
目次
1. Snake活性化関数の概要
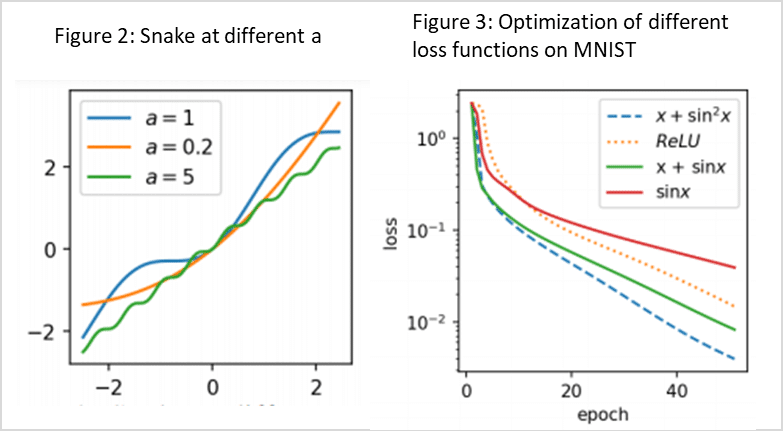
1.1 Snake活性化関数とは
1.2 Snake関数
2. 実験
2.1 ライブラリインポート
2.2 データ読み込み
2.3 データ加工
2.4 Snakeの活性化関数を作成
2.5 LSTMの活性化関数を作成
2.6 まとめ
関連記事:活性化関数のまとめ
1. Snake活性化関数の概要
1.1 Snake活性化関数とは
Snakeの活性化関数は、単純な周期関数の外挿を学習できないLSTMに用います。通常の活性化関数であるtanh、sigmoid、reluの弱点を改善するために使用します。LSTMベースのアクティベーションの優れた最適化特性を維持しながら、周期関数を学習するために必要な周期的誘導バイアスを実現する新しいアクティベーション、つまりx + sin2(x)のような学習が難しいタイプで用いられます。
tfa.activations.snake(
x: tfa.types.TensorLike,
frequency: tfa.types.Number = 1
) -> tf.Tensor
論文:Neural Networks Fail to Learn Periodic Functions and How to Fix It
https://arxiv.org/abs/2006.08195
TensorFlow: https://www.tensorflow.org/addons/api_docs/python/tfa/activations/snake
Pytorch: https://pypi.org/project/torch-snake/
2. 実験
データセット:3,235日の日光のデータセット
モデル:Snakeの活性化関数のモデル vs LSTMの活性化関数のモデル
モデル評価:MAE
2.1 ライブラリインポート
ライブラリのインストール
| !pip install tensorflow-addons |
ライブラリインポート
| import os import sys import csv import tensorflow as tf import numpy as np import urllib import matplotlib.pyplot as plt keras = tf.keras
from datetime import datetime |
2.2 データ読み込み
データセットをロードして、正規化します。
| # Load data
url = ‘https://storage.googleapis.com/download.tensorflow.org/data/Sunspots.csv’ urllib.request.urlretrieve(url, ‘sunspots.csv’)
time_step = [] sunspots = []
with open(‘sunspots.csv’) as csvfile: reader = csv.reader(csvfile, delimiter=’,’) next(reader) for row in reader: sunspots.append(float(row[2])) time_step.append(int(row[0]))
# normalization function
series = np.array(sunspots) min = np.min(series) max = np.max(series) series -= min series /= max time = np.array(time_step) |
学習データとテストデーとを作成します。
| # train test split split_time = 3000
time_train = time[:split_time] x_train = series[:split_time] time_valid = time[split_time:] x_valid = series[split_time:] |
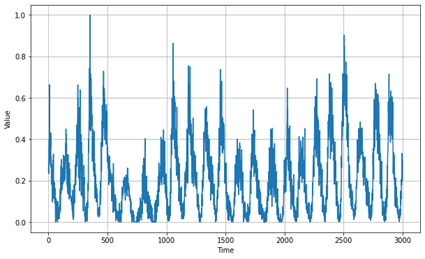
学習データを確認します。
| def plot_series(time, series, format=”-“, start=0, end=None, label=None): plt.plot(time[start:end], series[start:end], format, label=label) plt.xlabel(“Time”) plt.ylabel(“Value”) if label: plt.legend(fontsize=14) plt.grid(True)
plt.figure(figsize=(10, 6)) plot_series(time_train, x_train) plt.show() |
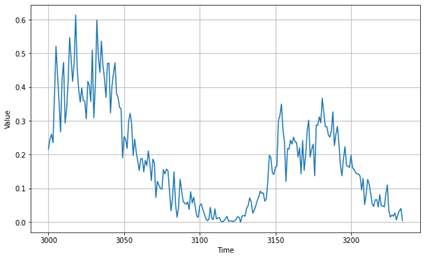
テストデータを確認します。
| plt.figure(figsize=(10, 6)) plot_series(time_valid, x_valid) plt.show() |
2.4 Snakeの活性化関数のネットワークを作成
| # DENSE import tensorflow_addons as tfa
# Parameter window_size = 30 batch_size = 256 shuffle_buffer_size = 1000 epochs = 150
keras.backend.clear_session() tf.random.set_seed(42) np.random.seed(42)
dense_model = keras.models.Sequential([ keras.layers.Dense(100, batch_input_shape=[1, None, 1]), keras.layers.Dense(100, activation=tfa.activations.snake,), keras.layers.Dense(100, activation=tfa.activations.snake,), keras.layers.Dense(100, activation=tfa.activations.snake,), keras.layers.Dense(1), keras.layers.Lambda(lambda x: x * 200.0) ])
optimizer = keras.optimizers.SGD(learning_rate=5e-7, momentum=0.9) dense_model.compile(loss=keras.losses.Huber(), optimizer=optimizer, metrics=[“mae”])
reset_states = ResetStatesCallback() checkpoint = “output/dense/my_checkpoint.h5” dense_checkpoint = keras.callbacks.ModelCheckpoint(checkpoint, save_best_only=True) early_stopping = keras.callbacks.EarlyStopping(patience=5)
dense_history = dense_model.fit(train_set, epochs=epochs, validation_data=valid_set, callbacks=[early_stopping, model_checkpoint, reset_states]) |
Epoch 1/150
99/99 [==============================] – 2s 9ms/step – loss: 0.1945 – mae: 0.4653 – val_loss: 0.0918 – val_mae: 0.3777
…
Epoch 150/150
99/99 [==============================] – 1s 7ms/step – loss: 0.0025 – mae: 0.0523 – val_loss: 0.0019 – val_mae: 0.0465
MAEのモデル評価
モデルは徐々に学ぶことができます。
| # Plot loss plt.xlabel(‘Epoch’) plt.ylabel(‘mae’) plt.plot(dense_history.history[‘val_loss’]) |
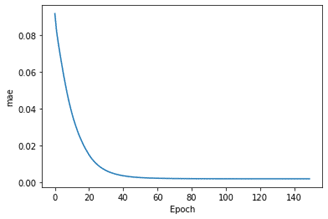
モデル評価
| dense_forecast = dense_model.predict(series[np.newaxis, :, np.newaxis]) dense_forecast = dense_forecast[0, split_time – 1:-1, 0]
print(‘MAE: ‘ + str(keras.metrics.mean_absolute_error(x_valid, dense_forecast).numpy())) |
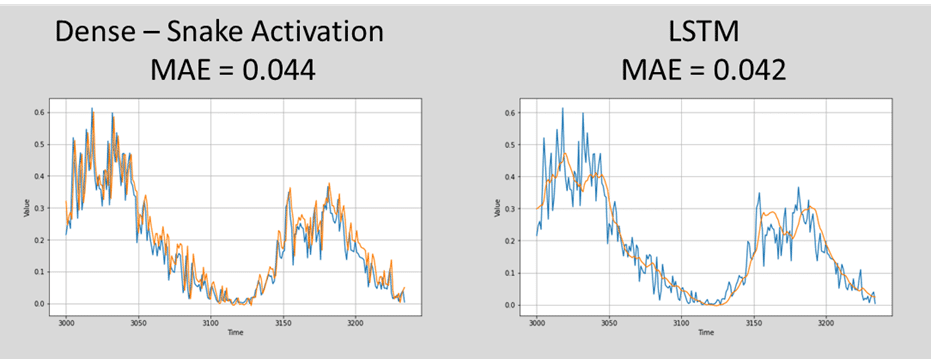
MAE: 0.044753935
モデルを推論します。
過学習になる傾向が知られています。
| def plot_series(time, series, format=”-“, start=0, end=None, label=None): plt.plot(time[start:end], series[start:end], format, label=label) plt.xlabel(“Time”) plt.ylabel(“Value”) if label: plt.legend(fontsize=14) plt.grid(True)
plt.figure(figsize=(10, 6)) plot_series(time_valid, x_valid) plot_series(time_valid, dense_forecast) # plt.savefig(‘output/rnn/predict_vs_valid.png’) plt.show() |
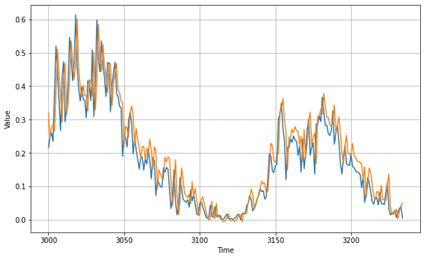
2.5 LSTMの活性化関数を作成
| # LSTM
# Parameter window_size = 30 batch_size = 256 shuffle_buffer_size = 1000 epochs = 100
def sequential_window_dataset(series, window_size): series = tf.expand_dims(series, axis=-1) ds = tf.data.Dataset.from_tensor_slices(series) ds = ds.window(window_size + 1, shift=window_size, drop_remainder=True) ds = ds.flat_map(lambda window: window.batch(window_size + 1)) ds = ds.map(lambda window: (window[:-1], window[1:])) return ds.batch(1).prefetch(1)
class ResetStatesCallback(keras.callbacks.Callback): def on_epoch_begin(self, epoch, logs): self.model.reset_states()
keras.backend.clear_session() tf.random.set_seed(42) np.random.seed(42)
window_size = 30 train_set = sequential_window_dataset(x_train, window_size) valid_set = sequential_window_dataset(x_valid, window_size)
lstm_model = keras.models.Sequential([ keras.layers.LSTM(100, return_sequences=True, stateful=True, batch_input_shape=[1, None, 1]), keras.layers.LSTM(100, return_sequences=True, stateful=True), keras.layers.Dense(1), keras.layers.Lambda(lambda x: x * 200.0) ])
optimizer = keras.optimizers.SGD(learning_rate=5e-7, momentum=0.9) lstm_model.compile(loss=keras.losses.Huber(), optimizer=optimizer, metrics=[“mae”])
reset_states = ResetStatesCallback() checkpoint = “output/lstm/my_checkpoint.h5” model_checkpoint = keras.callbacks.ModelCheckpoint(checkpoint, save_best_only=True) early_stopping = keras.callbacks.EarlyStopping(patience=3)
lstm_history = lstm_model.fit(train_set, epochs=epochs, validation_data=valid_set, callbacks=[early_stopping, model_checkpoint, reset_states]) |
Epoch 1/100
99/99 [==============================] – 6s 23ms/step – loss: 1.5726 – mae: 2.0261 – val_loss: 1.0051 – val_mae: 1.4602
…
Epoch 100/100
99/99 [==============================] – 1s 14ms/step – loss: 0.0026 – mae: 0.0540 – val_loss: 0.0025 – val_mae: 0.0495
MAEのモデル評価
| # Plot loss plt.xlabel(‘Epoch’) plt.ylabel(‘mae’) plt.plot(lstm_history.history[‘loss’]) plt.savefig(‘output/lstm/loss.png’) |
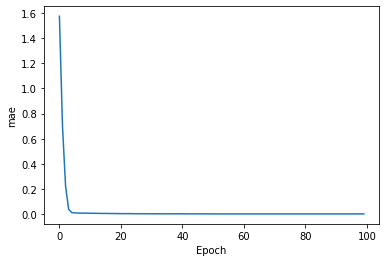
| # Forecast
lstm_forecast = lstm_model.predict(series[np.newaxis, :, np.newaxis]) lstm_forecast = lstm_forecast[0, split_time – 1:-1, 0]
print(‘MAE: ‘ + str(keras.metrics.mean_absolute_error(x_valid, lstm_forecast).numpy())) |
MAE: 0.042137478
モデルを推論します。
| def plot_series(time, series, format=”-“, start=0, end=None, label=None): plt.plot(time[start:end], series[start:end], format, label=label) plt.xlabel(“Time”) plt.ylabel(“Value”) if label: plt.legend(fontsize=14) plt.grid(True)
plt.figure(figsize=(10, 6)) plot_series(time_valid, x_valid) plot_series(time_valid, lstm_forecast) # plt.savefig(‘output/lstm/predict_vs_valid.png’) plt.show() |
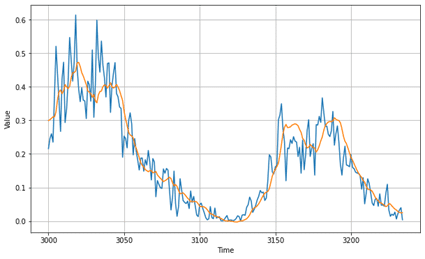
2.6 まとめ
日光のデータセットで、Snakeの活性化関数のモデル と LSTMのモデルを作成しました。モデルの精度は同じくらいですが、上手く周期部分をSnakeが捉えられていることがわかります。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属