
前回の記事はPysparkの分散処理でビックデータ処理の時間を大きく短縮させる方法を解説しました。今回は複数のCPUコアで並列処理の高速に計算の方法を解説します。
目次
1. joblibの概要
__1.1 分散処理 並列処理の違い
__1.2 joblib.Parallelの解説
2. 実験・コード
__2.1 ライブラリーのインストール
__2.2 環境情報を表示
__2.3. 普通のPythonの処理
__2.4. Joblibの並列処理
__2.5. 結果比較(可視化)
3. まとめ
1. joblibの概要
1.1分散処理 並列処理の違い
並列(Parallel):複数の計算機や複数の計算ユニットで構成される1つの自律的な処理です。1つの自律的なシステムであるため,当該処理系を構成する複数の計算機は,常に同一の状態を維持している必要があります。並列とは、計算速度を向上させるために同時に行うという物理的な概念です。
分散(Distributed):複数の自律的なシステムをネットワークとおして連携する処理です。分散システム技術をレプリケーションと呼びます。クラスター構成を構築して、やるようなSpark等がこれに当てはまります。
この2つは、そもそも目的が違う概念です。並行というのは、世の中一般、同時進行するものごとをプログラムとして表現する際に用いる広い概念です。一方で並列というのは、主に計算速度を稼ぐために計算を同時に進めることを言います。
1.2 joblib.Parallelの解説
joblib.Parallel(n_jobs=None, backend=None, verbose=0, timeout=None, pre_dispatch=’2 * n_jobs’, batch_size=’auto’, temp_folder=None, max_nbytes=’1M’, mmap_mode=’r’, prefer=None, require=None)
n_jobsはタスクを何分割するかという指定をする部分です。-1でコア数をマックスで使うように計らってくれます。
verboseは途中経過を表示する頻度を指定する引数で0~10の値です。0ではなにも表示せず、10で最頻になります。
backendで”threading”を選べばマルチスレッドで動作して、オーバーヘッドは減るがPythonのGILにより通常の処理中は並列処理できない(GILをリリースする部分だけが並列で動作できる=DBアクセスの待ちなどが大きいプログラムの場合のみ有効で小さい場合は速度低下の恐れもある)、デフォルトは”multiprocessing”のマルチプロセス動作です。
Timeout 完了する各タスクのタイムアウト制限です。タスクに時間がかかると、TimeOutErrorが発生します。
pre_dispatch 事前発送されるタスクのバッチの数。
batch_size 各ワーカーに一度にディスパッチする自動的のタスクの数。
temp_folder ワーカープロセスとメモリを共有するために大きな配列をマッピングするためにプールで使用されるフォルダーです。
max_nbytes temp_folderで自動メモリマッピングをトリガーするワーカーに渡される配列のサイズのしきい値。
mmap_mode ワーカーに渡されるnumpy配列のモード。
詳細;https://joblib.readthedocs.io/en/latest/generated/joblib.Parallel.html
2. 実験・コード
環境: ローカルのパソコン(4コアCPU、8論理プロセッサー数)タスク: sum loop
評価方法: 1コア、2コア、4コア、8コア、16コアの設定の実行時間を比較します。
2.1. ライブラリーのインストール
実験のために、joblibとpy-cpuinfoのライブラリをインストールしました。py-cpuinfoはプレゼントの情報を表示するライブラリです。
ライブラリの導入:
pip install joblib
pip install py-cpuinfo
2.2 環境情報を表示
import cpuinfo cpuinfo.get_cpu_info()['brand']
‘Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz’
import os os.cpu_count()
8
※実際は コアのCPU 4、論理プロセッサー数 8
2.3. 普通のPythonの処理
from datetime import datetime
def process(n):
return sum([i*n for i in range(10000)])
start_time = datetime.now()
total = 0
for i in range(10000):
total += process(i)
print(total)
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:21.287564
2.4. Joblibの並列処理
タスクの分割 = 1
from joblib import Parallel, delayed
from datetime import datetime
def process(n):
return sum([i*n for i in range(10000)])
start_time = datetime.now()
r = Parallel(n_jobs=1)( [delayed(process)(i) for i in range(10000)] )
print(sum(r))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:22.226125
Joblibの並列処理 (タスクの分割 = 2)
start_time = datetime.now()
r = Parallel(n_jobs=2)( [delayed(process)(i) for i in range(10000)] )
print(sum(r))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:12.974260
Joblibの並列処理 (タスクの分割 = 4)
start_time = datetime.now()
r = Parallel(n_jobs=4)( [delayed(process)(i) for i in range(10000)] )
print(sum(r))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:08.938229
Joblibの並列処理 (タスクの分割 = 8)
start_time = datetime.now()
r = Parallel(n_jobs=8)( [delayed(process)(i) for i in range(10000)] )
print(sum(r))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:08.586884
Joblibの並列処理 (タスクの分割 = 16)
start_time = datetime.now()
r = Parallel(n_jobs=16)( [delayed(process)(i) for i in range(10000)] )
print(sum(r))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))2499500025000000
Duration: 0:00:10.676941
2.5. 結果比較(可視化)
%matplotlib inline
import matplotlib.pyplot as plt
x = (1,2,4,8,16)
y = (22.2, 13.0, 8.9, 8.6, 10.7)
plt.plot(x, y)
plt.xlabel('no. of core')
plt.ylabel('time(sec)')
plt.show()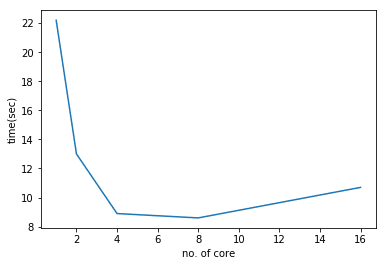
3. まとめ
Joblibで並列処理による、処理時間は4分の1以下になりました。CPUコアの数と速度は線形関係ではありません。また、論理プロセッサー数は8ですが、実際は4コアと同じ速さです。物理コアの数に大きく依存することがわかります。