
データを分析する上で、通常は複数のDataFrameを組み合わせすることが必要です。今回は【PySparkでのデータ結合】を説明します。
Union
同じ列を持つDataFrame同士を結合する方法です。
PySparkのデータ結合
unionallでspf1とspf2を結合し、sdf3を作成します。
# PySpark
sdf1 = spark.createDataFrame([('a1', 10),('a2', 20),('a3', 30)],["c1", "c2"])
sdf2 = spark.createDataFrame([('a1', 100),('a2', 200)],["c1", "c2"])
sdf3 = sdf1.unionAll(sdf2)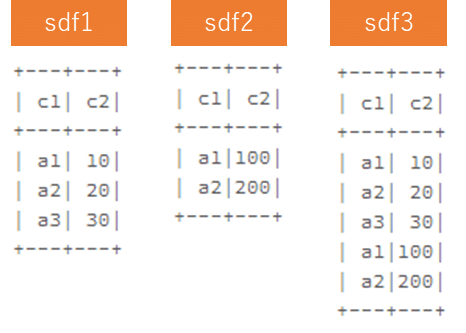
pandasのappend
2つのDataFrame pdf1、pdf2をUnionで結合し、pdf3を作成します。ignore_indexにはTrueを指定して、新たにindexを振り直します。
# Python Pandas import pandas as pd pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["c1", "c2"]) pdf2 = pd.DataFrame([['a1', 100],['a2', 200]], columns=["c1", "c2"]) pdf3 = pdf1.append(pdf2, ignore_index=True)

pandasのconcat
2つのDataFrame pdf1、pdf2をUnionで結合し、pdf4を作成します。
# Python Pandas pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["c1", "c2"]) pdf2 = pd.DataFrame([['a1', 100],['a2', 200]], columns=["c1", "c2"]) pdf3 =pd.concat([pdf1,pdf2],ignore_index=True)

データのJOIN
PySparkのinner join
inner joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# PySpark
sdf1 = spark.createDataFrame([('a1', 10),('a2', 20),('a3', 30)],["key", "c2"])
sdf2 = spark.createDataFrame([('a1', 100),('a2', 200),('a4', 300)],["key", "c3"])
sdf3 = sdf1.join(sdf2, ['key'],'inner')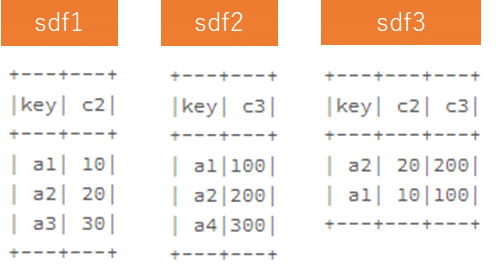
PySparkのleft outer join
left outer joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# PySpark pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["c1", "c2"]) pdf2 = pd.DataFrame([['a1', 100],['a2', 200]], columns=["c1", "c2"]) sdf3 = sdf1.join(sdf2, ['key'],'left_outer')
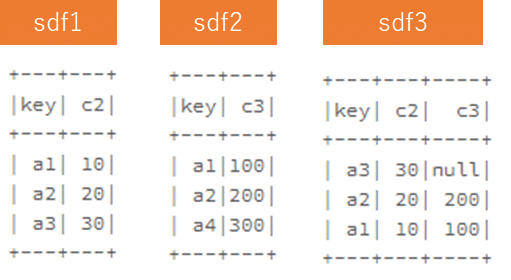
PySparkのright outer join
right outer joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# PySpark pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["c1", "c2"]) pdf2 = pd.DataFrame([['a1', 100],['a2', 200]], columns=["c1", "c2"]) sdf3 = sdf1.join(sdf2, ['key'],'right_outer')
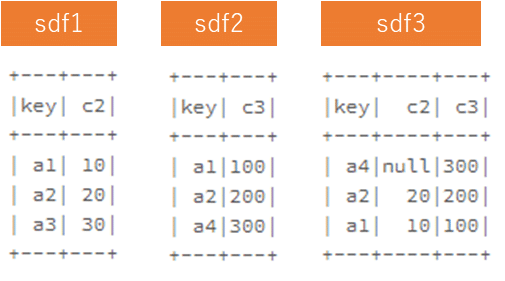
Pandasのinner join
mergeでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# Pandas import pandas as pd pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["key", "c2"]) pdf2 = pd.DataFrame([['a1', 100],['a2', 200],['a4', 300]], columns=["key", "c3"]) pdf3 = pd.merge(pdf1,pdf2)

Pandasのinner join
inner joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# Pandas
pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["key", "c2"])
pdf2 = pd.DataFrame([['a1', 100],['a2', 200],['a4', 300]], columns=["key", "c3"])
pdf3 = pdf1.join(pdf2.set_index('key'), on='key', how=’inner’)
Pandasのleft outer join
left joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# Pandas
pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["key", "c2"])
pdf2 = pd.DataFrame([['a1', 100],['a2', 200],['a4', 300]], columns=["key", "c3"])
pdf3 = pdf1.join(pdf2.set_index('key'), on='key', how='left')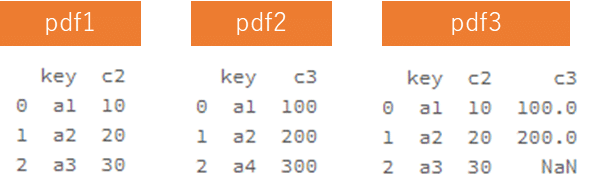
Pandasのright outer join
right joinでsdf1とsdf2の共通の同じ列名(key)で結合し、sdf3を作成します。
# Pandas
pdf1 = pd.DataFrame([['a1', 10],['a2', 20],['a3', 30]], columns=["key", "c2"])
pdf2 = pd.DataFrame([['a1', 100],['a2', 200],['a4', 300]], columns=["key", "c3"])
pdf3 = pdf1.join(pdf2.set_index('key'), on='key', how='right')