
目次
1 PROXIMALADAGRAD最適化アルゴリズムの概要
1.1 PROXIMALADAGRAD最適化アルゴリズムとは
1.2 PROXIMALADAGRAD定義
2. 実験
2.1 データロード
2.2 データ前処理
2.3 PROXIMALADAGRAD最適化アルゴリズムのモデル作成
2.4 Adam最適化アルゴリズムのモデル作成
2.5 まとめ
1 PROXIMALADAGRAD最適化アルゴリズムの概要
1.1 PROXIMALADAGRAD最適化アルゴリズムとは
ProximalAdagradは、正則化項の最小化と引き換えに、最初のフェーズの結果に近接した状態を維持しつつ最適化問題を解決しようとするアルゴリズムです。
アルゴリズムのフレームワークは、2つのフェーズを交互に繰り返します。 各反復で、最初に制約のない勾配降下ステップを実行します。2フェーズのアプローチでは、L1などのスパース性を促進する正則化関数と組み合わせて使用すると、スパースソリューションが可能になります。
1.2 PROXIMALADAGRAD定義
アルゴリズムForward-Looking Subgradients and Forward-Backward Splitting (FOBO)
では、次の2つの手順を繰り返します。
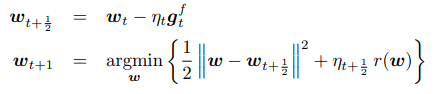
したがって、最初のステップは、関数fに関して制約のない劣勾配ステップになります。 2番目のステップでは、2つの目標の間を補間する新しいベクトルを見つけます。
(i)暫定ベクトルwt + 1/2の近くにとどまり
(ii)rの関数での最小値を求めようとする

左:ℓ1-正則化を使用したLandSatデータセットのFOBOSスパース性とテストエラー。
右:MNISTデータセットのFOBOSスパース性とテストエラー ℓ1/ℓ2-正則化
論文:
https://proceedings.neurips.cc/paper/2009/file/621bf66ddb7c962aa0d22ac97d69b793-Paper.pdf
Tensorflow:
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/ProximalAdagrad?hl=ja
2. 実験
データセット:cifar10: 60000枚の32ピクセルx32ピクセルの画像。10クラス([0] airplane (飛行機)、[1] automobile (自動車)、[2] bird (鳥)、[3] cat (猫)、[4] deer (鹿)、[5] dog (犬)、[6] frog (カエル)、[7] horse (馬)、[8] ship (船)、[9] truck (トラック))
モデル:CNN Ranger最適化アルゴリズム(TensorFlowアドオン)vs CNN Adam最適化アルゴリズム
| !pip install tensorflow-addons |
ライブラリのインポート
| import tensorflow as tf import tensorflow_addons as tfa from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.1 データロード
keras.datasetsからcifar10のデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
サンプル画像データを表示します。
| # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |

2.2 データ前処理
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.3 PROXIMALADAGRAD最適化アルゴリズムの
| PROXIMALADAGRAD = tfa.optimizers.ProximalAdagrad( learning_rate = 0.001, initial_accumulator_value = 0.1, l1_regularization_strength = 0.0, l2_regularization_strength = 0.0, name = ‘ProximalAdagrad’, ) |
PROXIMALADAGRAD最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’))
model.compile(optimizer=PROXIMALADAGRAD, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
flatten (Flatten) (None, 2304) 0
dense (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
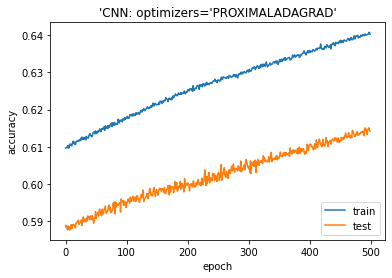
モデルを学習します。500 epochに設定しました。
| history = model.fit(X_train, y_train, batch_size=100, epochs=500, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/500
500/500 [==============================] – 2s 5ms/step – loss: 1.1379 – accuracy: 0.6097 – val_loss: 1.1801 – val_accuracy: 0.5889
…
Epoch 500/500
500/500 [==============================] – 3s 5ms/step – loss: 1.0560 – accuracy: 0.6402 – val_loss: 1.1138 – val_accuracy: 0.6142
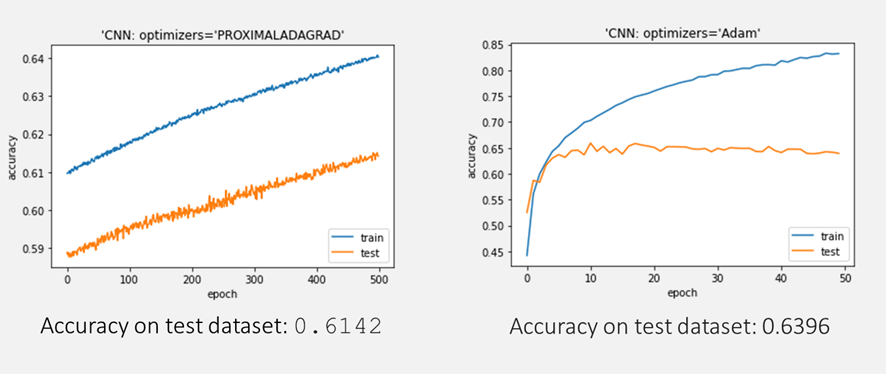
モデル評価
PROXIMALADAGRADの最適化アルゴリズムは良い結果になります。ゆっくりとしっかり学習しました。
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=’PROXIMALADAGRAD'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
| from sklearn.metrics import accuracy_score import numpy as np
y_pred_p = model.predict(X_test) y_pred = np.argmax(y_pred_p,axis=1) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6142
2.4 Adam最適化アルゴリズムのモデル作成
Adam最適化アルゴリズムのCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’selu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’selu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_2”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test))
|
Epoch 1/50
500/500 [==============================] – 3s 5ms/step – loss: 1.7548 – accuracy: 0.3765 – val_loss: 1.3548 – val_accuracy: 0.5202
…
Epoch 50/50
500/500 [==============================] – 2s 5ms/step – loss: 0.4620 – accuracy: 0.8419 – val_loss: 1.3445 – val_accuracy: 0.6396
モデル評価
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: optimizers=Adam'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show()
y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score)
|
| y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score)
|
Accuracy on test dataset: 0.6396
2.5 まとめ
cifar10データセットでPROXIMALADAGRAD最適化アルゴリズムのCNNモデルとAdam最適化アルゴリズムのCNNモデルを作成しました。Adamに比べて、PROXIMALADAGRADはゆっくりとしっかり学習していることがわかります。ただし精度的には劣っています。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属