今回のkaggle1位の解析手法のシリーズはKaggleでよく行われる画像分類コンペについて話したいと思います。過去のコンペの「Cdiscountの画像分類チャレンジ」の解析方法を解説します。最初の記事はCdiscountのコンペ概要とデータ理解を紹介します。
目次
1. 「Cdiscountの画像分類チャレンジ」のコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の解説の環境準備とデータ処理
___2.1 特徴量生成
___2.2 解析方法のサマリー
___2.3 大きなデータセットの準備
3. 1位のモデルの解説
___3.1 学習済みモデルの調整
___3.2複数枚の画像データセットを利用
___3.3 OCRデータの追加
___3.4そのたの方法
___3.5 restnetモデルのコード
1. 「Cdiscountの画像分類チャレンジ」のコンペの概要
1.1 コンペの概要

Cdiscountは1999年に設立され、2011年にはフランスで最大のeコマースプラットフォームとなりました。Cdiscountは生鮮食品の販売だけでなく、電気製品、衣料、家庭用品などのすべてのカテゴリを取り揃えています。このコンペは製品の画像をカテゴリ分類するアルゴリズムを作成したいです。
データセットの特徴:
・一つの製品は複数画像がある
・ほぼ900万の製品:現在のカタログの半分
・180×180の解像度で1500万枚以上の画像
・5000以上のカテゴリ
目的:
このコンペの目的は、画像に基づいて製品のカテゴリを予測することです。 製品には、1つまたは複数の画像があります。 テストセットのすべての製品IDを正しいカテゴリを予測することです。
メトリック
Accuracy(正しい製品の割合)で評価されます。
賞金: 1位20,000米ドル、2位10,000米ドル、3位5,000米ドル
期間: 2018/09/14 ~ 2018/12/14
参加チーム数:626
1.2 データセットの概要
BSON拡張子ファイル
BSON拡張子はBinary JSONで、主にMongoDBのデータストレージ及びネットワーク転送フォーマットとして利用されている、データ交換フォーマットである。
train.bson – (Size: 58.2 GB)
7,069,896個の辞書のリスト、製品ごとに1つのデータが含まれます。バイナリ文字列は、JPEG形式の画像のバイナリ表現に対応しています。
{‘picture’: b’…binary string…’}
train_example.bson
このデータセットにはtrain.bsonの最初の100レコードが含まれているため、セット全体をダウンロードする前にデータを確認することができます。
test.bson – (Size: 14.5 GB)
train.bsonと同じ形式でcategory_idが含まれていない1,768,182製品のデータです。
category_names.csv
製品分類の階層を示しています。 各category_idには、フランス語で対応するlevel1、level2、およびlevel3の名前があります。
sample_submission.csv
sample_submission.csv: サンプルファイルです。このフォーマットのcsvファイルを作成して投稿します。

1.3 データの理解
ライブラリインポート
import numpy as np # 配列処理 import pandas as pd # データフレーム処理 import io # ファイル処理 import bson # pymongのbson処理 import matplotlib.pyplot as plt # 可視化 from skimage.data import imread # 画像処理 import multiprocessing as mp #並列処理
ファイルを確認
print(check_output(["ls", "../input"]).decode("utf8"))
category_names.csv
sample_submission.csv
test.bson
train.bson
train_example.bsonデータ読み込
data = bson.decode_file_iter(open('../input/train_example.bson', 'rb'))
prod_to_category = dict()
for c, d in enumerate(data):
product_id = d['_id']
category_id = d['category_id'] # This won't be in Test data
prod_to_category[product_id] = category_id
for e, pic in enumerate(d['imgs']):
picture = imread(io.BytesIO(pic['picture']))
prod_to_category = pd.DataFrame.from_dict(prod_to_category, orient='index')
prod_to_category.index.name = '_id'
prod_to_category.rename(columns={0: 'category_id'}, inplace=True)
prod_to_category.head()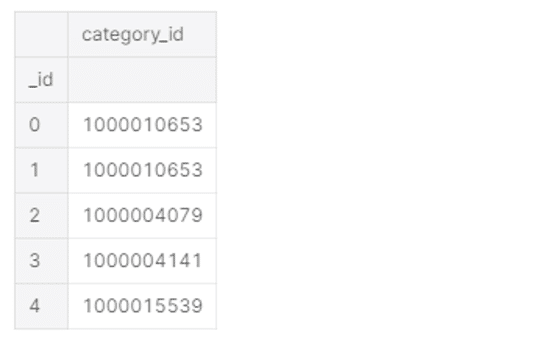
画像データを表示します。
plt.imshow(picture);
複数のコアを利用するコード
# コア数を設定
NCORE = 8
prod_to_category = mp.Manager().dict() #
def process(q, iolock):
while True:
d = q.get()
if d is None:
break
product_id = d['_id']
category_id = d['category_id']
prod_to_category[product_id] = category_id
for e, pic in enumerate(d['imgs']):
picture = imread(io.BytesIO(pic['picture']))
q = mp.Queue(maxsize=NCORE)
iolock = mp.Lock()
pool = mp.Pool(NCORE, initializer=process, initargs=(q, iolock))
# ファイル処理
data = bson.decode_file_iter(open('../input/train_example.bson', 'rb'))
for c, d in enumerate(data):
q.put(d) # blocks until q below its max size
# ワーカーの終了
for _ in range(NCORE):
q.put(None)
pool.close()
pool.join()
# convert back to normal dictionary
prod_to_category = dict(prod_to_category)
prod_to_category = pd.DataFrame.from_dict(prod_to_category, orient='index')
prod_to_category.index.name = '_id'
prod_to_category.rename(columns={0: 'category_id'}, inplace=True)カテゴリのデータを確認
5270のユニークのカテゴリ
49のユニークなレベル1カテゴリー
483のユニークのレベル2カテゴリ
5263ユニークなレベル3カテゴリ
print("Unique categories: ", len(CATEGORY_NAMES_DF['category_id'].unique()))
print("Unique level 1 categories: ", len(CATEGORY_NAMES_DF['category_level1'].unique()))
print("Unique level 2 categories: ", len(CATEGORY_NAMES_DF['category_level2'].unique()))
print("Unique level 3 categories: ", len(CATEGORY_NAMES_DF['category_level3'].unique()))Unique categories: 5270
Unique level 1 categories: 49
Unique level 2 categories: 483
Unique level 3 categories: 5263
gb = CATEGORY_NAMES_DF.groupby('category_level3')
cnt = gb.count()
cnt[cnt['category_id'] > 1]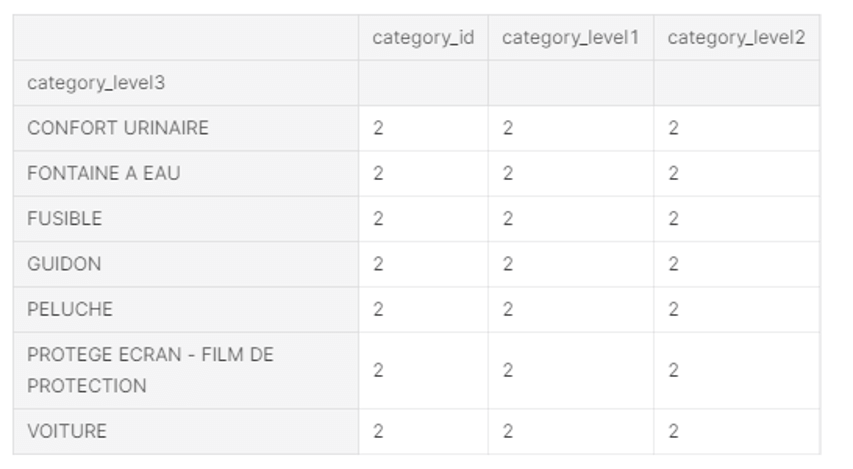
カテゴリーの確認
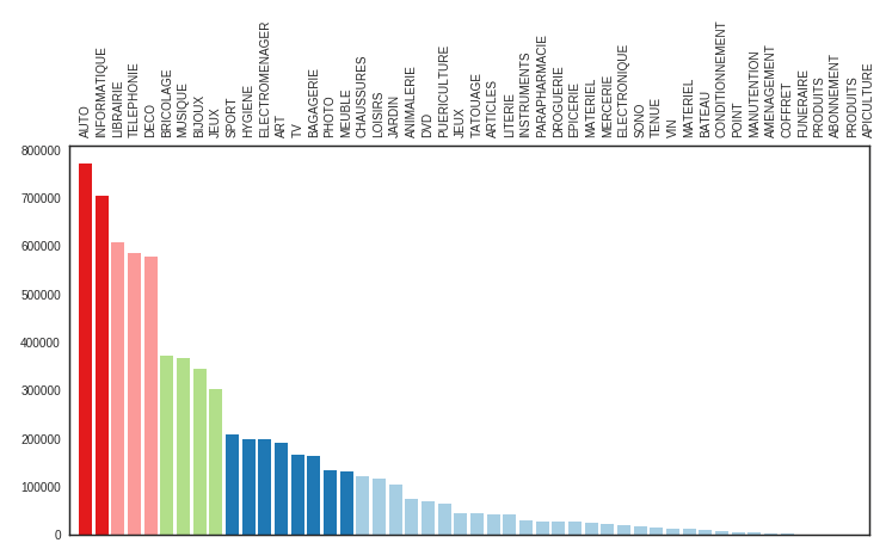
AUTO、INFORMATIQUE, LIBRAIRIEはトップ3カテゴリーになっています。
import seaborn as sns
sns.set_style('white')
fig,ax = plt.subplots(1,figsize=(12,6))
pal = ListedColormap(sns.color_palette('Paired').as_hex())
colors = pal(np.interp(cats,[cats.min(),cats.max()],[0,1]))
bars = ax.bar(range(1,len(cats)+1),cats,color=colors);
ax.set_xticks([]);
ax.set_xlim(0,len(cats))
ax1 = plt.twiny(ax)
ax1.set_xlim(0,len(cats))
ax1.set_xticks(range(1,len(abbriv)+1,1));
ax1.set_xticklabels(abbriv.values,rotation=90);
# sns.despine();