
目次
1. SAMの概要
1.1 SAMとは
2. 実験
2.1 環境構築
2.2 データセットの準備
2.3 SAM関数
2.4 ResNet20 モデル
2.5 まとめ
1. SAMの概要
1.1 SAMとは
SAMはSHARPNESS-AWARE MINIMIZATIONの略称で、Google Researchで深層学習ネットワークの損失を減らす新しい効果的な方法です。損失ランドスケープのジオメトリと一般化を接続する以前の作業によって作成されました。
資料:https://github.com/google-research/sam
SAMは、多くの画像データセットベンチマークの最新モデルと比較して損失を改善できます。
左はSGDでトレーニングされたResNetが収束する鋭い最小値です。
右はSAMでトレーニングされたResNetが収束する広い最小値です。SAMは、広く研究されているさまざまなコンピュータービジョンタスク全体でモデルの一般化能力を向上させます。

単にトレーニング損失値LS(w)が低いパラメーター値wを探すのではなく、近隣全体のトレーニング損失値が均一に低いパラメーター値を探します。

論文:SHARPNESS-AWARE MINIMIZATION FOR EFFICIENTLY IMPROVING GENERALIZATION
https://openreview.net/pdf?id=6Tm1mposlrM
2. 実験
環境:Google Colab(TPU)
データセット:CIFAR-10 は6万枚の10種類の「物体カラー写真」(乗り物や動物など)の画像データセット
モデル:SAM、ResNet20
2.1 環境構築
Githubのプロジェクトをダウンロードします。
| !git clone https://github.com/sayakpaul/Sharpness-Aware-Minimization-TensorFlow |
ライブラリのインポート
| import matplotlib.pyplot as plt import resnet_cifar10 import utils import time |
2.2 データセットの準備
データセットをダウンロードします。
| (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() print(f”Training samples: {len(x_train)}“) print(f”Testing samples: {len(x_test)}“)
|
170500096/170498071 [==============================] – 2s 0us/step
Training samples: 50000
Testing samples: 10000
データ加工
| BATCH_SIZE = 128 * strategy.num_replicas_in_sync print(f”Batch size: {BATCH_SIZE}“) AUTO = tf.data.AUTOTUNE
def scale(image, label): image = tf.image.convert_image_dtype(image, tf.float32) label = tf.cast(label, tf.int32) return image, label
def augment(image,label): image = tf.image.resize_with_crop_or_pad(image, 40, 40) # Add 8 pixels of padding image = tf.image.random_crop(image, size=[32, 32, 3]) # Random crop back to 32×32 image = tf.image.random_brightness(image, max_delta=0.5) # Random brightness image = tf.clip_by_value(image, 0., 1.)
return image, label
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) train_ds = ( train_ds .shuffle(1024) .map(scale, num_parallel_calls=AUTO) .map(augment, num_parallel_calls=AUTO) .batch(BATCH_SIZE) .prefetch(AUTO) )
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)) test_ds = ( test_ds .map(scale, num_parallel_calls=AUTO) .batch(BATCH_SIZE) .prefetch(AUTO) )
|
Batch size: 1024
2.3 SAM関数
| class SAMModel(tf.keras.Model): def __init__(self, resnet_model, rho=0.05): “”” p, q = 2 for optimal results as suggested in the paper (Section 2) “”” super(SAMModel, self).__init__() self.resnet_model = resnet_model self.rho = rho
def train_step(self, data): (images, labels) = data e_ws = [] with tf.GradientTape() as tape: predictions = self.resnet_model(images) loss = self.compiled_loss(labels, predictions) trainable_params = self.resnet_model.trainable_variables gradients = tape.gradient(loss, trainable_params) grad_norm = self._grad_norm(gradients) scale = self.rho / (grad_norm + 1e-12)
with tf.GradientTape() as tape: predictions = self.resnet_model(images) loss = self.compiled_loss(labels, predictions) for (grad, param) in zip(gradients, trainable_params): e_w = grad * scale param.assign_add(e_w) e_ws.append(e_w) sam_gradients = tape.gradient(loss, trainable_params) for (param, e_w) in zip(trainable_params, e_ws): param.assign_sub(e_w)
self.optimizer.apply_gradients( zip(sam_gradients, trainable_params))
self.compiled_metrics.update_state(labels, predictions) return {m.name: m.result() for m in self.metrics}
def test_step(self, data): (images, labels) = data predictions = self.resnet_model(images, training=False) loss = self.compiled_loss(labels, predictions) self.compiled_metrics.update_state(labels, predictions) return {m.name: m.result() for m in self.metrics}
def _grad_norm(self, gradients): norm = tf.norm( tf.stack([ tf.norm(grad) for grad in gradients if grad is not None ]) ) return norm |
Callbacks設定します。
| train_callbacks = [ tf.keras.callbacks.EarlyStopping( monitor=”val_loss”, patience=10, restore_best_weights=True ), tf.keras.callbacks.ReduceLROnPlateau( monitor=”val_loss”, factor=0.5, patience=3, verbose=1 ) ] |
モデルコンパイルします。
| with strategy.scope(): model = SAMModel(utils.get_training_model()) model.compile( optimizer=”adam”, loss=”sparse_categorical_crossentropy”, metrics=[“accuracy”] ) print(f”Total learnable parameters: {model.resnet_model.count_params()/1e6} M”)
|
Total learnable parameters: 0.575114 M
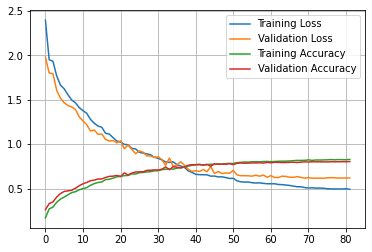
モデル学習
| start = time.time() history = model.fit(train_ds, validation_data=test_ds, callbacks=train_callbacks, epochs=100) print(f”Total training time: {(time.time() – start)/60.} minutes”)
|
Epoch 1/100 49/49 [==============================] – 29s 245ms/step – loss: 3.0029 – accuracy: 0.1295 – val_loss: 1.9802 – val_accuracy: 0.2626
…
Epoch 82/100
49/49 [==============================] – 3s 55ms/step – loss: 0.4900 – accuracy: 0.8307 – val_loss: 0.6204 – val_accuracy: 0.8050
Total training time: 5.425088755289713 minutes
モデル評価
| utils.plot_history(history) |
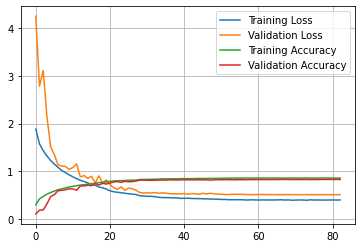
2.4 ResNet20 モデル
| with strategy.scope(): model = utils.get_training_model()
model.compile( optimizer=”adam”, loss=”sparse_categorical_crossentropy”, metrics=[“accuracy”] )
start = time.time() history = model.fit(train_ds, validation_data=test_ds, callbacks=train_callbacks, epochs=200) # 200 eppochs since SAM takes two backprop steps for an update print(f”Total training time: {(time.time() – start)/60.} minutes”) |
Epoch 1/200
49/49 [==============================] – 28s 241ms/step – loss: 2.0576 – accuracy: 0.2403 – val_loss: 4.2448 – val_accuracy: 0.1111
…
Epoch 83/200
49/49 [==============================] – 3s 59ms/step – loss: 0.4022 – accuracy: 0.8613 – val_loss: 0.5136 – val_accuracy: 0.8310
Total training time: 5.581731029351553 minutes
モデル評価
| utils.plot_history(history) |
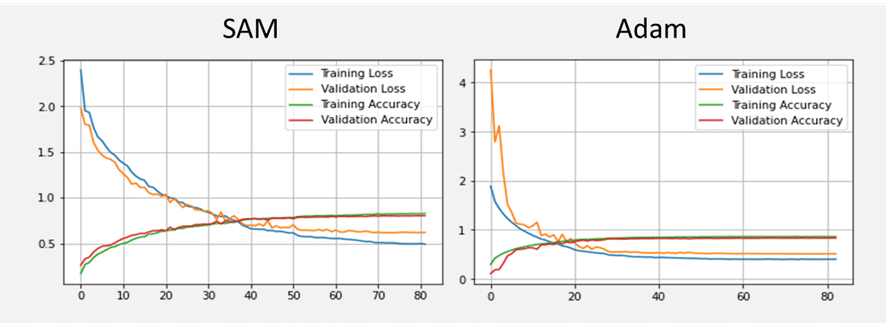
2.5 まとめ
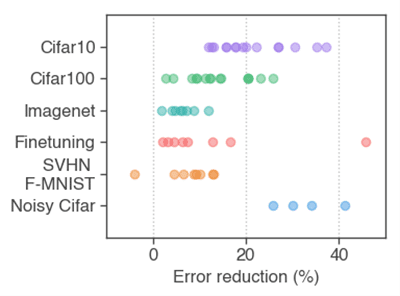
CIFAR-10のデータセットでSAMとResNet20のモデルを作成しました。SAMは安定学習して、よりエラーが減少しました。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属