
目次
1. RolexBoostの概要
_1.1 RolexBoostとは
_1.2 RolexBoostのアルゴリズム
_1.3 RolexBoostのモデル評価
2. 実験
_2.1 環境準備
_2.2 データロード
_2.3 RolexBoostモデル作成
_2.4 decision treeモデル作成
_2.5 モデル評価
1. RolexBoostの概要
1.1 RolexBoostとは
モデルRolexBoostは Rotation-Flexible AdaBoostの略称で、新しい高い精度のアンサンブルのモデルです(RandomForestの亜種です)。RolexBoostはAdaBoostの拡張であり、違いは、適応損失関数を採用することでAdaBoostのパフォーマンスを向上させます。
ハイパーパラメーターは、指数損失の感度を制御します。これにより、各反復で最適な損失関数を特定できます。 RolexBoostは、柔軟な重み更新システムを使用して、範囲外のデータポイントに対してより堅牢な強力な分類器を構築します。
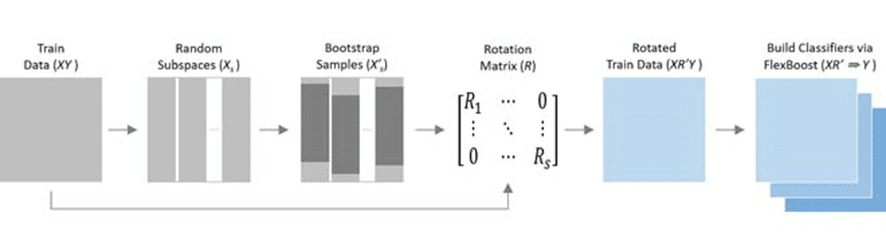
1.2 RolexBoostのアルゴリズム
- トレーニングデータDtr = {(x1、y1、…)、(xm、ym)}ここで、X = {x1、…、xm}およびY = {y1、…、ym}はそれぞれ説明変数、被説明変数に対応しています。
- L:ブートストラップサブサンプルの数
- S:部分空間の数
- T:反復回数(基本分類子)
- K:指数損失関数の感度を制御するハイパーパラメーター
トレーニングプロセス
l = 1からLまで
XをS個の部分空間にランダムに分割します:Xl、s
s = 1からSの場合
ブートストラップXl、s:X’l、s
PCAをX’l、sに適用し、主成分係数を抽出します:Rl、s
1.3 RolexBoostのモデル評価
30の二項分類問題に関する実験結果は、RolexBoostが競合するアンサンブル手法(AdaBoost、GentleBoost、Rotation Forest、Random Forest、Rotation Boost、FlexBoost)の中で最高の精度を確認しまた。
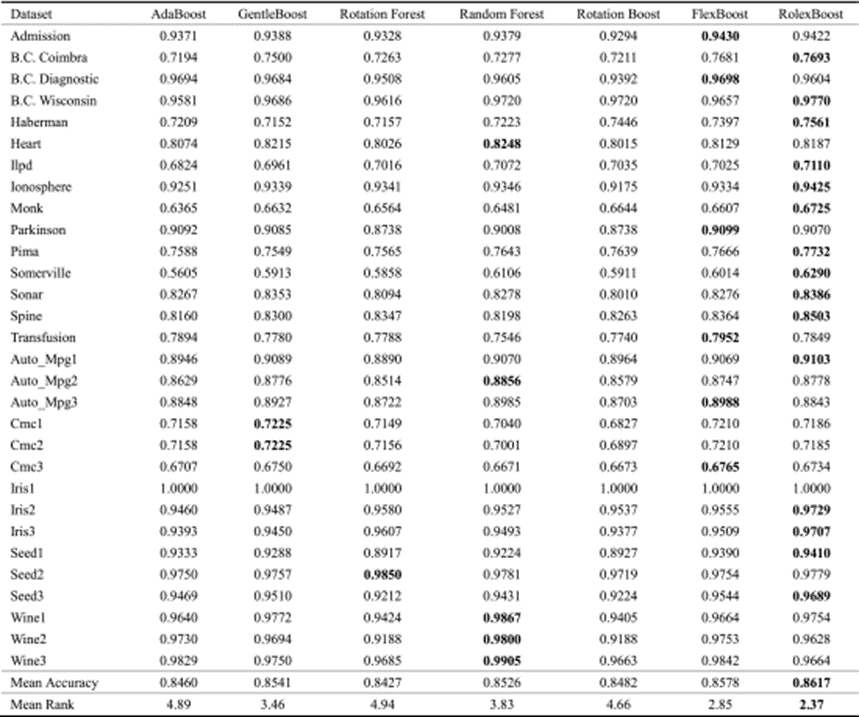
次に、post-hocを実行して、アンサンブルモデルの分類精度間のランキングに統計的に有意な差が存在するかどうかを検証しました。
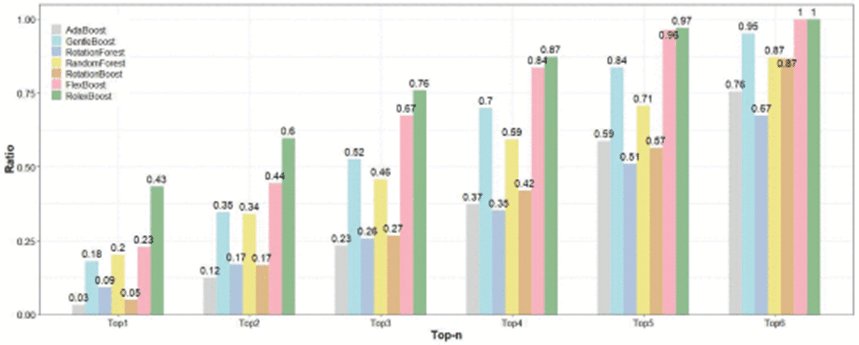
参照:
rolexboostのライブラリ https://pypi.org/project/rolexboost/
rolexboostの論文 https://ieeexplore.ieee.org/document/9016246
2. 実験
環境:Google Colab
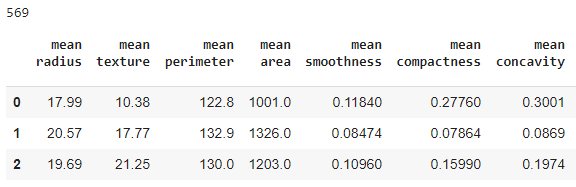
データセット:load_breast_cancer:scikit-learnで提供されている癌の判定を行うデータです。このデータは569人分のデータが存在し、凹み,凹点,対称性等の30個の説明変数があります。
モデル:rolexboostとdecision tree
モデル評価:AUC
2.1 環境準備
ライブラリをインストールします。
| !pip install rolexboost
|
ライブラリをインポートします。
| import numpy as np import pandas as pd
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score from sklearn.metrics import plot_roc_curve
from sklearn.tree import DecisionTreeClassifier from rolexboost import RolexBoostClassifier
import matplotlib.pyplot as plt
SEED = 11 |
2.2 データロード
Scikit learnからデータロードします。
| # Load data cancer = load_breast_cancer() data = pd.DataFrame(np.c_[cancer[‘data’], cancer[‘target’]], columns= np.append(cancer[‘feature_names’], [‘target’]))
X = data.drop([‘target’], axis=1) y = data[‘target’]
print(len(data)) data.head(3)
|
学習データとテストデータを分けます。
訓練用:8割、評価用:2割に分割にします。
| X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=SEED) print(‘X_train’, X_train.shape) print(‘X_test’, X_test.shape) |
X_train (455, 30)
X_test (114, 30)
2.3 rolexboostモデル作成
デフォルトの設定でRolexboostを作成します。
| rlx_clf = RolexBoostClassifier() rlx_clf.fit(X_train, y_train)
|
RolexBoostClassifier(K=0.5, bootstrap_rate=0.75, ccp_alpha=0.0,
class_weight=None, criterion=’gini’, max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_features_per_subset=3, presort=’deprecated’,
random_state=None, splitter=’best’)
2.4 decision treeモデル作成
デフォルトの設定でdecision treeを作成します。
| dt_clf = DecisionTreeClassifier() dt_clf.fit(X_train, y_train)
|
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion=’gini’,
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=’deprecated’,
random_state=None, splitter=’best’)
2.5 モデル評価
モデルの推論を行います。
| y_pred_rlx = rlx_clf.predict(X_test) y_pred_dt = dt_clf.predict(X_test)
|
Aucを計算し、比較します。
| auc_rlx = roc_auc_score(y_pred_rlx, y_pred) auc_dt = roc_auc_score(y_pred_dt, y_pred) print(auc_rlx) print(auc_dt)
|
0.954871794871795
0.9473684210526316

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト