
目次
- KDDCUP 2020 Debiasingの概要
- スケジュール
- 評価方法
- 賞金
- データ
- ランキング
1. KDDCUP 2020 Debiasingの概要
KDD Cupはデータマイニングの国際学術会議であるKDDで開催されている、1997年からの歴史がある世界最高峰のデータ分析コンペです。
KDDカップ2020には、次の4つのトラックがあります。
4つの中でも今回は、1 Debiasing1:Eコマースのレコメンドシステムのコンペの位の解析手法について解説をしていきます。
2020年のランキング
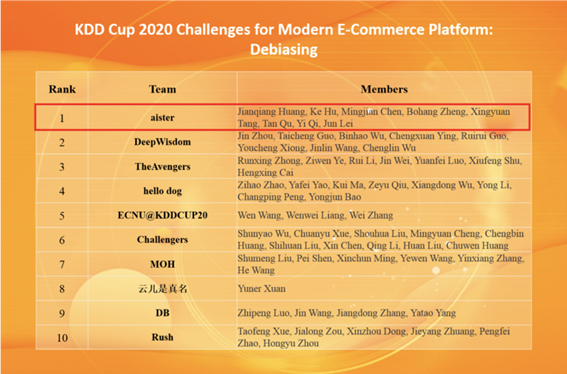
Aisterのチームが優勝しました。メンバーのほとんどは、美団Dianping広告プラットフォーム部門の検索広告アルゴリズムチームです。Debiasing(1/1895)で1位、AutoGraph(1/149)で1位、Multimodalities Recall(3/1433)で3位を獲得しました。
Github:https://github.com/aister2020/KDDCUP_2020_Debiasing_1st_Place
1位の解析手法
広告システムでは、データの偏りをなくす方法が最も難しい問題の1つであり、近年の研究においてもトレンドでもあります。 製品形態とアルゴリズム技術の継続的な進化により、システムは継続的にバイアス(データの偏差)を蓄積します。 検索連動型広告アルゴリズムチームは、データ偏差の問題に突破口を開き、ビジネス効果を大幅に向上させました。
レコメンデーションシステムにはさまざまな課題があります。
- レコメンデーションシステムの偏り。
- 機械学習システムに短期的な目標(短期的なクリックや取引など)が備わっている場合、短期的な目標の最適化は 深刻な「マシュー効果」に繋がると言われています。人気のある商品がより注目され、人気のない商品がますます忘れられ、システムの人気が逸脱します。
- ほとんどのモデルとシステムの反復はページの閲覧に依存します。 一方、曝露データはモデル選択後です。
選択的バイアス分析:
共起とベクトルの類似性をクリックして、選択性の偏りを軽減するためのより大きなトレーニングセットを生成する必要があります。
評価セット全体の半分は人気の低い商品に基づいており、評価データの残りの半分は人気が高い商品に基づいています。 商品を直接クリックしてサンプルを作成すると、データで人気の高い通常の商品が増え、人気の偏差が形成されます。実際に偏差を確認するためのヒストグラムは以下です。
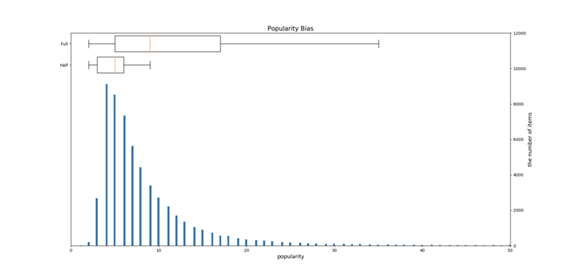
問題の課題
競争の主な課題は、レコメンデーションシステムのバイアスを排除することです。 上記のデータ分析から、選択バイアスと人気バイアスの2種類のバイアスがあることがわかります。
- 選択バイアス:暴露データはモデルとシステムによって選択されますが、これはシステム内のすべての候補セットと一致していません。
- 人気偏差:商品の履歴におけるヒット数はロングテール分布を示すため、人気偏差はヘッド商品とテール商品の間に存在します。 人気の偏差をどのように解決するかも、競争の中心的な課題の1つです。
上記の偏差に基づいて、ページビュー>クリックの従来のクリック予測モデリングのアイデアでは、ユーザーの本当の関心を合理的にモデル化することはできません。 また、従来のモデリングの効果は悪いことがわかりました。
フレームワークでは、製品の推奨プロセスは3つの段階に分かれています。
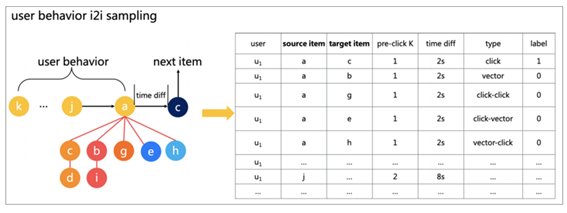
- 最初の段階は、ユーザーの行動データと製品のマルチモーダルデータに基づいてi2iグラフを作成し、i2iグラフに基づいてマルチホップウォークによってi2i候補サンプルを生成することです。
- 第2段階では、ユーザークリックシーケンスを分割し、i2i候補サンプルセットに従ってi2i関係サンプルセットを構築し、i2iサンプルセットに基づいて自動特徴エンジニアリングを実行します。第3段階では、i2iモデルによって生成されたi2iスコアが ユーザークリックシーケンス
- 人気の偏差を排除するための後処理は、商品リストをソートして推奨するために、段階的な商品リストで実行されます。
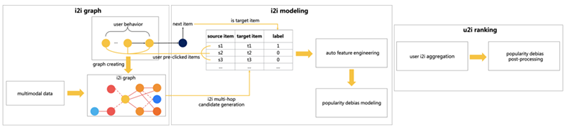
i2iグラフの作成とi2i候補サンプルの生成は、i2iグラフの作成、i2iマルチホップウォークの生成、およびi2i候補サンプルの生成の3つのステップに分けられます。
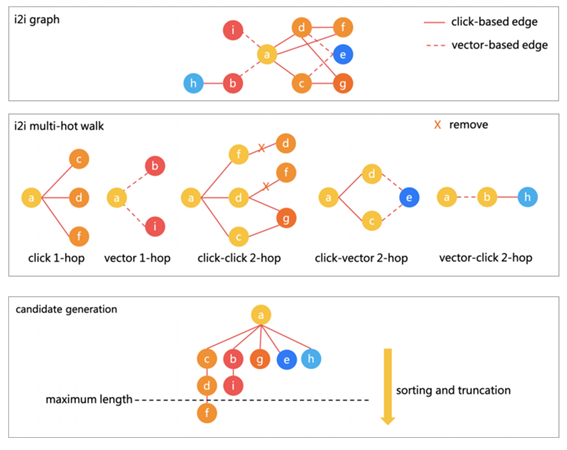
商品ベクトルの場合、k最近傍法を使用して最も近いK個の商品を検索します。 Kエッジは、商品とそれに最も近いK商品に対してそれぞれ構築されます。 次元間の類似性はエッジの重みです。 マルチモーダルVectorEdgeは人気とは何の関係もありません。これにより、人気の偏りを緩和できます。

i2iモデリング
選択的バイアスを排除するために、i2iの学習に重点を置いて、2つの商品クリックの時間差とクリック頻度間隔を通してユーザーのシーケンス情報を側面から紹介します。 エンドユーザーの推奨製品のランキングリストは、ユーザーのi2iスコアに基づいてターゲットアイテムごとに並べ替えることができます。
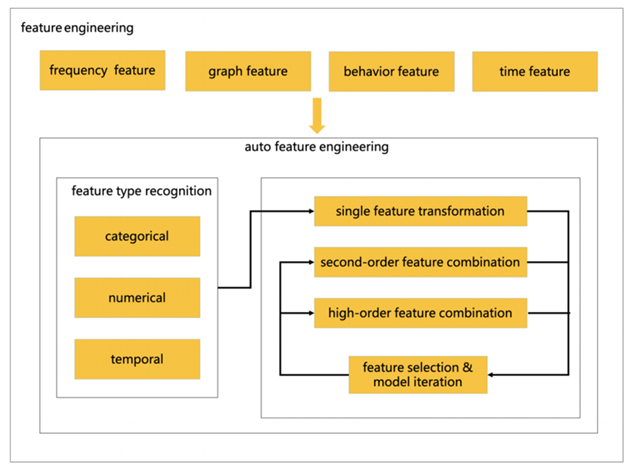
頻度特徴、グラフ特徴、行動特徴、時間依存特徴などの基本的な特徴を人為的に構築した後、これらの基本的な特徴タイプをカテゴリ特徴、数値特徴、時間特徴の3つのタイプに分類します。 これらの特徴に基づいて、高次の特徴を組み合わせ、各組み合わせによって形成された特徴を次の組み合わせの反復に追加して、高次の組み合わせを減らします。組み合わせの複雑さも、特徴とNDCGの重要性に基づいています。 @ 50_ Selfは特徴選択を高速化するため、より深いパターンをマイニングし、多くの人件費を節約できます。
モデルトレーニングでは、商品人気の加重損失を使用して、人気の偏差を排除します。 損失関数Lは次のとおりです。
![]()
![]()
ユーザー設定ランキング
最後に、ユーザーの商品の好みのランク付けは、ユーザーの商品の過去のクリックを通じてi2iを紹介することであり、その後、i2iによって導入されたすべての製品に対して最終的なランク付けの問題が形成されます。 最後に、ユーザーの複数の同一のターゲットアイテムに対して最大プーリング集計の方法を使用してから、ユーザーのすべてのターゲットアイテムを並べ替えます。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト