
前回記事の過去のkaggleコンペの「Cdiscountの画像分類チャレンジ」のデータ概要を話しました。今回の記事はCdiscountの1位のやり方について解説していきます。
目次
1. 「Cdiscountの画像分類チャレンジ」のコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の解説の環境準備とデータ処理
___2.1 特徴量生成
___2.2 解析方法のサマリー
___2.3 大きなデータセットの準備
3. 1位のモデルの解説
___3.1 学習済みモデルの調整
___3.2複数枚の画像データセットを利用
___3.3 OCRデータの追加
___3.4そのたの方法
___3.5 restnetモデルのコード
public leaderboardの1位はbestfittingさんです。
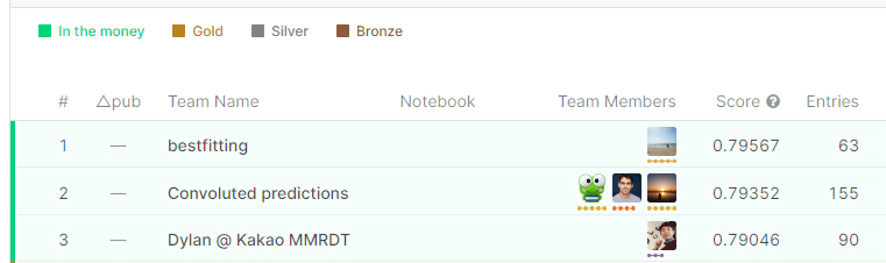
2020/02時点でbestfittingはKaggle Rankingsに一位になっています。3年前初めて参加しましたが、26個の金メダルを獲得しています。

1位のコメントにより、特徴量設計をまとめます。
https://www.kaggle.com/c/cdiscount-image-classification-challenge/discussion/45863
問題点としては、以下になります。
1.1500万以上の画像と5000以上のカテゴリを持つ大規模なデータセット。
2.一部の製品と1-4枚の画像
3.CD/BOOKは分類が非常に困難
4.全体の精度も最高で0.8になると推定しました。多くの方法を選択でき、改善する余地が大きいため、勝つのは非常に困難
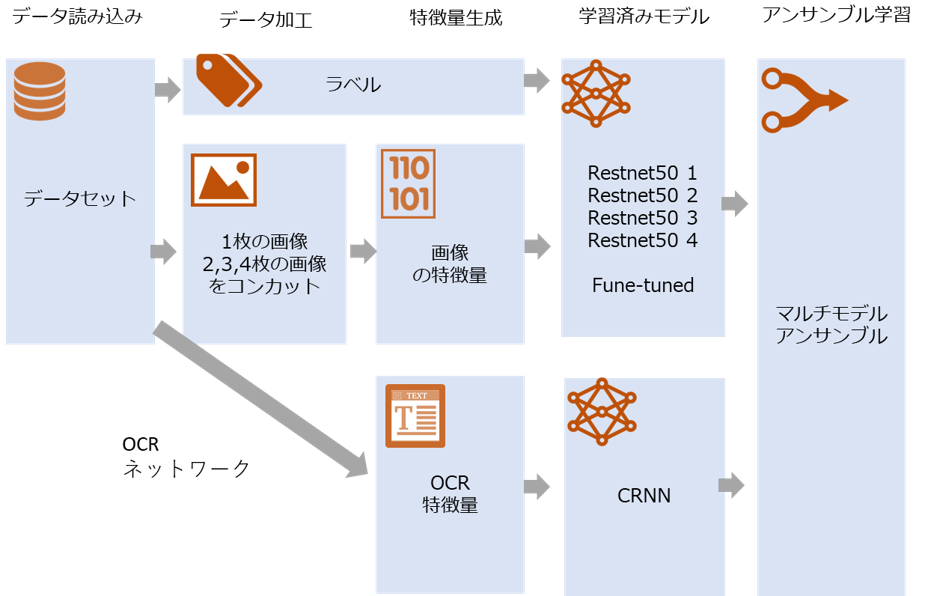
解析方法のサマリー
全体の解析方法は下記になります。
1.大きなデータセットの準備
2.学習済みモデルの微調整(0.759 / 0.757、inception-resnet-v2,0.757 / 0.756 resnet50)
3.。 複数枚の画像データセットを利用(0.772 / 0.771 inception-resnet-v2および0.769 / 0.768 + Resnet50モデル)
- OCRを使用して、モデルにセマンティクスを追加します。
1.大きなデータセットの準備
最初の4日はpytorchの効率的なニューラルネットワークを作成しました。モデルを保存するため、512M SSDメモリーを利用しました。40Mのsparse matrixのデータを保存できるようになりました。
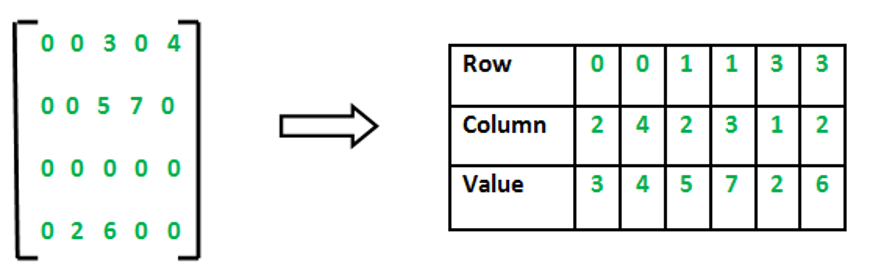
SparseMatrixとはNon-zero Value(0以外の数値)の数がベクトルの長さに対して極めて小さい場合に利用されることが多いです。SparseMatrixの特長は消費するメモリの量が少なくなり、また行列・ベクトル演算のスピードが高速にります。
SparseMatrixの例:
詳細は下記になります。
Pingback: kaggle1位の解析手法 「Cdiscountの画像分類チャレンジ」1コンペの概要 - S-Analysis
Pingback: kaggle1位の解析手法 「Cdiscountの画像分類チャレンジ」3 モデルの解説 - S-Analysis