関連記事: 深層学習
前回の記事は「KerasでのData Augmentationの解説」画像のデータ拡張について解説しました。今回の記事はテーブルデータ拡張するT-GANについて解説したいと思います。
目次
1. T-GANの概要
__1.1 TGANとは
__1.2 モデルパのラメータ
2. 実験・コード
__2.1 データロード
__2.2 ライブラリの設定
__2.3. 前処理
__2.4. モデルを訓練
__2.5. 前処理
__2.6. サンプル作成
3. サンプルデータ確認
__3.1 モデルテストの関数
__3.2 モデル検証
1. T-GANの概要
1.1 TGANとは
TGANまたは、table-GANは、Table Generative Adversarial Networkの略称です。敵対的生成ネットワークで数値などの連続変数だけではなく、カテゴリ変数にも対応しています。
ネットワークの構成は下記になります。
テーブルデータから生成モデルを学習して、生成者(Generator)と識別者(Discriminator)を競わせます。
1.2 モデルパのラメータ
tgan = TGANModel(continuous_columns, output=’output’, max_epoch=5, steps_per_epoch=10000, save_checkpoints=True, restore_session=True, batch_size=200, z_dim=200, noise=0.2, l2norm=0.00001, learning_rate=0.001, num_gen_rnn=100, num_gen_feature=100, num_dis_layers=1, num_dis_hidden=100, optimizer=’AdamOptimizer’ )
max_epoch (int, default=100): エポックの数
steps_per_epoch (int, default=10000): 各エポックで実行するステップの数
save_checkpoints(bool, default=True): モデルのチェックポイントの設定
restore_session(bool, default=True): 最後のチェックポイントからトレーニングを継続するかどうか
batch_size (int, default=200): バッチのサイズ
z_dim (int, default=100): ジェネレーターのノイズ入力の次元数
noise (float, default=0.2): カテゴリカル列に追加されたガウスノイズの上限
l2norm (float, default=0.00001): 損失を計算するときのL2正規化係数
learning_rate (float, default=0.001): オプティマイザの学習率
num_gen_rnn (int, default=400): ジェネレーターのrnnセルのユニット数
num_gen_feature (int, default=100): ジェネレーターの完全に接続されたレイヤーのユニット数
num_dis_layers (int, default=2):ディスクリミネータのレイヤー数
num_dis_hidden (int, default=200): ディスクリミネータのレイヤーあたりのユニット数
optimizer (str, default=AdamOptimizer): 適合中に使用するオプティマイザーの名前。可能な値は次のとおりです:[GradientDescentOptimizer、AdamOptimizer、AdadeltaOptimizer]
2. 実験・コード
概要:
入力データ: Video Game Sales with Ratings
https://www.kaggle.com/rush4ratio/video-game-sales-with-ratings
環境:Google Colab GPU
ライブラリ: tgan
実験:tganでテーブルデータ拡張
2.1 データロード
Kaggle からのデータをロード
import os os.environ['KAGGLE_USERNAME'] = "xxx" # username from the json file os.environ['KAGGLE_KEY'] = " xxx " # key from the json file !kaggle datasets download -d rush4ratio/video-game-sales-with-ratings # api copied from kaggle #zipファイルを開放して削除する !unzip \*.zip && rm *.zip
2.2 ライブラリの設定
!pip install tgan
ライブラリのインポートとパラメータ設定
# データ処理
import os
import numpy as np
import pandas as pd
from datetime import datetime
import warnings
warnings.filterwarnings("ignore")
# モデル
from tgan.model import TGANModel
from lightgbm import LGBMRegressor
# データロード
from sklearn.model_selection import train_test_split
# 検定
from sklearn.metrics import mean_squared_error
from math import sqrt
# 可視化
import matplotlib.pyplot as plt
# パラメーター設定
SEED = 11
result = {}2.3. 前処理
# データの読み込み
df = pd.read_csv('Video_Games_Sales_as_at_22_Dec_2016.csv')
print(df.shape)
df.head()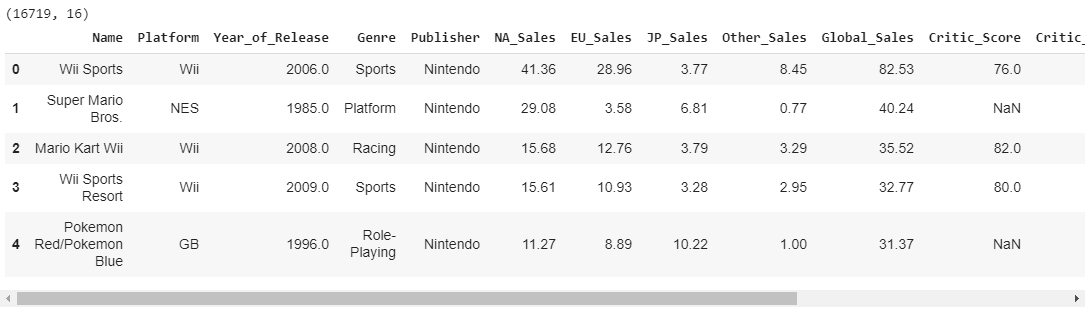
学習データのために、カラムを選択する
filtered_df = df[['Platform', 'Year_of_Release', 'Genre', 'Publisher', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count', 'Developer', 'Rating', 'Global_Sales']] filtered_df.head()

欠損値の確認
評価のスコアは欠損値が多いと確認しました。
# 欠損値の確認 filtered_df.isnull().sum()

欠損値の処理
色んな欠損値処理の方法があります。今回は欠損値があるサンプルデータを削除します。6千件くらいになりました。
# 欠損値の処理 processed_df = filtered_df.dropna() print(processed_df.shape)
(6825, 11)
データ型変更
‘Year_of_Release’のカラムをstring型に変更します。
# データ型の変更 processed_df['Year_of_Release'] = processed_df['Year_of_Release'].astype(str) processed_df.dtypes
モデルを作成するために、連続変数の指定します。
# カラム名の保持 df_columns = processed_df.columns # 連続変数の指定 continuous_columns = [processed_df.columns.get_loc(c) for c in processed_df.select_dtypes(include=['float']).columns]
2.4. モデルを訓練
start_time = datetime.now()
tgan = TGANModel(continuous_columns, batch_size=50)
tgan.fit(processed_df)
result[('TGAN', 'model_fit_time')] = datetime.now() - start_time
モデルを保存します。
モデル学習時間は12分で48MB モデルファイルを作成しました。
# モデル保存
start_time = datetime.now()
model_path = '/models/tgan_model.pkl'
tgan.save(model_path)
result[('TGAN', 'saving_time')] = datetime.now() - start_time
result[('TGAN', 'file_size_MB')] = int(os.path.getsize(model_path)/ (1024 * 1024))
# 結果
result_df = pd.Series(result).unstack()
result_df
2.6. サンプル作成
モデルロード
# モデルロード model_path = '/models/tgan_model.pkl' tgan = TGANModel.load(model_path)
1)万件のサンプル
# 1)万件
# サンプル作成
start_time = datetime.now()
num_samples = 10000
samples = tgan.sample(num_samples)
result[('1_csv_10K', 'predicting_time')] = datetime.now() - start_time
# csvファイルを保存
start_time = datetime.now()
output_path = 'output/csv1_10K.csv'
samples.to_csv(output_path)
result[('1_csv_10K', 'saving_time')] = datetime.now() - start_time
# ファイルサイズ
result[('1_csv_10K', 'file_size_MB')] = int(os.path.getsize(output_path)/ (1024 * 1024))
# モデル評価
result_df = pd.Series(result).unstack().reindex(columns=['model_fit_time', 'predicting_time','saving_time', 'file_size_MB'])
result_df
2)10万件のサンプル
# 2)10万件
# サンプル作成
start_time = datetime.now()
num_samples = 100000
samples = tgan.sample(num_samples)
result[('2_csv_100K', 'predicting_time')] = datetime.now() - start_time
# csvファイルを保存
start_time = datetime.now()
output_path = 'output/csv2_100K.csv'
samples.to_csv(output_path)
result[('2_csv_100K', 'saving_time')] = datetime.now() - start_time
# ファイルサイズ
result[('2_csv_100K', 'file_size_MB')] = int(os.path.getsize(output_path)/ (1024 * 1024))
# モデル評価
result_df = pd.Series(result).unstack().reindex(columns=['model_fit_time', 'predicting_time','saving_time', 'file_size_MB'])
result_df
3)100万件のサンプル
サンプルデータ作成時間とデータサイズは直線の関係になっています。
# 3)100万件
# サンプル作成
start_time = datetime.now()
num_samples = 1000000
samples = tgan.sample(num_samples)
result[('3_csv_1M', 'predicting_time')] = datetime.now() - start_time
# csvファイルを保存
start_time = datetime.now()
output_path = 'output/csv3_1M.csv'
samples.to_csv(output_path)
result[('3_csv_1M', 'saving_time')] = datetime.now() - start_time
# ファイルサイズ
result[('3_csv_1M', 'file_size_MB')] = int(os.path.getsize(output_path)/ (1024 * 1024))
# モデル評価
result_df = pd.Series(result).unstack().reindex(columns=['model_fit_time', 'predicting_time','saving_time', 'file_size_MB'])
result_df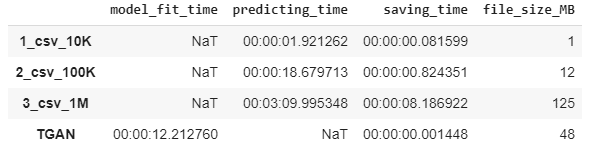
3. サンプルデータ確認
一万件のデータ、十万のデータ、百万件のデータでlightGBMを作成してみます。
RMSEの評価のスコアを比較します。
3.1 モデルテストの関数
def lightGBM_test(csv_list, y_col, category_col):
"""
Return test lightGBM test result
Input csv list
"""
for csv in csv_list:
# データの読み込み
df = pd.read_csv('output/' + csv + '.csv')
print(csv)
print(df.shape)
# 学習データとテストデータ作成
X = df.drop(["Global_Sales"], axis=1).copy()
y = pd.to_numeric(df[y_col]).copy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=SEED)
# カテゴリの設定
for col in category_col:
X_train[col] = X_train[col].astype('category')
X_test[col] = X_test[col].astype('category')
# モデル作成
start_time = datetime.now()
lgbm_rg = LGBMRegressor(eval_metric='rmse')
lgbm_rg.fit(X_train, y_train)
# 推論
y_pred_lgem1 = pd.DataFrame(lgbm_rg.predict(X_test))
# 検証
result2[(csv, 'lgbm_RMSE')] = round(sqrt(mean_squared_error(y_test,y_pred_lgem1)),4)
result2[(csv, 'Runtime')] = datetime.now() - start_time3.2 モデル検証
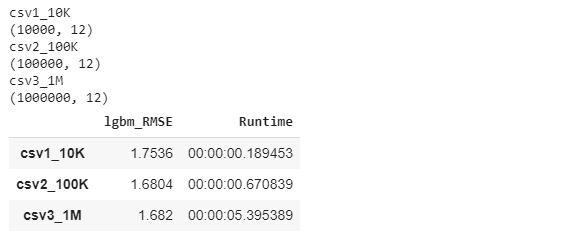
3つのサンプルデータでモデルを作成しました。百万件のサンプルデータのモデルは一番良い精度になっています。
# パラメータ設定
csv_list = ["csv1_10K", "csv2_100K", "csv3_1M"]
y_col = "Global_Sales"
category_col = ["Platform", "Genre", "Publisher", "Developer", "Rating"]
SEED = 2
result2 = {}
# 関数を実行
lightGBM_test(csv_list, y_col, category_col)
# 結果
result_df = pd.Series(result2).unstack().reindex(columns=['lgbm_RMSE', 'Runtime'])
result_df