
今回の記事はPythonのsklearnでランク学習を解説します。
目次
1. ランク学習とは
2. ランク学習のアプローチ
1. ランク学習とは
ランク学習は英語では ”Learning to rank” といってLTRの略称、または ”Machine-learned rankingといってMLRとよく省略されます。ランク学習は一般に教師あり、半教師あり、または強化学習を用いてランキング問題を解く方法です。たとえば、どこかの検索エンジンでキーワードを入力して、これらのウェブページをどういう順番で表示するのが良いのかを学習するのがランク学習になります。ランク学習を利用することで、検索エンジンではユーザーに見られる確率が高いページを上位に表示したり、ショッピングサイトではおすすめの商品を提示することができるようになります。
ランク学習機械学習と別の機械学習の違い
– LTRの入力データはアイテムのリストです。LTRの目的は、これらのアイテムの最適な順序を見つけることです。
– LTRのアイテムが正確なスコアより、アイテム間の相対的な順序のほうが大切です。
2. ランク学習のアプローチ
ポイントワイズアプローチ(Pointwise Approach)
ポイントワイズアプローチの入力データには、各単一ドキュメントの特徴ベクトルが含まれています。 出力スペースには、個々のドキュメントの関連度が含まれます。 関連度の観点から、さまざまな種類の判断をグラウンドトゥルースラベルに変換できます。
ペアワイズアプローチ(Pairwise Approach)
ペアワイズアプローチの入力データには、特徴ベクトルで表されるドキュメントのペアが含まれています。 出力スペースには、ドキュメントの各ペア間のペアワイズ設定({+ 1、-1}から値を取得)が含まれます。 さまざまな種類の判断は、ペアワイズ設定の観点からグラウンドトゥルースラベルに変換できます。
リストワイズアプローチ(Listwise Approach)
リストワイズアプローチの入力データには、クエリに関連付けられたドキュメントのセットが含まれます。リスト方式の出力スペースには、ドキュメントのランク付けされたリスト(または順列)が含まれます。 ランク付けされたリストの観点から、さまざまな種類の判断をグラウンドトゥルースラベルに変換できます。
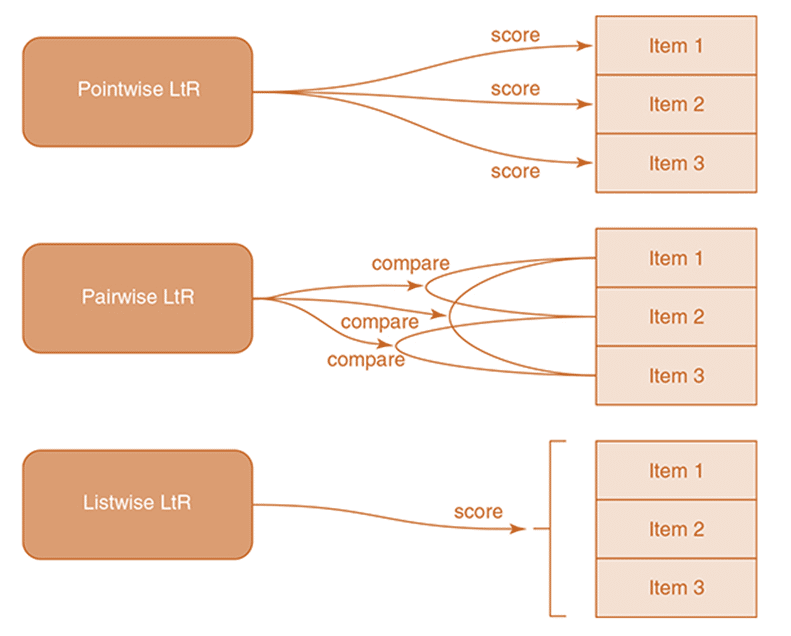
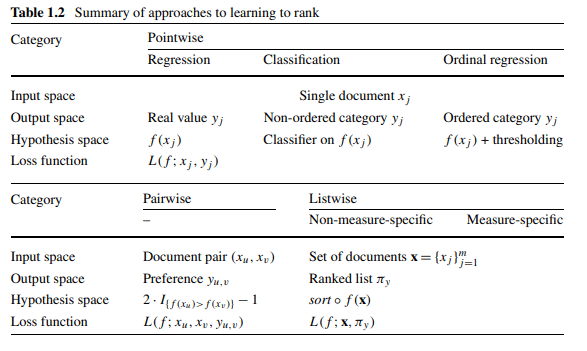
論文:”Learning to Rank for Information Retrieval”、Tie-Yan Liu of Microsoft Research Asia
https://www.cda.cn/uploadfile/image/20151220/20151220115436_46293.pdf