
目次
1. HDBSCANの概要
1.1 HDBSCANのクラスター分析とは
1.2 HDBSCANのライブラリ
2. 実験
2.1 環境設定
2.3 データ作成
2.4 HDBSCANのモデル
2.5可視化
1. HDBSCANの概要
1.1 HDBSCANのクラスター分析とは
HDBSCAN は、Campello、Moulavi、および Sander によって開発されたクラスタリング アルゴリズムです。DBSCANの拡張版で、階層的クラスタリング アルゴリズムに変換し、の安定性に基づいてフラットなクラスタリングをおこなう手法です。
HDBSCANの手順
- 密度/疎性に応じて空間を変形
- 距離加重グラフの最小全域木を構築
- 接続されたコンポーネントのクラスター階層を構築
- 最小クラスター サイズに基づいてクラスター階層を圧縮
- 凝縮木から安定したクラスターを抽出
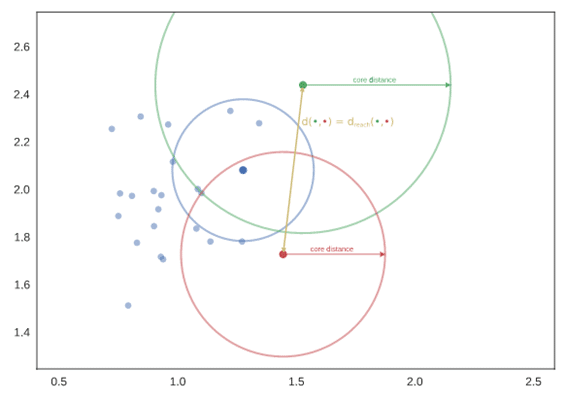
その他のクラスター分析のアルゴリズムに対して、HDBSCANは速いアルゴリズムであることが知られています。

論文:Density-Based Clustering Based on Hierarchical Density Estimates
https://link.springer.com/chapter/10.1007%2F978-3-642-37456-2_14
HDBSCANの資料
https://hdbscan.readthedocs.io/en/latest/basic_hdbscan.html
1.2 HDBSCANのライブラリ
| HDBSCAN(algorithm=’best’, allow_single_cluster=False, alpha=1.0, approx_min_span_tree=True, cluster_selection_epsilon=0.0, cluster_selection_method=’eom’, core_dist_n_jobs=4, gen_min_span_tree=False, leaf_size=40, match_reference_implementation=False, memory=Memory(location=None), metric=’euclidean’, min_cluster_size=5, min_samples=None, p=None, prediction_data=False) |
hdbscan.dist_metrics.METRIC_MAPPINGの関数で、全てのアルゴリズムを表示します。
{‘arccos’: hdbscan.dist_metrics.ArccosDistance,
‘braycurtis’: hdbscan.dist_metrics.BrayCurtisDistance,
‘canberra’: hdbscan.dist_metrics.CanberraDistance,
‘chebyshev’: hdbscan.dist_metrics.ChebyshevDistance,
‘cityblock’: hdbscan.dist_metrics.ManhattanDistance,
‘cosine’: hdbscan.dist_metrics.ArccosDistance,
‘dice’: hdbscan.dist_metrics.DiceDistance,
‘euclidean’: hdbscan.dist_metrics.EuclideanDistance,
‘hamming’: hdbscan.dist_metrics.HammingDistance,
‘haversine’: hdbscan.dist_metrics.HaversineDistance,
‘infinity’: hdbscan.dist_metrics.ChebyshevDistance,
‘jaccard’: hdbscan.dist_metrics.JaccardDistance,
‘kulsinski’: hdbscan.dist_metrics.KulsinskiDistance,
‘l1’: hdbscan.dist_metrics.ManhattanDistance,
‘l2’: hdbscan.dist_metrics.EuclideanDistance,
‘mahalanobis’: hdbscan.dist_metrics.MahalanobisDistance,
‘manhattan’: hdbscan.dist_metrics.ManhattanDistance,
‘matching’: hdbscan.dist_metrics.MatchingDistance,
‘minkowski’: hdbscan.dist_metrics.MinkowskiDistance,
‘p’: hdbscan.dist_metrics.MinkowskiDistance,
‘pyfunc’: hdbscan.dist_metrics.PyFuncDistance,
‘rogerstanimoto’: hdbscan.dist_metrics.RogersTanimotoDistance,
‘russellrao’: hdbscan.dist_metrics.RussellRaoDistance,
‘seuclidean’: hdbscan.dist_metrics.SEuclideanDistance,
‘sokalmichener’: hdbscan.dist_metrics.SokalMichenerDistance,
‘sokalsneath’: hdbscan.dist_metrics.SokalSneathDistance,
‘wminkowski’: hdbscan.dist_metrics.WMinkowskiDistance}
距離の解説は下記の記事を参考してください。
2. 実験
環境:Google Colab
データセット: Blobクラスタリング用のデータを作成します。
モデル:HDBSCAN
2.1 環境設定
Hdbscanをインストールします。
| !pip install hdbscan |
ライブラリのインポート
| import numpy as np import pandas as pd from sklearn.datasets import make_blobs import hdbscan from sklearn.metrics.pairwise import pairwise_distances import matplotlib.pyplot as plt |
2.3 データ作成
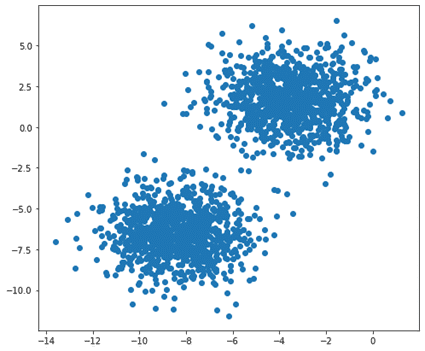
Blobクラスタリング用のデータを作成します。
件数(行)= 2,000、列 = 2、クラスター数 = 2, クラスタの標準偏差 = 1.5
| X, y = make_blobs(n_samples=2000, n_features=2, centers=2, cluster_std=1.5) |
データ確認
| X |
array([[ -8.52684553, -5.08681566],
[ 0.61934725, 0.57349716],
[ -3.47557218, 1.22412339],
…,
[ -4.70888019, 2.45015082],
[-11.60240089, -4.86990893],
[ -3.77015811, 1.78462797]])
| y |
array([1, 0, 0, …, 0, 1, 0])
| plt.figure(figsize=(8, 7)) plt.scatter(X[:, 0], X[:, 1]) plt.show() |
2.4 HDBSCANのモデル
HDBSCANのモデルを作成して、学習します。
| clusterer = hdbscan.HDBSCAN() clusterer.fit(X) |
結果を確認します。
3つのクラスターができました。
クラスター0は999件、クラスター1は1000件、ノイズ(クラスター-1)は1件です。
| cluster_label = clusterer.labels_ print(‘Cluster list’, np.unique(cluster_label)) print(‘Total :’, len(cluster_label)) print(‘Cluster 0:’, (cluster_label == 0).sum()) print(‘Cluster 1:’, (cluster_label == 1).sum()) print(‘Cluster -1:’, (cluster_label == -1).sum()) |
Cluster list [-1 0 1]
Total : 2000
Cluster 0: 999
Cluster 1: 1000
Cluster -1: 1
クラスターの信頼性
HDBSCANは、各データ ポイントに 0.0 ~ 1.0 の範囲のクラスター メンバーシップ スコアが割り当てられるソフト クラスタリングを実装します。 スコア 0.0 は、クラスターにまったくないサンプルを表し (すべてのノイズ ポイントがこのスコアを取得します)、スコア 1.0 はクラスターの中心にあるサンプルを表します (これは空間重心の概念ではないことに注意してください)。 コアの)。
| cluster_prob = clusterer.probabilities_ cluster_prob |
array([1. , 0.43942056, 1. , …, 1. , 1. ,
- ])
2.5 可視化
クラスターを可視化します。
| plt.figure(figsize=(8, 7)) plt.scatter(X[:, 0], X[:, 1], marker=’o’, c=cluster_label, s=25) plt.show() |


担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト