
機械学習モデルを学習させた時に、実際にモデルはどの特徴量を見て予測をしているのかが知りたい時があります。今回はモデルによる予測結果の解釈性を向上させる方法の1つであるSHAPを解説します。
目次
1. XAIとは
2. SHAPとは
3. 実験・コード 1:回帰モデル(Diabetes dataset)
__3.1 データ読み込み
__3.2 モデル作成
__3.3 SHAP値
__3.4 SHAP可視化
4. 実験・コード 2:画像データ(Imagenet)
__4.1 データ読み込み
__4.2 モデル作成
__4.3 SHAP可視化
1. XAI (Explainable AI)とは
XAI はExplainable AI(説明可能なAI)の英略称です。言葉通り、予測結果や推定結果に至るプロセスが人間によって説明可能になっている機械学習のモデルに関する技術や研究分野のことを指します。 AI/機械学習(特にディープラーニングなどのニューラルネットワーク)によって作成されるモデルの中身は、仕組みの性質上、基本的に解釈が難しいです。そのため、中身はブラックボックス(=内部が不明になっている箱のことと言われます。
機械学習モデルを解釈する技術にはSHAP、LIME、DeepLIFT、AIX360 (IBM)、Activation Atlases (Googleと OpenAI)などの様々なツールが考案されています。
今回紹介するSHAPは、機械学習モデルがあるサンプルの予測についてどのような根拠でその予測を行ったかを解釈するツールです。
2. SHAPとは
SHAP「シャプ」はSHapley Additive exPlanationsの略称で、モデルの予測結果に対する各変数(特徴量)の寄与を求めるための手法です。SHAPは日本語だと「シャプ」のような発音のようです。ある特徴変数の値の増減が与える影響を可視化することができます。
Shapley Value Estimation

3. 実験・コード 1:回帰モデル(Diabetes dataset)
データセット:糖尿病患者の診療データ(Diabetes dataset)
モデル:XGBoost Regressor model
可視化:機械学習モデルを解釈するSHAP
環境:ローカルのCPU
SHAPのインストール: pip install shap
3.1 データ読み込み
# Import libraries import shap import xgboost import pandas as pd shap.initjs()
SHAPのデータセットを利用します。
# Load Diabetes dataset X, y = shap.datasets.diabetes() X.head()
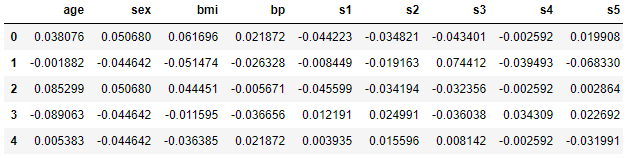
糖尿病患者442名のデータが入っており、基礎項目(age, sex, body mass index, average blood pressure)と6つの血液検査項目を入力とし、1年後の進行状況を予測ターゲットにします。
# Shape
print(X.shape, y.shape)
# Distribution of target variable
pd.Series(y).plot('hist')
3.2 モデル作成
XGBoostモデル作成
# Train using XGBoost Regressor model XGB_model = xgboost.XGBRegressor() XGB_model.fit(X, y)

3.3 SHAP値
TreeExplainerは勾配ブースティング(XGBoost, LightGBM, CatBoostなど)で作成したモデルを読み込み、SHAP値を導くためのインスタンスです。
# Create Tree explainer explainer = shap.TreeExplainer(XGB_model)
特徴データからSHAP値を計算し出力する
# Extract SHAP values to explain the model predictions shap_values = explainer.shap_values(X)
3.4 SHAP可視化
# Plot Feature Importance shap.summary_plot(shap_values, X, plot_type="bar")
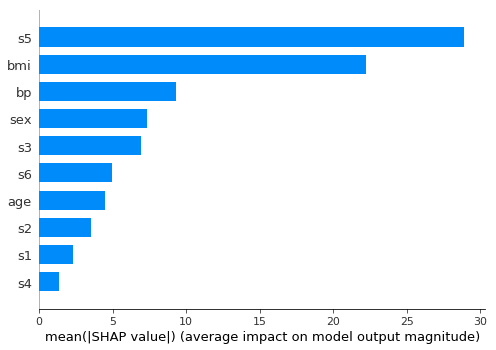
SHAP要約プロットを作成します。特徴値によって色付けされています。目的変数に対する各特徴変数の寄与度を図式化します。s5とbmiの特徴変数の寄与度が高いことがわかります。
相関関係を確認します。
# Plot Feature Importance - 'Dot' type shap.summary_plot(shap_values, X, plot_type='dot')
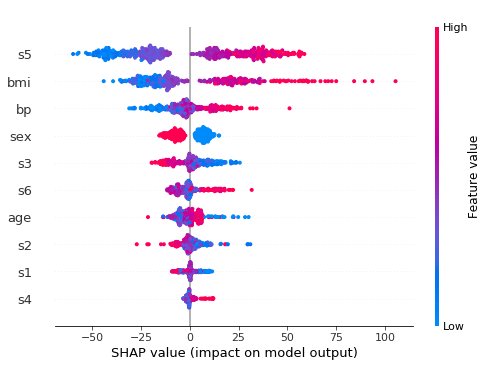
横軸が目的変数の値で縦軸が特徴変数の貢献度の高さです。赤が正の値を、青が負の値となります。
s5は目的変数が大きく(左側)なるほど青い分布となり、目的変数が小さく(右側)なるほど赤い分布となります。つまり、目的変数とs5は正の相関があることを示します。
Force Layout
# Visualize the explanation of first prediction shap.force_plot(explainer.expected_value, shap_values[0, :], X.iloc[0, :])

force layoutを用いて与えられたSHAP値と特徴変数の寄与度を視覚化します。同時に、SHAP値がどのような計算を行っているかもわかります。
# Visualize the training set using SHAP predictions shap.force_plot(explainer.expected_value, shap_values, X)
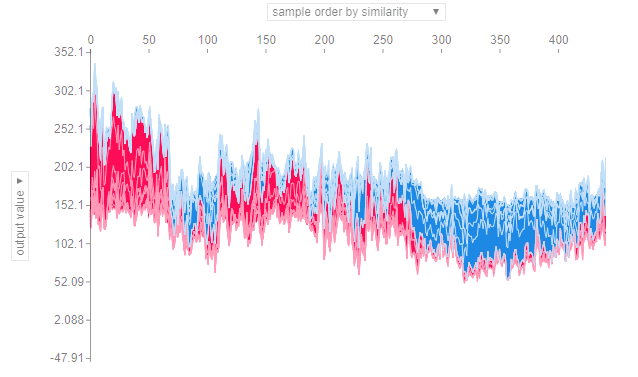
縦軸が予測値、横軸は特徴量が似ているもの同士をまとめて並べた各サンプルを表しています。横軸の並び順は、予測値の大きさ順、特徴量の大きさ順などに変更することもでき、縦軸も特徴量ごとに絞ることが出来ます。
dependence_plot:
shap.dependence_plot(ind="s5", shap_values=shap_values, features=X)
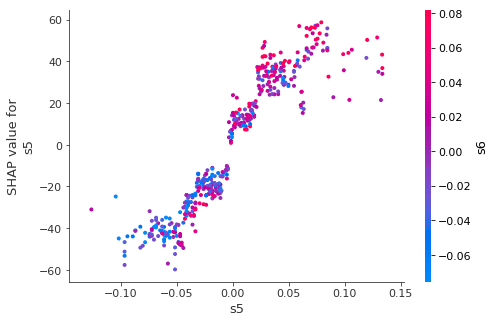
インタラクション機能によって色付けされた、SHAP依存関係プロットを作成します。 横軸に特徴値を縦軸に同じ特徴のSHAP値をプロットします。SHAP値が特徴変数にどう影響するかを表します。
4. 実験・コード 2:画像データ(Imagenet)
データセット:Imagenet (http://www.image-net.org/)
モデル: ディープラーニングの画像分類のモデルのVGG16
VGG16は、畳み込み13層とフル結合3層の計16層から成る畳み込みニューラルネットワークです。
NNのフレームワーク: TensorflowのKeras
可視化:SHAP可視化
環境:Google ColabのGPU
SHAPのインストール:
!pip install shap
4.1 データ読み込み
from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input, decode_predictions import numpy as np import shap import keras.backend as K import json # 学習済みモデルをロードする model = VGG16(weights='imagenet', include_top=True) X,y = shap.datasets.imagenet50() to_explain = X[[15,40]]
学習済みモデルのVGG16に画像を適当に与えて、2枚の画像の予測結果に寄与が大きかった画像の部位を確認してみます。
4.2 モデル作成
# 7番層のニューラルネットワークのデータを取ります。 def map2layer(x, layer): feed_dict = dict(zip([model.layers[0].input], [preprocess_input(x.copy())])) return K.get_session().run(model.layers[layer].input, feed_dict) e = shap.GradientExplainer((model.layers[7].input, model.layers[-1].output), map2layer(preprocess_input(X.copy()), 7)) shap_values,indexes = e.shap_values(map2layer(to_explain, 7), ranked_outputs=2)
2枚の画像の結果から、7番層のニューラルネットワークのデータを取ります。
4.3 SHAP可視化
# クラス名を作成 index_names = np.vectorize(lambda x: class_names[str(x)][1])(indexes) # SHAPを実行 shap.image_plot(shap_values, to_explain, index_names)
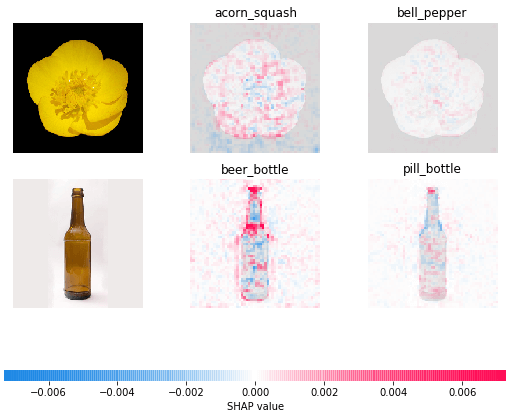
花と瓶の画像がそれぞれ入力しました。VGG16の識別結果はそれぞれ正しいものとなっています。
藍色と赤色が濃い部分が予測結果への寄与が大きい部分になります。この部分が花と瓶と判定するのに大きく寄与しています。このことからVGG16は識別に必要な部分に正しく着目できていると言えそうです。