関係記事:クラスター数の決め方の1つシルエット分析、 k-means++
ビッグデータ処理や機械学習の場合は、巨大データの取り扱いを目的とした分散処理のフレームワークが必要です。特定のアプリケーションに関する実行性能はSpark MLです。今回の記事はSpark MLでk-meanのクラスタリングを解説します。
目次
1. PySparkのクラスタリング
2. 実験・コード
__2.1 ライブラリーのインポート
__2.2 データ処理
__2.3. シルエットスコアの比較
__2.4. クラスタリングのモデルを作成
__2.5. 可視化
1. Spark MLのk-meanクラスタリング
Spark MLはSparkの統計処理、機械学習を分散処理するライブラリです。k-meanはは最も一般的に使われる、事前に定義したクラスタ数までデータを群にする、クラスタリング アルゴリズムです。
spark.mlでのパラメータ:
– k は要求するクラスタの数です。
– maxIterations は実行の繰り返しの最大数です。
– initializationMode はランダム初期化
– initializationSteps は k-meansアルゴリズム内でのステップ数を決定します。
– epsilon はk-meansが収束したと見なす距離の閾値を決定します。
– initialModel は初期化に使用されるクラスタの中心点の任意のセットです。
2. 実験・コード
概要
データセット: UCI機械学習リポジトリの白ワインの属性
環境: Databricks
Runtime Version: 6.0 ML (includes Apache Spark 2.4.3, Scala 2.11)
モデル:K-meanクラスタリング K 2 ~ K 7
2.1 ライブラリーのインポート
from pyspark.ml.clustering import KMeans from pyspark.ml.evaluation import ClusteringEvaluator from pyspark.sql import SparkSession
データのダウンロード
import urllib
urllib.request.urlretrieve("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", "/dbfs/data/winequality-red.csv")2.2 データ処理
データフォーマットを作成
sp_path = '/data/winequality-red.csv' sdf = spark.read.csv(sp_path, header=True, sep=';', inferSchema=True)
sdf:pyspark.sql.dataframe.DataFrame
fixed acidity:double
volatile acidity:double
citric acid:double
residual sugar:double
chlorides:double
free sulfur dioxide:double
total sulfur dioxide:double
density:double
pH:double
sulphates:double
alcohol:double
quality:integer
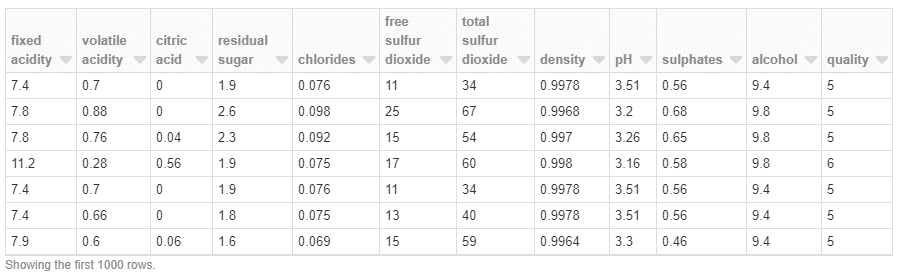
データを表示
display(sdf)
ベクトルアセンブラーを作成
from pyspark.ml.feature import VectorAssembler train = VectorAssembler(inputCols = sdf.columns, outputCol = "features").transform(sdf)
2.3 シルエットスコアの比較
for k in range(2,8):
kmeans = KMeans().setK(k).setSeed(1)
model = kmeans.fit(train)
predictions = model.transform(train)
evaluator = ClusteringEvaluator()
silhouette = evaluator.evaluate(predictions)
print("With K={}".format(k))
print("Silhouette with squared euclidean distance = " + str(silhouette))
print('--'*30)
print("High value indicates that the object is well matched to its own cluster")With K=2
Silhouette with squared euclidean distance = 0.7743418116498192
————————————————————
With K=3
Silhouette with squared euclidean distance = 0.6900419073907927
————————————————————
With K=4
Silhouette with squared euclidean distance = 0.6731241279450502
————————————————————
With K=5
Silhouette with squared euclidean distance = 0.6212314629242999
————————————————————
With K=6
Silhouette with squared euclidean distance = 0.5917531394311327
————————————————————
With K=7
Silhouette with squared euclidean distance = 0.5546944597705324
————————————————————
High value indicates that the object is well matched to its own cluster
2.4 モデルを作成 (2k)
# Trains a k-means model. kmeans = KMeans().setK(2).setSeed(1) model = kmeans.fit(train)
推論
# Make predictions predictions = model.transform(train)
2.5 可視化
クラスタリングの結果
countByCluster = predictions.groupBy("prediction").count()
display(countByCluster)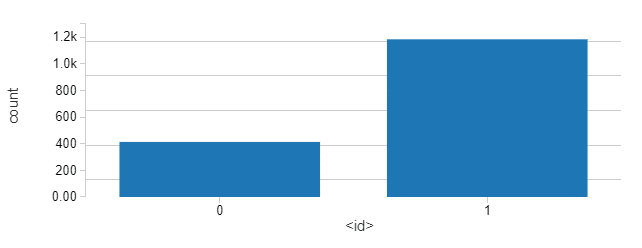
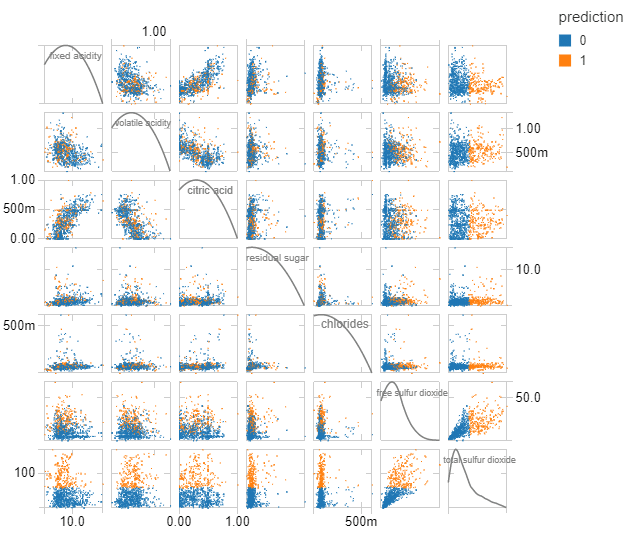
クラスタリングの分布図
display(predictions)