
前回の記事はアルゴリズム評価を解説しました。
今回はクラスタリングのアルゴリズム評価するFMIを解説します。
FMI (Fowlkes-Mallows index)とは
The Fowlkes-Mallows 指標 または、Fowlkes-Mallows スコアはクラスタリングのアルゴリズム評価する方法です。2つのクラスタリングアルゴリズムの結果間の類似性を判断するために使用されるこの方法。さらに、クラスタリングアルゴリズムの結果と実際のラベルも使われます。FMIの形式は下記になります。

TPは真陽性の数です。つまり、真のラベルと予測ラベルの両方で同じクラスターに属するポイントの数です。
FPはFalse Positiveの数です。予測ラベルではなく、真のラベルの同じクラスターに属するポイントの数です。
FNはFalse Negativeの数です。真のラベルではなく、予測ラベルの同じクラスター内です。
スコアの範囲は0〜1です。高い値は、2つのクラスター間の類似性が高いと示します。
今回は、ラベルがあるクラスタリング方法の評価をしていきます。
FMIのサンプル
データセット:digitデータ 8×8の画像が1797枚(0〜9のラベル)
クラスターアルゴリズム: K-Means, MeanShift
モデル評価:FMI (Fowlkes-Mallows index)
ライブラリの読み込む
import numpy as np import pandas as pd import os import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm_notebook from sklearn import datasets from sklearn.cluster import KMeans from sklearn import metrics
データロード
data = datasets.load_digits() X, y = data.data, data.target X.shape, y.shape
((1797, 64), (1797,))
plt.figure(figsize=(10, 4)) for i in range(10): plt.subplot(2, 5, i + 1) plt.imshow(X[i,:].reshape([8,8]), cmap='gray');

sns.countplot(y)
K-means
# Fitting K-Means to data output = pd.DataFrame(index=['K-Means'], columns=['FMI']) clust_model = KMeans(n_clusters=10, random_state=17) clust_model.fit(X) # Evaluating model's performance labels = clust_model.labels_ output.loc['K-Means','FMI'] = metrics.fowlkes_mallows_score(y, labels)
図作成
d = {'y':y, 'labels':labels}
df = pd.DataFrame(d)
sns.set(rc={'figure.figsize':(10,8)})
confusion_matrix = pd.crosstab(df['y'], df['labels'], rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(confusion_matrix, annot=True,cmap='Blues', fmt='g')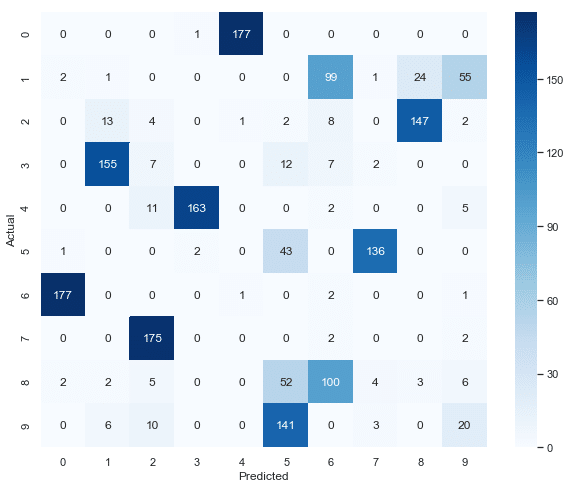
output[:'K-Means']
FMI K-Means 0.702149
MeanShift
result = [] for bw in tqdm_notebook(np.linspace(5,50,10)): clust_model = MeanShift(bandwidth=bw) clust_model.fit(X) labels = clust_model.labels_ result.append(metrics.adjusted_rand_score(y, labels)) res = pd.DataFrame(index=np.linspace(5,50,10)) res['Score'] = result
clust_model = MeanShift(bandwidth=26) clust_model.fit(X) # Evaluating model's performance labels = clust_model.labels_ output.loc['Mean-Shift','FMI'] = metrics.fowlkes_mallows_score(y, labels)
d = {'y':y, 'labels':labels}
df = pd.DataFrame(d)
sns.set(rc={'figure.figsize':(10,8)})
confusion_matrix = pd.crosstab(df['y'], df['labels'],
rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(confusion_matrix, annot=True,cmap='Blues', fmt='g')
output
FMI
K-Means 0.702149
Mean-Shift 0.691674
まとめ
今回はThe Fowlkes-Mallows 指標を解説しました。scikit-learnでdigitデータをFMIを計算しました。
K-MeansはMean-ShiftよりFMIが高くK-Meansのクラスター結果のほうが、優れたアルゴリスになります。
詳細: