
今回の記事はヒストグラムベースの特徴の新たなLiteMORTを解説します。
![]()
![]()
![]()
![]()
目次:
1. LiteMORTとは
2. LiteMORTの特徴
3. 実験・コード
__3.1 データ読み込み
__3.2 LiteMORT xgboost lightGBM
__3.3 モデル評価
4. まとめ
1. LiteMORTとは
LiteMORT(A memory efficient gradient boosting tree system on adaptive compact distributions)は、分割の際にヒストグラムを用いていきます。ノイズの多い特徴をよりコンパクトで堅牢に評価します。このアルゴリズムにより、速度が向上し、メモリ使用量が大幅に削減され、精度が維持されます。
LiteMORTの論文
LiteMORT: A memory efficient gradient boosting tree system on adaptive compact distributions
2. LiteMORTの特徴
2.1 適応的なサイズ変更されたビンでの機能の分布。
ヒストグラムのビンは、実際にはさまざまな変数の分布を計算する基礎です。 より洗練されたビンを使用すると、より良い分布パラメーターを取得できます。 一部のビンがより重要な場合は、そのサイズを縮小するか、2つのビンに分割します。 その後のトレーニングで、より良い分割点を得ることができました。
2.2 データソースとメモリを共有する
XGBoost、LightGBM、CatBOOSTなどの機械学習アルゴリズムは、膨大なメモリ要件からボトルネックが発生します。 通常、必要なメモリ量は通常、トレーニングセットサイズの2〜3倍です。 LiteMORTはメモリをデータソースと共有するため、必要なメモリ量は通常、トレーニングセットと同じサイズのためメモリー消費量が少ないメリットがあります。
2.3 暗黙的なマージ(implicit merging)
マージをする際に、重複する値によって非常に多くのメモリーが必要になります。しかしLiteMORTでは、ヒストグラムベースのためデータマージは、非常に高速です。
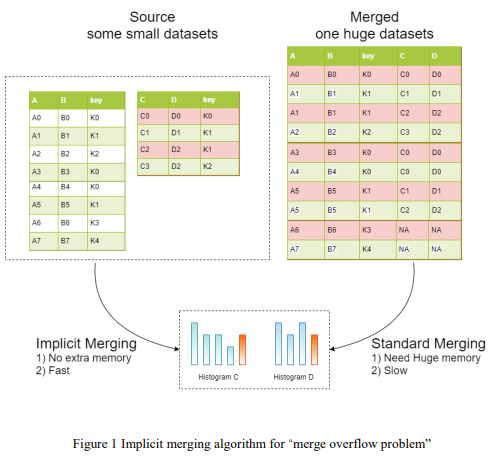
最良の分割ポイントを見つける速度を向上させるために、各特徴量の基準は、ビンのサイズを減らしていきます。 ビンのサイズ変更アルゴリズムを使用して、より多くの位置で分割及び併合していきます。
3. 実験・コード
データセット:sklearnのbreast_cancer
モデル:LiteMORT xgboost lightGBM
モデル評価: AUC
環境:Google Colab (CPU)
環境設定:
ライブラリのインストール
!pip install -i https://test.pypi.org/simple/ litemort==0.1.17
from litemort import *
from itertools import product
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import seaborn as sns
import matplotlib.pyplot as plt
# モデル
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
# 検証
from sklearn.metrics import roc_auc_score
import pandas as pd
from datetime import datetime
import os, sys, gc, warnings, random, time
warnings.filterwarnings('ignore')
SEED = 20
result = {}lightMORTの設定
#isMORT = len(sys.argv)>1 and sys.argv[1] == "mort"
isMORT = True
alg='MORT' if isMORT else 'XGB'
print(f"gradient boosting lib={alg}")3.1 データ読み込み
データを読み込み
data = load_breast_cancer()
#説明変数の表示
dataX = pd.DataFrame(data=data.data,columns=data.feature_names)
print(dataX.head())
#目的変数の表示
dataY = pd.DataFrame(data=data.target)
dataY = dataY.rename(columns={0: 'class'})
print(dataY.head())mean radius mean texture … worst symmetry worst fractal dimension
0 17.99 10.38 … 0.4601 0.11890
1 20.57 17.77 … 0.2750 0.08902
2 19.69 21.25 … 0.3613 0.08758
3 11.42 20.38 … 0.6638 0.17300
4 20.29 14.34 … 0.2364 0.07678
[5 rows x 30 columns]
class
0 0
1 0
2 0
3 0
4 0
データ前処理
# 学習データとテストデータ
X_train, X_test, y_train, y_test = train_test_split(dataX, dataY)
print("X_train :", X_train.shape)
print("y_train :", y_train.shape)
print("X_test :", X_test.shape)
print("y_test :", y_test.shape)X_train : (426, 30)
y_train : (426, 1)
X_test : (143, 30)
y_test : (143, 1)
3.2 LiteMORT, Xgboost
LiteMORT
# LiteMORTモデル
start_time = datetime.now()
start_time = datetime.now()
params={ 'objective': 'binary',
'boosting_type': 'gbdt',
'verbose': 1,
'metric': 'auc',
}
print(f"Call LiteMORT... ")
t0=time.time()
model = LiteMORT(params).fit(X_train,y_train.stack(),eval_set=[(X_test, y_test.stack())])
print(f"LiteMORT......OK time={time.time()-t0:.4g} model={model}")
result[('1_LiteMORT', 'fit_time')] = datetime.now() - start_timeモデル検証
# 検証
y_pred_lmort = model.predict(X_test)
result[('1_LiteMORT', 'auc')] = round(roc_auc_score(y_test,y_pred_lmort),4)
# 結果を表示
result_df = pd.Series(result).unstack().reindex(columns=['auc', 'fit_time'])
result_df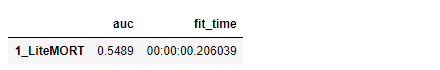
予測の結果
array([1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0,
1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1,
0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0])
XGBモデル作成
xgboost
# モデル作成
start_time = datetime.now()
xgb_cls = XGBClassifier()
xgb_cls.fit(X_train, y_train)
# 推論
y_pred_xgb = pd.DataFrame(xgb_cls.predict(X_test))
# 検証
result[('2_xgboost', 'auc')] = round(roc_auc_score(y_test,y_pred_xgb),4)
result[('2_xgboost', 'fit_time')] = datetime.now() - start_time
In [0]:
# 結果を表示
result_df = pd.Series(result).unstack().reindex(columns=['auc', 'fit_time'])
result_df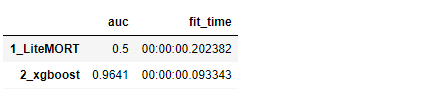
lightGBMモデル作成
lightGBM
# モデル作成
start_time = datetime.now()
lgbm_cls = XGBClassifier()
lgbm_cls.fit(X_train, y_train)
# 推論
y_pred_lgb = pd.DataFrame(lgbm_cls.predict(X_test))
# 検証
result[('3_lightGBM', 'auc')] = round(roc_auc_score(y_test,y_pred_lgb),4)
result[('3_lightGBM', 'fit_time')] = datetime.now() - start_time
In [0]:
# 結果を表示
result_df = pd.Series(result).unstack().reindex(columns=['auc', 'fit_time'])
result_df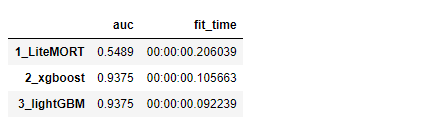
3.3 モデル評価
LiteMORTとxgboostをlightGBMのモデルを作成しました。デフォルトのパラメータにより、LiteMORTは一番遅いし、精度が低いになっています。。パラメーター調整がまだ必だと思います。