
目次
1. 自動のデータ拡張とは、
2. AutoAugment
3. Fast AutoAugment
4. RandAugment
5. TrivialAugment
関連記事:KerasでのData Augmentationの解説
1. 自動のデータ拡張とは、
データ拡張は、最新の画像分類器の精度を向上させるための効果的な手法です。 ただし、現在のデータ拡張の実装は手動で設計されています。 この論文では、改善されたデータ拡張ポリシーを自動的に検索するAutoAugmentと呼ばれるものを提案しています。この記事は自動のデータ拡張の進化についてまとめたいと思います。
2. AutoAugment
論文: https://arxiv.org/abs/1805.09501
AutoAugmentは、データセットから拡張ポリシーを自動的に検索するアルゴリズムとして提案されており、多くの画像認識タスクのパフォーマンスが大幅に向上しています。 ただし、その検索方法では、比較的小さなデータセットでも数千時間のGPUが必要です。
フレームワーク:
・より良いデータ拡張ポリシーを検索するために検索方法(強化学習など)を使用します。
・コントローラRNNは、検索空間から拡張ポリシーを予測します。
・固定アーキテクチャの子ネットワークは、精度Rを達成する収束にトレーニングされます。
・報酬Rは、ポリシー勾配法で使用され、時間の経過とともにより良いポリシーを生成できるようにコントローラーを更新します。
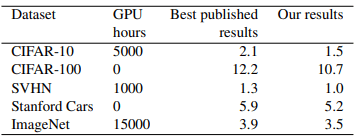
5つのデータセットに対して、以前のモデルより良い結果ができましたが、NVIDIA Tesla P100のGPUでも実行時間が長いです。
3. Fast AutoAugment
論文: https://arxiv.org/abs/1905.00397
Fast AutoAugmentは、密度マッチングに基づくより効率的な検索戦略を介して、効果的な拡張ポリシーを見つけます。 AutoAugmentと比較して、提案されたアルゴリズムは検索時間を桁違いに高速化し、CIFAR-10、CIFAR-100、SVHN、ImageNetなどのさまざまなモデルやデータセットを使用した画像認識タスクで同等のパフォーマンスを実現します。
AutoAugmentに比べて、Fast AutoAugmentの実行は相当に速くになりました。
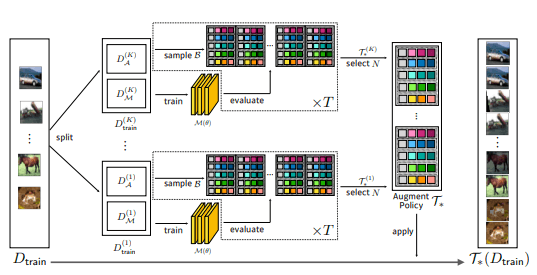
フレームワーク:
FastAutoAugmentアルゴリズムによる拡張検索の全体的な手順。 探索のために、提案された方法は、トレインデータセットDトレインをKフォールドに分割します。これは、2つのデータセットD(k)MとD(k)Aで構成されます。 次に、モデルパラメータθが各D(k)Mで並列にトレーニングされます。 θをトレーニングした後、アルゴリズムはθをトレーニングせずにDA上の拡張ポリシーのBバンドルを評価します。 各Kフォールドから取得された上位N個のポリシーは、拡張リストT ∗に追加されます。
4. RandAugment
論文: https://arxiv.org/abs/1909.13719
学習した増強の以前の方法は体系的な欠点に苦しんでいることを示しました。 つまり、歪みの数と歪みの大きさをデータセットサイズやモデルサイズに合わせて調整しないと、パフォーマンスが最適化されません。 この状況を改善するために、特定のモデルとデータセットのサイズに拡張をターゲティングするための単純なパラメーター化を提案します。 RandAugmentは、データ拡張ポリシーを個別に検索することなく、CIFAR-10 / 100、SVHN、ImageNet、およびCOCOでの以前のアプローチと競合するか、それよりも優れていることを示しています。

フレームワーク:
RandAugmentの主な目標は、プロキシタスクでの個別の検索フェーズの必要性を排除することです。 検索フェーズを削除したい理由は、別の検索フェーズではトレーニングが非常に複雑になり、計算コストが高くなるためです。
パラメータ空間を減らしながら画像の多様性を維持するために、各変換を適用するために学習したポリシーと確率を、常に均一な確率1/Kの変換を選択するパラメータのない手順に置き換えます。 したがって、トレーニング画像のN変換が与えられると、RandAugmentはKNの潜在的なポリシーを表すことができます。

5. TrivialAugment
論文: https://arxiv.org/abs/2103.10158
既存の自動拡張方法は、単純さ、コスト、およびパフォーマンスをトレードオフする必要があります。 最も単純なベースラインであるTrivialAugmentを紹介します。これは、以前の方法をほぼ無料で上回っています。 TrivialAugmentはパラメーターがなく、各画像に1つの拡張のみを適用します。 したがって、TrivialAugmentの有効性は私たちにとって非常に予想外であり、そのパフォーマンスを研究するために非常に徹底的な実験を行いました。
フレームワーク:
各画像に対して、TAは(均一に)増強強度と増強をサンプリングします。 次に、この増強は、サンプリングされた強度で画像に適用されます。
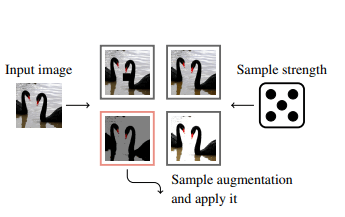
画像xと一連の拡張Aを入力として受け取ります。 次に、Aからの拡張をランダムに均一にサンプリングし、この拡張を強度mの指定された画像xに適用し、可能な強度のセット{0、…30}からランダムに均一にサンプリングして、拡張画像を返します。 この非常に単純でパラメータのない手順を、アルゴリズムの擬似コードとして概説します。

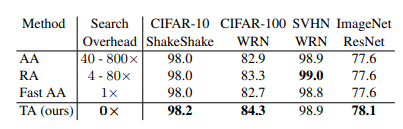
結果:
TrivialAugmentは、ほとんどのデータセットで最良の結果を示しています。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属