
この記事は、kaggle1位の解析手法:BirdCLEF 2021 – Birdcall Identification【2版】のシリーズの第1番です。第2番は下記です。
kaggle1位の解析手法:BirdCLEF 2021 – Birdcall Identification 【2 第2版】
目次
1. コンペの概要
2. コンペの評価
3. タイムライン
4. データセット
5. 探索的データ分析(EDA)
関連記事:librosa-Pythonで音声処理, 音楽解析
1. コンペの概要
コンペの目標は、鳥の種類を推定する音声処理のコンペです。The LifeCLEF Bird Recognition Challenge (BirdCLEF)が開催して、音響データセットより、録音物で鳥の分類の開発です。
The LifeCLEF Bird Recognition Challenge (BirdCLEF)は、世界中の保護活動を支援するために、継続的なサウンドスケープデータで鳥の鳴き声を識別する機械学習アルゴリズムの開発に焦点を当てています。 2014年に開始され、データセットの最大の鳥の鳴き声認識コンテストの1つになりました。
2. コンペの評価
行ごとのマイクロ平均F1スコアに基づいて評価されます。
row_id のウィンドウごとに、その時間ウィンドウで開始または終了する呼び出しを行った一意の鳥のセットのスペース区切りリストを提供する必要があります。 時間枠内に鳥の鳴き声がない場合は、コードnocallを使用します。
結果のサンプル
| row_id,birds 3575_COL_5,wewpew batpig1 3575_COL_10,wewpew batpig1 3575_COL_15,wewpew batpig1 … |
3. タイムライン
2021年4月1日~2021年6月1日の3か月間です。
4. データ
train_short_audio-トレーニングデータの大部分は、xenocanto.orgのユーザーによってアップロードされた個々の鳥の鳴き声の短い録音で構成されています。 これらのファイルは、テストセットのオーディオと一致するように適用可能な場合は32 kHzにダウンサンプリングされ、ogg形式に変換されています。
train_soundscapes-テストセットに相当する音声のファイルです。 それらはすべておよそ10分の長さで、ogg形式です。
test_soundscapes-ノートブックを送信すると、test_soundscapesディレクトリには、スコアリングに使用される約80の録音が入力されます。 これらは約10分の長さで、oggオーディオ形式になります。
test.csv-最初の3行のみをダウンロードできます。 完全なtest.csvは非表示のテストセットにあります。
row_id:行のIDコード。
site:サイトID。
seconds:時間枠を終了する秒
audio_id:オーディオファイルのIDコード。
train_metadata.csv-トレーニングデータ用にさまざまなメタデータが提供されています。
primary_label:鳥の種のコード。
recodist:録音を提供したユーザー。
latitude & longitude:記録が行われた場所。
date:記録日。
filename:オーディオファイル名。
train_soundscape_labels.csv
row_id:行のIDコード。
seconds:サイトID。
seconds:時間枠を終了する秒
audio_id:オーディオファイルのIDコード。
birds:5秒のウィンドウに表示される鳥の種のラベルです。 ラベルnocallは、呼び出しが発生しなかったことを意味します。
ample_submission.csv-発行ファイルです。
row_id:5秒のウィンドウのID
birds:鳥の種のラベル
5. 探索的データ分析(EDA)
※コードは下記のノートブックを参考してください。
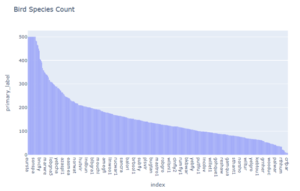
62874の行、14列のデータ、397の鳥の種です。
| import pandas as pd import numpy as np
meta = pd.read_csv(‘../input/birdclef-2021/train_metadata.csv’)
print(meta.shape) print(len(species)) |
(62874, 14)
397
| import plotly.express as px species = meta[‘primary_label’].value_counts() fig = px.bar(species, x=species.index, y=’primary_label’, labels=dict(x=”Species”, y=”Count”),title = “Bird Species Count”) fig.show() |
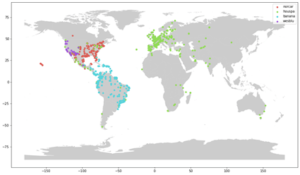
記録した場所の地図です。
| import matplotlib.pyplot as plt import seaborn as sns import descartes import geopandas as gpd from shapely.geometry import Point, Polygon
# SHP file world_map = gpd.read_file(“../input/world-shapefile/world_shapefile.shp”)
# Coordinate reference system crs = {“init” : “epsg:4326”}
# Lat and Long need to be of type float, not object species_list = [‘norcar’, ‘houspa’, ‘wesblu’, ‘banana’] data = meta[meta[‘primary_label’].isin(species_list)] data[“latitude”] = data[“latitude”].astype(float) data[“longitude”] = data[“longitude”].astype(float)
# Create geometry geometry = [Point(xy) for xy in zip(data[“longitude”], data[“latitude”])]
# Geo Dataframe geo_df = gpd.GeoDataFrame(data, crs=crs, geometry=geometry)
# Create ID for species species_id = geo_df[“primary_label”].value_counts().reset_index() species_id.insert(0, ‘ID’, range(0, 0 + len(species_id)))
species_id.columns = [“ID”, “primary_label”, “count”]
# Add ID to geo_df geo_df = pd.merge(geo_df, species_id, how=”left”, on=”primary_label”)
# === PLOT === fig, ax = plt.subplots(figsize = (16, 10)) world_map.plot(ax=ax, alpha=0.4, color=”grey”)
palette = iter(sns.hls_palette(len(species_id))) for i in range(len(species_list)): geo_df[geo_df[“ID”] == i].plot(ax=ax, markersize=20, color=next(palette), marker=”o”, label = species_id[‘primary_label’].values[i]);
ax.legend() |
Waveplotsの可視化
| import matplotlib.pyplot as plt import librosa.display plt.figure(figsize=(14, 5)) librosa.display.waveplot(x, sr=sr) |
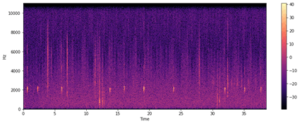
Spectrogramの可視化
| X = librosa.stft(x) Xdb = librosa.amplitude_to_db(abs(X)) plt.figure(figsize=(14, 5)) librosa.display.specshow(Xdb, sr=sr, x_axis=’time’, y_axis=’hz’) plt.colorbar() |

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト