
目次
1. KTBoostの概要
1.1 KTBoostのクラスター分析とは
1.2 KTBoostのライブラリ
2. 実験
2.1 環境設定
2.2 データロード
2.3 モデル作成
2.4モデル評価
2.5 # 特徴量の重要性
1. KTBoostの概要
1.1 KTBoostとは
KTBoostとは、カーネルブースティングとツリーブースティングを組み合わせた新たなブースティングアルゴリズムです。カーネルとツリーブーストを組み合わせたアイデアは、ツリーは関数の粗い部分を学習するのに適し、RKHS回帰関数は関数の滑らかな部分をよりよく学習できるため、不連続ツリーと連続RKHS関数は互いに補完し合うと考えられています。
論文の結果ですが、RKHSとTreeに比べて良い予測結果がでています。
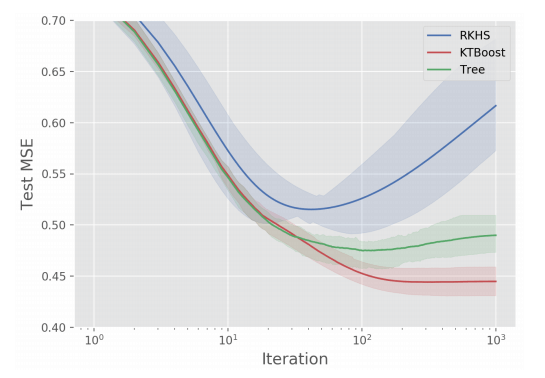
カーネルとツリーのブースティングの組み合わせの関数:

論文:KTBoost: Combined Kernel and Tree Boosting
https://arxiv.org/abs/1902.03999
1.2 KTBoostのライブラリ
2つの主要なクラスは、KTBoost.BoostingClassifierとKTBoost.BoostingRegressorです。
BoostingClassifierは分類分析のクラス、BoostingRegressorは回帰分析のクラスです。
パラメター
loss :損失:最適化される損失関数。
KTBoost.BoostingClassifier {‘deviance’, ‘exponential’}, optional (default=’deviance’)
KTBoost.BoostingRegressor {‘ls’, ‘lad’, ‘huber’, ‘quantile’, ‘poisson’, ‘tweedie’, ‘gamma’, ‘tobit’, ‘msr’}, optional (default=’ls’)
update_step : string, default=”hybrid”
ブースティング更新の計算方法を定義します。
learning_rate : float, optional (default=0.1)
“tree” “kernel” “combined”の基本学習者を選べます。
learning_rate : float, optional (default=0.1)
学習率を定義します。Learning_rateとn_estimatorsの間にはトレードオフがあります。
n_estimators : int (default=100)
ブーストのイテレーション
max_depth : integer, optional (default=5)
リーフノード数の最大値
min_weight_leaf : float, optional (default=1.)
リーフノードに必要がある重み付けされたサンプルの最小数
criterion : string, optional (default=”mse”)
分割の品質を測定する関数
random_state : int, RandomState instance or None, optional (default=None)
乱数を制御するパラメータ
kernel : string, default=”rbf”
“laplace”, “rbf”, and “GW” のカーネル関数
theta : float, default: 1.
カーネル関数が距離とともに減衰する速度を決定するカーネル関数
n_neighbors : int, default: None
範囲パラメータのパラメータ
alphaReg : float, default: 1.
カーネルリッジ回帰ブースティング更新の正則化パラメーター
nystroem : boolean, default=None
Nystroem samplingを利用するかどうか
n_components : int, detault = 100
カーネルブーストのためのNystroemサンプリングで使用されるデータポイントの数。
詳細:https://pypi.org/project/KTBoost/
2. 実験
環境:Colab
データセット:scikit-learnの乳がんデータセットは、30つの特徴量と乳がんあるかどうかラベルのデータです。
モデル:ベースモデル(決定木、ランダムフォレスト)、KTBoost
モデル評価:Accuracy
2.1 環境設定
KTBoostのライブラリをインストールします。
| !pip install -U KTBoost |
ライブラリのインポート
| # ライブラリのインポート import pandas as pd import numpy as np from datetime import datetime from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn import model_selection from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier
import KTBoost.KTBoost as KTBoost
seed = 0 |
2.2 データロード
データを読み込んで、確認します。
| # サンプルデータロード loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
print(‘X_train shape’, X_train.shape) print(‘y_train shape’, y_train.shape) loaded_data.feature_names |
2.3 モデル作成
モデルを作成します。
| kfold = model_selection.KFold(n_splits = 5) scores = {}
# 決定木 start_time = datetime.now() dtc_clf = DecisionTreeClassifier(random_state=seed) dtc_clf.fit(X_train, y_train) results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold) end_time = datetime.now() scores[(‘1.decision_tree’, ‘duration’)] = end_time – start_time scores[(‘1.decision_tree’, ‘train_score’)] = results.mean() scores[(‘1.decision_tree’, ‘test_score’)] = dtc_clf.score(X_test, y_test)
# ランダムフォレスト start_time = datetime.now() rfc_clf = RandomForestClassifier(random_state=seed) rfc_clf.fit(X_train, y_train) results = model_selection.cross_val_score(rfc_clf, X_test, y_test, cv = kfold) end_time = datetime.now() scores[(‘2.Random Forest’, ‘duration’)] = end_time – start_time scores[(‘2.Random Forest’, ‘train_score’)] = results.mean() scores[(‘2.Random Forest’, ‘test_score’)] = rfc_clf.score(X_test, y_test)
# KTBoost start_time = datetime.now() ktb_clf = KTBoost.BoostingClassifier(random_state=seed) ktb_clf.fit(X_train, y_train) results = model_selection.cross_val_score(ktb_clf, X_test, y_test, cv = kfold) end_time = datetime.now() scores[(‘3.KTBoost’, ‘duration’)] = end_time – start_time scores[(‘3.KTBoost’, ‘train_score’)] = results.mean() scores[(‘3.KTBoost’, ‘test_score’)] = ktb_clf.score(X_test, y_test) |
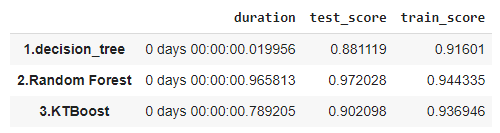
2.4 モデル評価
乳がんデータセットで決定木、ランダムフォレスト、KTBoostのモデル作成しました。KTBoostは良い予測結果ですが、ランダムフォレストを超えませんでした。学習の時間はランダムフォレストより速いですが、決定木より遅いの結果になります。
| # モデル評価 pd.Series(scores).unstack() |
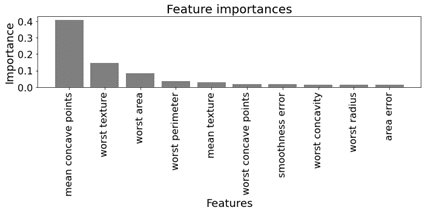
2.5 # 特徴量の重要性
特徴量の重要性も簡単に作成できます。
| # feature importances
KTBoost.plot_feature_importances(model=ktb_clf,feature_names=loaded_data.feature_names,maxFeat=10, figsize=(10,5)) |

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属