Skip to content
Main Menu
ホーム
サービス
事例紹介
分析ブログ
Menu Toggle
統計解析
機械学習
深属学習
Python
KERAS
Azure
Spark
Kaggle
予測分析
クラスター分析
分類分析
評価方法
正則化
可視化
問い合わせ
Search
Search for:
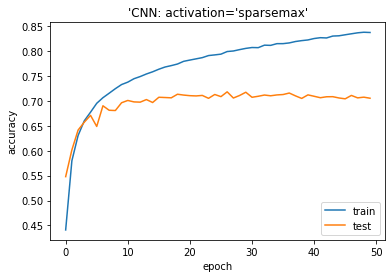
SPARSEMAX-activation-05
Post navigation
←
Previous Media