
前回はkaggleコンペの「メルカリにおける値段推定」の1位の解析手法を話しました。内容が長いなので、3つの記事に分けました。今回は「Home Credit Default Risk 債務不履行の予測」の特徴量エンジニアリングについて書きます。
目次
1. Home Credit Default Riskのコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の特徴量エンジニアリング
___2.1 特徴量生成
___2.2 カテゴリカル特徴量の処理
___2.3 特徴量選択
3. 1位のモデル作成
___3.1 3.1 Base Models
___3.2 アンサンブル学習(Ensemble learning)
___3.3 その他
2. 1位の特徴量エンジニアリング
1位のコメントにより、特徴量設計をまとめます。
https://www.kaggle.com/c/home-credit-default-risk/discussion/64821
この競争に適したモデルを構築するには、次の2つのことが重要です。
1. 賢くて正しい特徴量セット。 2.多様なアルゴリズムベース
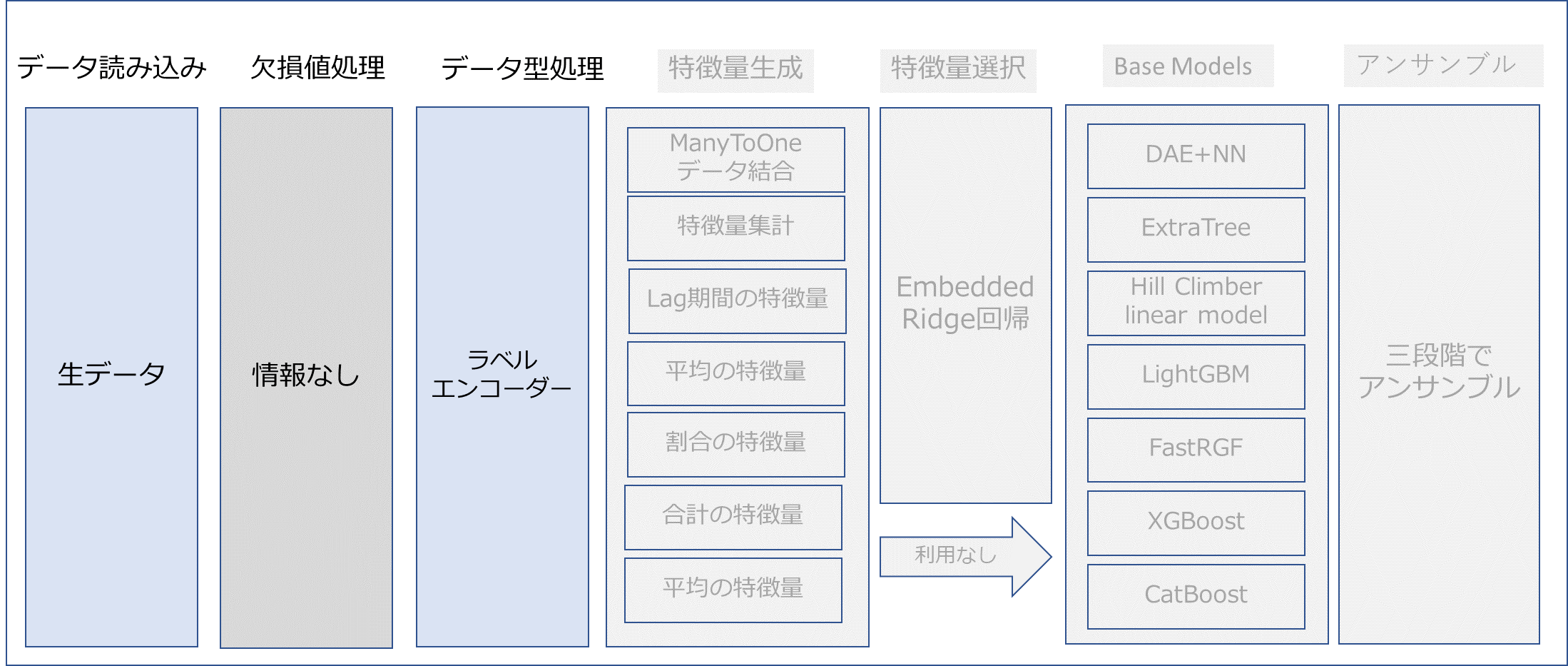
2.1 特徴量生成
・データが異質であり、異なる期間のデータや多くのデータソースなので、かなりの前処理が必要です。
・様々な特徴量はManyToOneの結構で集計しての表を作成しました。約700の特徴量になりました。
・複数の特徴量を試しまして、EXT_SOURCE_3でapplicationを割ったのは効果がありました。
・Previous_application.csvの最後の 3, 5番目の特徴量と最初の2, 4番目の特徴量のapplicationsについてそれぞれ集計は一番良いスコアになりました。
・Installment_payments.csvの集計は、最後の2,3,5のpayments、NUM_INSTALMENT_NUMBER が 1, 2, 3, 4の installments、DAYS_INSTALMENT最後が60, 90,180,365のものをフィルタリングして集計、past dueはDAYS_ENTRY_PAYMENT と DAYS_INSTALMENTの間が0より大きい物を1、そうでないものを0としました。
・POS_CASH_balance.csv, credit_card_balance.csvについてはInstallment_payments.csvと同様に集計を行った
・SKIDCURR は最終5回までのprevious applicationをlag特徴量として利用しました。
・年利は一番良いスコアになりました。
・3種類のexternal sourcesとcredit/annuity ratioで近傍500個でのtargetの平均を利用しました。
・SK_ID_CURRでgroup by してAMT_CREDIT_SUM_DEBTの合計をAMT_CREDIT_SUMの割合を計算しました。
・creditannuityratio: AMTCREDIT / AMTANNUITYの割合
・credit_goods_price_ratio:AMT_CREDIT / AMT_GOODS_PRICEの割合
・credit_downpayment:AMT_GOOD_PRICE – AMT_CREDITの差異
・prev_PRODUCT_COMBINATION:一番直近の応募の特徴量
・last_active_DAYS_CREDIT:SK_ID_CURRでgroup byした最も最近のactiveなDAYS CREDIT
・AGE_INT:int(DAYS_BIRTH / -365)の期間
・Installment_payment_ratio_1000_mean_mean:installment paymentsの中でDAYS_INSTALLMENT>-1000のものだけ取り出し、AMT_PAYMENT – AMT_INSTALMENTの平均。最初にSK_ID_PREVでgroup byし、次にSK_ID_CURRでgroup byした
annuity_to_max_installment_ratio:AMT_ANNUITY / (installments_paymentsをSK_ID_CURRでgroup byしたのち、最大のinstallment)
・DAYS_CREDIT_meanから、bureauにあるCREDIT_DAYSをSK_ID_CURRでgroupbyした平均
・open solutionにもあるlast, 3, 5, 10番目のcredit card, installment, and posを利用します。
・annuity, credit, and paymentとtime periodの重みと重み付き平均の特徴量を利用します。
・income, payment and timeから複数のKPI指標を作成しました。
2.2 カテゴリカル特徴量の処理
・カテゴリカル特徴量をラベルエンコーディングした(label encoder)のがさらにより良いスコア上昇になりました。全てのapplication_trainとprevious_applicationの最後のapplicationのカテゴリカル特徴量はラベルエンコーディングしました。
LabelEncoderは、ラベルを0~クラスの種類数n-1の値に変換してくれます。LabelEncoderで1つの変数の離散値として扱う場合は、決定木分析、ランダムフォレストなどの分析と相性が良さそうです。
Sklearnのラベルエンコーダーの詳細:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
・SK_ID_PREV & SK_ID_BUREAUの集計だけではなく、異なるのータセットの集計しました。
2.3 特徴量選択
・様々な特徴量集計から1000以上の特徴量を作成したが、多いと余分であったりノイズになったりします。
・カテゴリカル特徴量をFrequency Encodingで変換してRidge回帰による前進選択により選択した。
Ridge回帰は一つのEmbedded Methodの変数選択です。Embedded Methodは機械学習アルゴリズムの中で変数選択も同時に行ってくれる方法のことです。 具体的には、Lasso回帰, Ridge回帰, Regularized trees, Memetic algorithm, Random multinomial logitなどがあります。
SklearnのRidge回帰
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
・1600の特徴量から240まで特徴量が削減できました。そして、特徴量を追加して287の特徴量になりました。(0.802-0.803のCVスコア)
・最後に特徴量を追加して1800-2000の特徴量になりました。締め切りが近づいていますので、特徴量選択なし、2000くらいの特徴量を利用します。
<< ①Home Credit Default Riskのコンペの概要