
前回はkaggleコンペの「メルカリにおける値段推定」の1位の解析手法を話しました。内容が長いなので、3つの記事に分けました。今回は「Home Credit Default Risk 債務不履行の予測」のデータ理解について書きます。
目次
1. Home Credit Default Riskのコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の特徴量エンジニアリング
___2.1 特徴量生成
___2.2 カテゴリカル特徴量の処理
___2.3 特徴量選択
3. 1位のモデル作成
___3.1 3.1 Base Models
___3.2 アンサンブル学習(Ensemble learning)
___3.3 その他
1. Home Credit Default Riskのコンペの概要
1.1 コンペの概要


Home CreditがKaggleでHome Credit Default Risk(債務不履行の予測)コンペを主催しました。
Home Credit社は、アジアの9か国で信用の積み重ねが足りずに融資を受けることができない顧客にも融資を行う会社です。
目的:個人のクレジットの情報や以前の応募情報などから、各データが債務不履行になるかどうかを予測する問題です。
賞金: 1位35,000米ドル、2位25,000米ドル、3位10,000米ドル
期間: 2018/05/18 ~ 2018/08/10
参加チーム数:7,190
評価:AUC (area under the ROC curve)
ROC曲線は偽陽性率と真陽性率の表をプロットすると以下のようなグラフです。AUCは指標の名前通りROC 曲線下の面積(積分)となります。この曲線の面積(AUC)が大きいと、偽陽性率が低い(でたらめに陽性と決めつけない)上に、真陽性率が高い(陽性のものは正しく検出できる)モデルです。
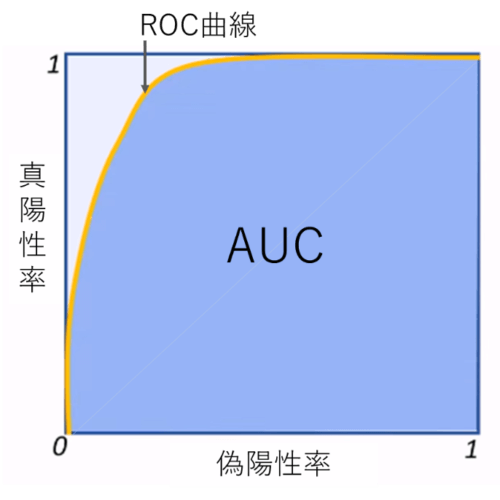
AUCの詳細はこちらです。
1.2 データセットの概要
application_{train|test}.csv
主に学習とテストのデータで、顧客一人一人の主要な情報(性別や家族の人数、資産額、車の有無などの情報。目的変数は債務不履行か、非債務不履行かのラベルデータ。
bureau.csv
Home Credit社以外のクレジットビューローでの融資情報(月次データ)
POS_CASH_balance.csv
bureauの負債残高の履歴(月次データ)
previous_application.csv
Home Credit社における過去の融資情報
installments_payments.csv
過去の融資の残高履歴
HomeCredit_columns_description.csv
各列の説明
ER図:
Application データはSK_ID_CURRのキーでbureauとprevious_applicationと紐付けます。また、previous_applicationはSK_ID_PREVのキーでPOS_CASH_balance、instalments_payments、credit_card_balanceと紐付けます。
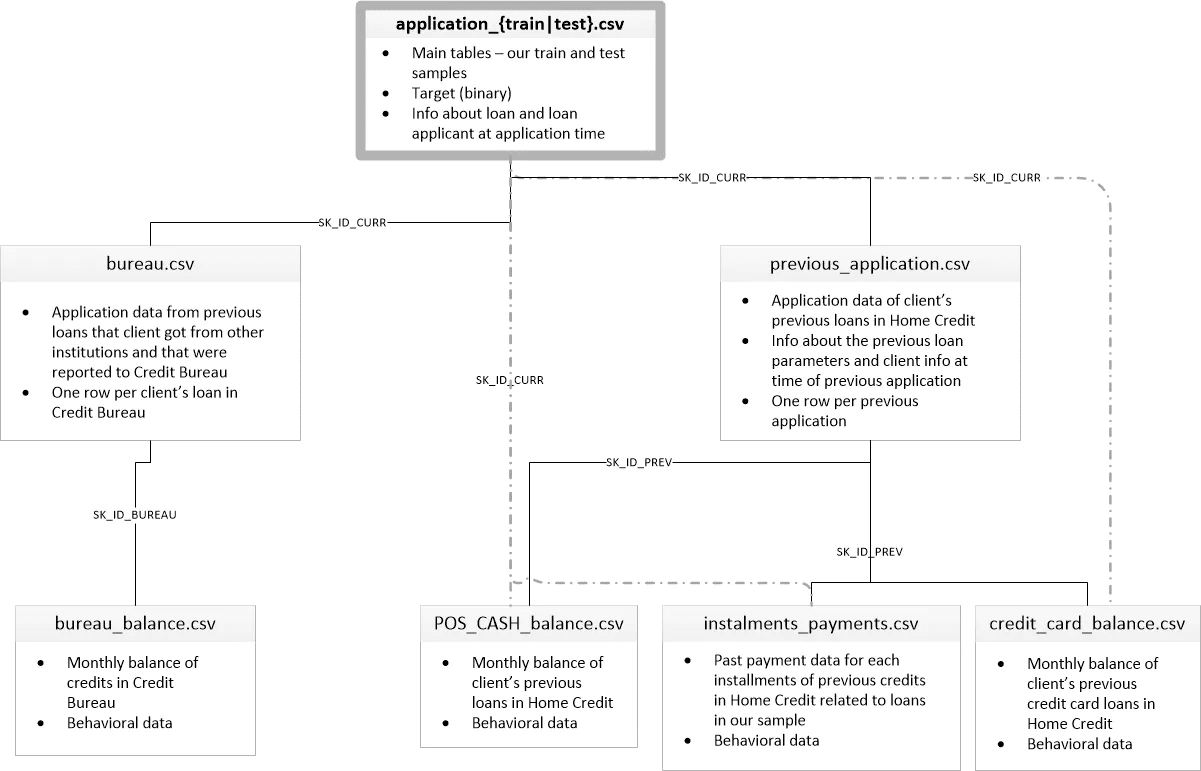
1.3 データの理解
全てのcsvファイルを読み込んで、データフレームを作成します。
# データ読み込み
import pandas as pd
application_train = pd.read_csv('/content/drive/My Drive/dataset/home_credit/application_train.csv')
application_test = pd.read_csv('/content/drive/My Drive/dataset/home_credit/application_test.csv')
bureau = pd.read_csv('/content/drive/My Drive/dataset/home_credit/bureau.csv')
bureau_balance = pd.read_csv('/content/drive/My Drive/dataset/home_credit/bureau_balance.csv')
previous_application = pd.read_csv('/content/drive/My Drive/dataset/home_credit/previous_application.csv')
POS_CASH_balance = pd.read_csv('/content/drive/My Drive/dataset/home_credit/POS_CASH_balance.csv')
installments_payments = pd.read_csv('/content/drive/My Drive/dataset/home_credit/installments_payments.csv')
credit_card_balance = pd.read_csv('/content/drive/My Drive/dataset/home_credit/credit_card_balance.csv')# データの行数・列数の確認
print('Size of application_train data', application_train.shape)
print('Size of application_test data', application_test.shape)
print('Size of bureau data', bureau.shape)
print('Size of bureau_balance data', bureau_balance.shape)
print('Size of previous_application data', previous_application.shape)
print('Size of POS_CASH_balance data', POS_CASH_balance.shape)
print('Size of installments_payments data', installments_payments.shape)
print('Size of credit_card_balance data', credit_card_balance.shape)
データ確認
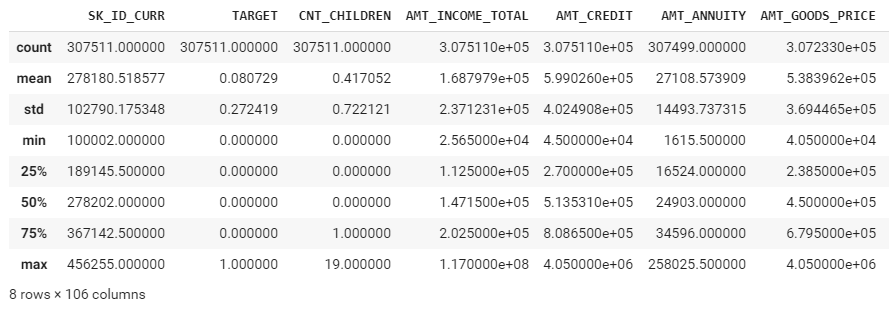
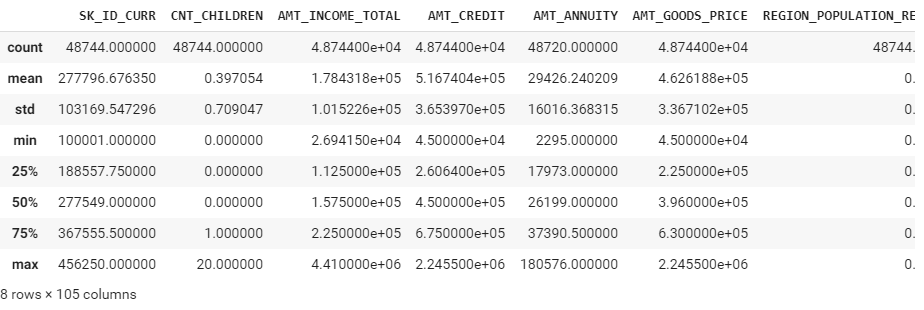
describeで各列の要約統計量(平均、標準偏差、最大値、最小値、など)を取得します。
application_train.describe()
application_test.describe()
bureau.describe()
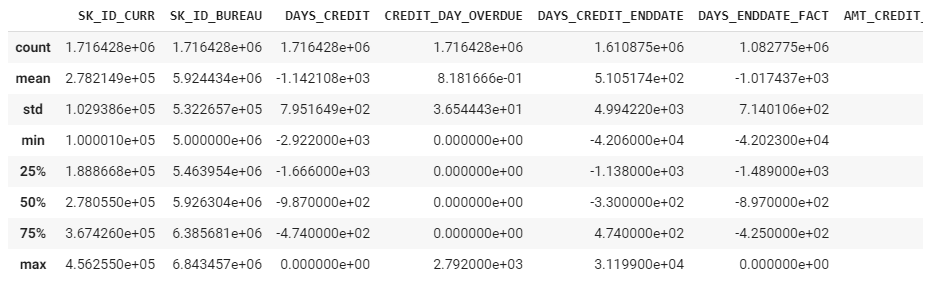
bureau_balance.describe()

previous_application.describe()
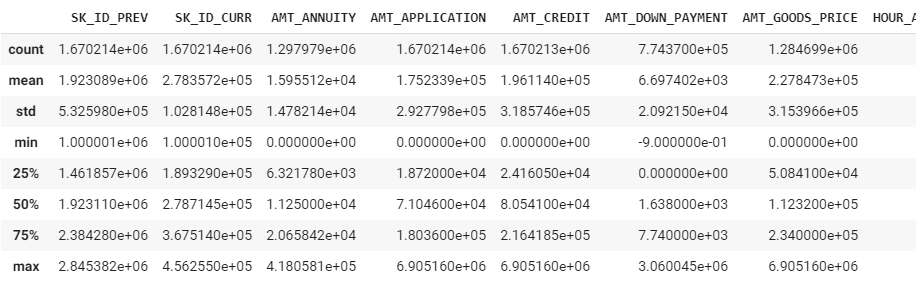
POS_CASH_balance.describe()
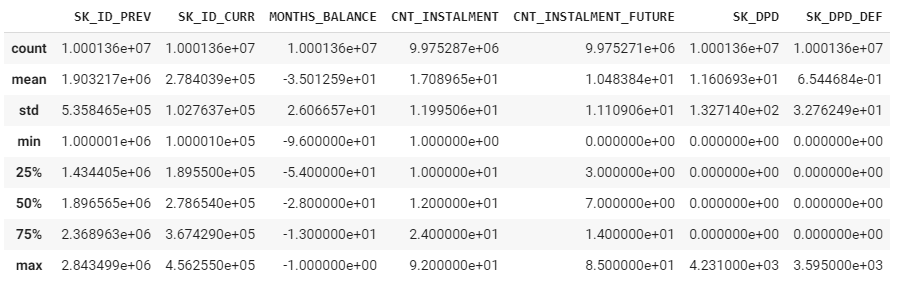
installments_payments.describe()
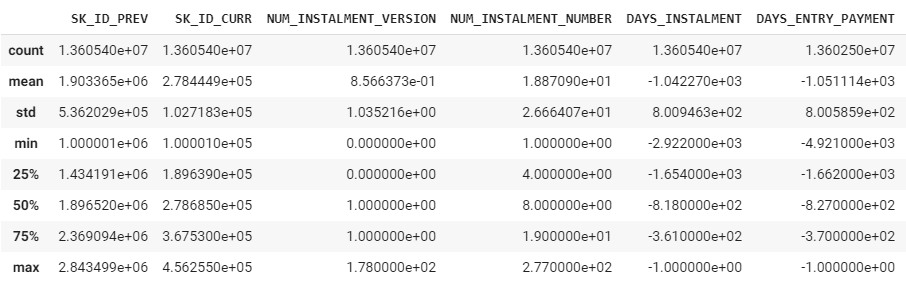
credit_card_balance.describe()
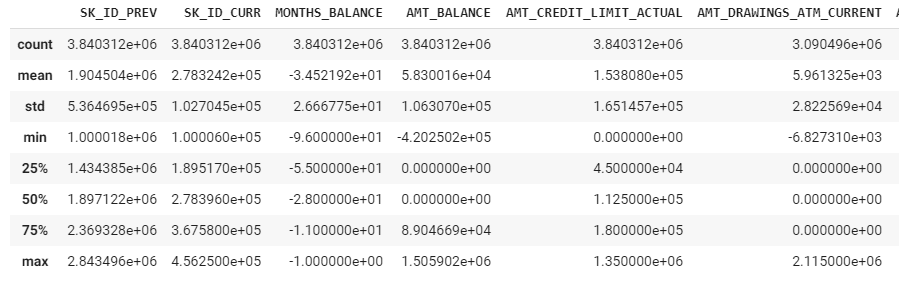
標準偏差が高い変数があるし、外れ値処理が必要だと思います。
欠損値の確認
先ず、欠損値の関数を作成します。欠損値のカラム数を数えて、欠損値の割合を計算します。
# 欠損値の確認関数
def missing_values_summary(df):
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'mis_val_count', 1 : 'mis_val_percent'})
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'mis_val_percent', ascending=False).round(1)
print ("カラム数:" + str(df.shape[1]) + "\n" + "欠損値のカラム数: " + str(mis_val_table_ren_columns.shape[0]))
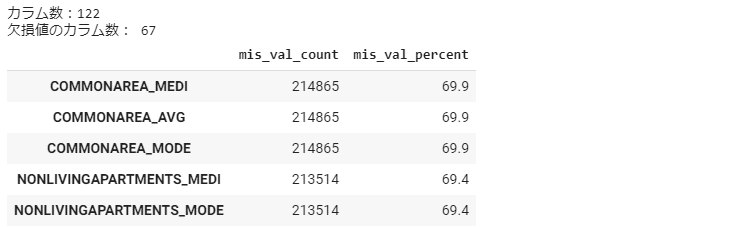
return mis_val_table_ren_columnsapplication_train_mv = missing_values_summary(application_train) application_train_mv.head(5)
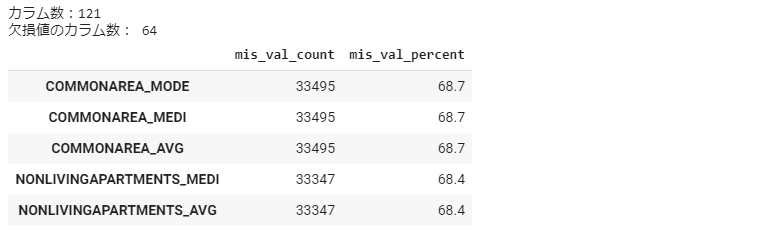
application_test_mv = missing_values_summary(application_test) application_test_mv.head(5)
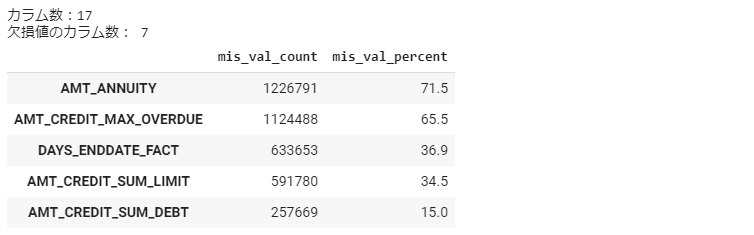
bureau_mv = missing_values_summary(bureau) bureau_mv.head(5)
bureau_balance_mv = missing_values_summary(bureau_balance) bureau_balance_mv.head(5)

previous_application_mv = missing_values_summary(previous_application) previous_application_mv.head(5)
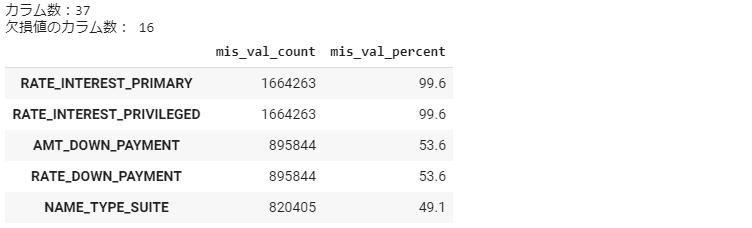
POS_CASH_balance_mv = missing_values_summary(POS_CASH_balance) POS_CASH_balance_mv.head(5)

installments_payments_mv = missing_values_summary(installments_payments) installments_payments_mv.head(5)

credit_card_balance_mv = missing_values_summary(credit_card_balance) credit_card_balance_mv.head(5)
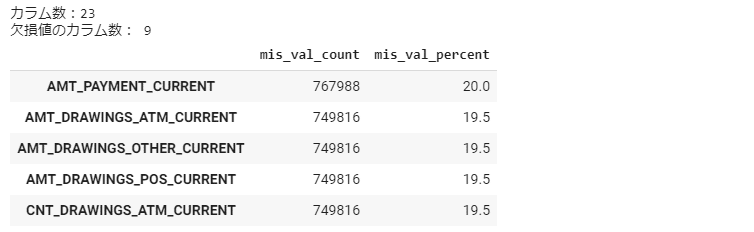
すべてのデータは欠損値が多いなので、前処理が必要だと思います。
データの分布
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,5))
plt.title("Distribution of AMT_CREDIT")
ax = sns.distplot(application_train["AMT_CREDIT"])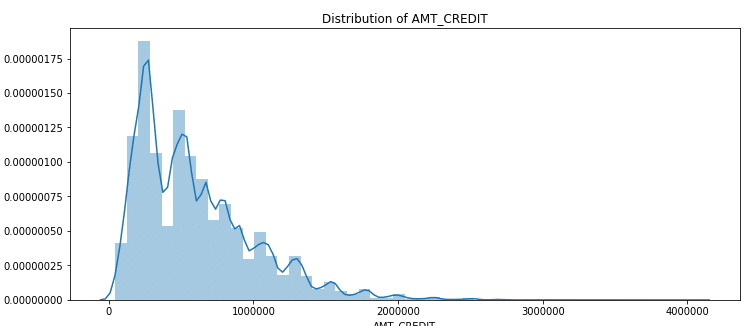
AMT_CREDITは左歪曲分布を確認しました。
plt.figure(figsize=(12,5))
plt.title("Distribution of TARGET")
ax = sns.distplot(application_train["TARGET"].dropna())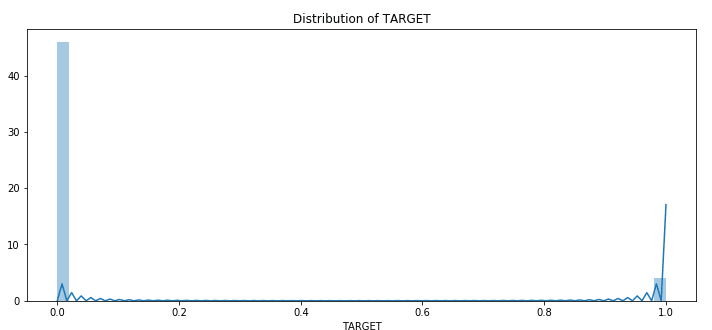
TARGETデータは不均衡な分布と確認しました。