embeddings, measure=DOT): u = query_embedding V = item_embeddings if measure == COSINE: V = V / np.linalg.norm(V, axis=1, keepdims=True) u = u / np.linalg.norm(u) scores = u.dot(V.T) return scores |
| def user_recommendations(model, measure=DOT, exclude_rated=False, k=6): if USER_RATINGS: scores = compute_scores( model.embeddings[“user_id”][943], model.embeddings[“movie_id”], measure) score_key = measure + ‘ score’ df = pd.DataFrame({ score_key: list(scores), ‘movie_id’: movies[‘movie_id’], ‘titles’: movies[‘title’], ‘genres’: movies[‘all_genres’], }) if exclude_rated: # remove movies that are already rated rated_movies = ratings[ratings.user_id == “943”][“movie_id”].values df = df[df.movie_id.apply(lambda movie_id: movie_id not in rated_movies)] display.display(df.sort_values([score_key], ascending=False).head(k))
def movie_neighbors(model, title_substring, measure=DOT, k=6): # Search for movie ids that match the given substring. ids = movies[movies[‘title’].str.contains(title_substring)].index.values titles = movies.iloc[ids][‘title’].values if len(titles) == 0: raise ValueError(“Found no movies with title %s” % title_substring) print(“Nearest neighbors of : %s.” % titles[0]) if len(titles) > 1: print(“[Found more than one matching movie. Other candidates: {}]”.format( “, “.join(titles[1:]))) movie_id = ids[0] scores = compute_scores( model.embeddings[“movie_id”][movie_id], model.embeddings[“movie_id”], measure) score_key = measure + ‘ score’ df = pd.DataFrame({ score_key: list(scores), ‘titles’: movies[‘title’], ‘genres’: movies[‘all_genres’] }) display.display(df.sort_values([score_key], ascending=False).head(k))
|
自分のレビューから、下記の映画リストを推論(レコメンド)されました。
| user_recommendations(model, measure=COSINE, k=5) |
cosine score movie_id titles genres
219 0.698 219 Mirror Has Two Faces, The (1996) Comedy-Romance
739 0.672 739 Jane Eyre (1996) Drama-Romance
844 0.670 844 That Thing You Do! (1996) Comedy
236 0.647 236 Jerry Maguire (1996) Drama-Romance
292 0.645 292 Donnie Brasco (1997) Crime-Drama
| # Embedding Visualization code (run this cell)
def visualize_movie_embeddings(data, x, y): nearest = alt.selection( type=’single’, encodings=[‘x’, ‘y’], on=’mouseover’, nearest=True, empty=’none’) base = alt.Chart().mark_circle().encode( x=x, y=y, color=alt.condition(genre_filter, “genre”, alt.value(“whitesmoke”)), ).properties( width=600, height=600, selection=nearest) text = alt.Chart().mark_text(align=’left’, dx=5, dy=-5).encode( x=x, y=y, text=alt.condition(nearest, ‘title’, alt.value(”))) return alt.hconcat(alt.layer(base, text), genre_chart, data=data)
def tsne_movie_embeddings(model): “””Visualizes the movie embeddings, projected using t-SNE with Cosine measure. Args: model: A MFModel object. “”” tsne = sklearn.manifold.TSNE( n_components=2, perplexity=40, metric=’cosine’, early_exaggeration=10.0, init=’pca’, verbose=True, n_iter=400)
print(‘Running t-SNE…’) V_proj = tsne.fit_transform(model.embeddings[“movie_id”]) movies.loc[:,’x’] = V_proj[:, 0] movies.loc[:,’y’] = V_proj[:, 1] return visualize_movie_embeddings(movies, ‘x’, ‘y’)
|
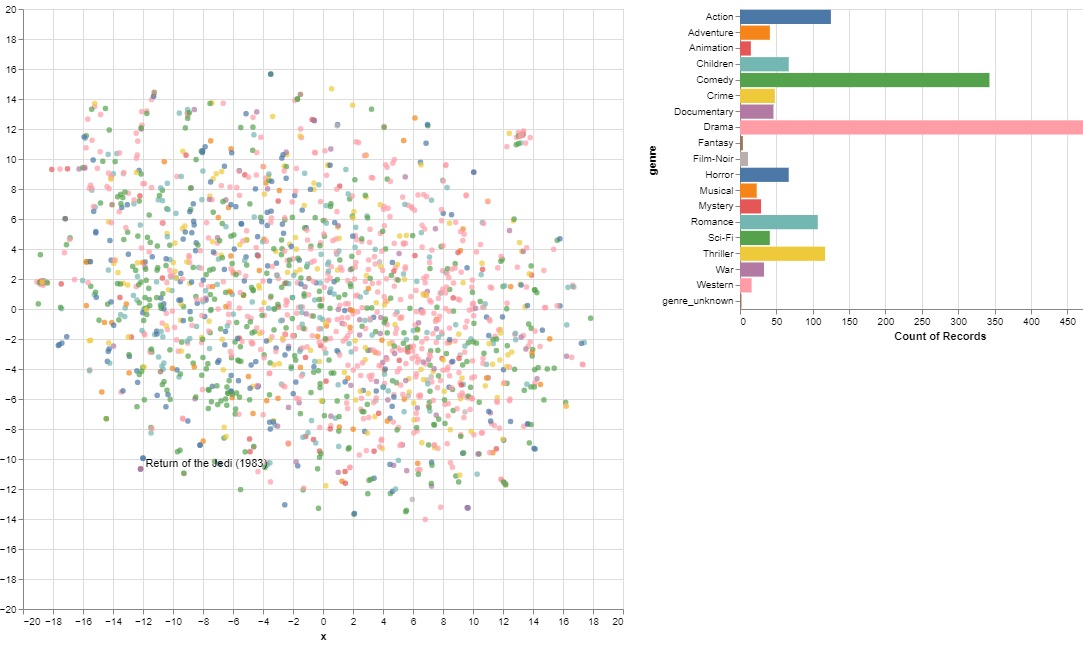
次元削減した後のEmbeddingを可視化します。
各映画の距離を確認することができます。
| tsne_movie_embeddings(model_lowinit) |

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属