
目次
1. キャリブレーション(calibrated classifiers)の概要
1.1 キャリブレーションのクラスター分析とは
1.2 キャリブレーションのライブラリ
2. 実験
2.1 環境設定
2.2 データセット作成
2.3 SVC
2.4 SVC +キャリブレーションClassifierCV
2.5 まとめ
1. キャリブレーションの概要
1.1 キャリブレーションとは
キャリブレーション(calibrated classifiers)はモデルによって算出された予測確率を本来の確率に近づける手法です。普通の分類問題では、どのクラスに属するかを判別するモデルを作りますが、あるクラスに属する確率はどのくらいか、を予測したい場合を考えます。
モデルの出力値を各クラスに属する確率に近づけることを、キャリブレーションと言います。
キャリブレーションの方法を2つ記載します。
Sigmoid/Platt Scaling
説明変数をモデル出力値、目的変数を正解ラベルとしてSigmoid関数にフィットさせ、そのSigmoid関数に通した値をキャリブレーションした値とします。
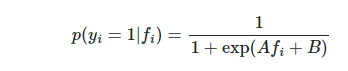
Isotonic Regression
与えられた順序制約を満たすようにパラメータを推定する問題は単調回帰 (isotonic regression) と呼ばれます。
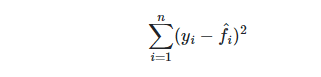
検量線(けんりょうせん:calibration curve)
下記ののプロットは、calibration_curveを使用して、さまざまな分類器の確率的予測がどの程度適切に較正されているかを比較しています。 x軸は、各ビンの平均予測確率を表します。 y軸は、陽性の割合、つまり、クラスが陽性クラスであるサンプルの割合です。

詳細:https://scikit-learn.org/stable/modules/calibration.html
SklearnのCalibratedClassifierCV
sklearn.calibration.CalibratedClassifierCV(base_estimator=None, *, method=’sigmoid’, cv=None, n_jobs=None, ensemble=True)
パラメター
base_estimatorestimator: instance, default=None
分類モデル
method: {‘sigmoid’, ‘isotonic’}, default=’sigmoid’
キャリブレーションの方法
cv: int, cross-validation generator, iterable or “prefit”, default=None
交差検定分割方法
n_job: sint, default=None
並行して実行するジョブ数
ensemble: bool, default=True
Trueの場合、base_estimatorはトレーニングデータを使用して適合され、テストデータを使用して調整されます
Falseの場合、cvは、cross_val_predictを介してバイアスのない予測を計算するために使用され、その後、キャリブレーションに使用されます。
2. 実験
環境:Colab
データセット:不均衡データを作成します。
モデル:SVC、SVC +キャリブレーション
モデル評価:AUC
2.1 環境設定
ライブラリのインポート
| from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC from sklearn.calibration import CalibratedClassifierCV |
2.2 データセット作成
不均衡データを作成します。
| # generate dataset X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) |
Yを確認して、1の値は少ないで不均衡データになっています。
| # count y print(‘Number of 0: ‘, np.count_nonzero(y == 0)) print(‘Number of 1: ‘,np.count_nonzero(y == 1)) |
2.3 SVC
SVCのベースモデルを作成します。AUC は0.808です。
| # SVC model = SVC(gamma=’scale’)
# モデル評価 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1) print(‘Mean ROC AUC: %.3f’ % mean(scores)) |
Mean ROC AUC: 0.808
2.4 SVC +キャリブレーションClassifierCV
キャリブレーションClassifierCVを追加して、AUC:は0.867になりました。
| # CalibratedClassifierCV + SVC model = SVC(gamma=’scale’) calibrated = CalibratedClassifierCV(model, method=’isotonic’, cv=3)
# モデル評価 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(calibrated, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1) print(‘Mean ROC AUC: %.3f’ % mean(scores))
|
Mean ROC AUC: 0.867
2.5 まとめ
不均衡データでSVCモデルとキャリブレーション付けSVCモデルを作成しました。キャリブレーション付けSVCモデルのモデル精度は0.06くらいに伸びました。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属