
目次
1. SPARSEMAX活性化関数の概要
1.1 SPARSEMAX活性化関数とは
1.2 SPARSEMAX関数
2. 実験
2.1 ライブラリインポート
2.2 データ読み込み
2.3 データ加工
2.4 SPARSEMAXの活性化関数を作成
2.5 RELUの活性化関数を作成
2.6 まとめ
関連記事:活性化関数のまとめ
1. SPARSEMAX活性化関数の概要
1.1 SPARSEMAX活性化関数とは
SPARSEMAXとは、ソフトマックスに似たが、スパース確率を出力できる新しい活性化関数です。SPARSEMAX損失関数は、滑らかで凸状のロジスティック損失のスパースアナログです。
1.2 SPARSEMAX関数

softmaxとsparsemaxの比較
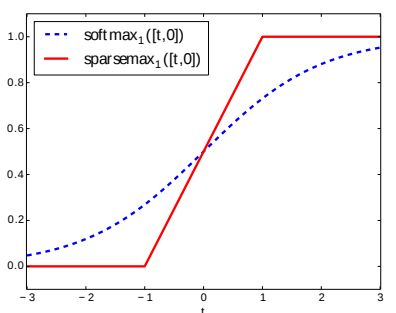
実験の結果
SPARSEMAXは、一般的なアクティベーションに比較して優れたパフォーマンスになります。 sparsemaxは、ラベルの数が多い問題に適しているようです。
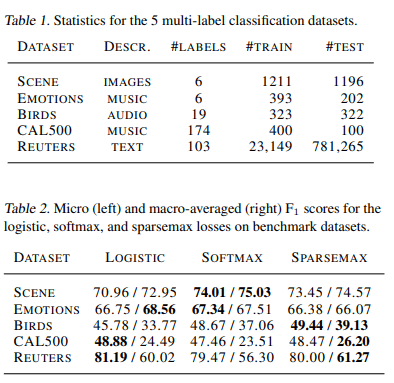
SPARSEMAXの論文:From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification.
https://arxiv.org/abs/1602.02068
TensorFlowの資料:https://www.tensorflow.org/addons/api_docs/python/tfa/activations/sparsemax
PyTorchの資料:https://github.com/KrisKorrel/sparsemax-pytorch
2. 実験
データセット:CIFAR-10 は、32×32 のカラー画像からなるデータセットで、その名の通り10クラスあります。全体画像数は60000件となり、そのうち50000件が訓練用データ、残り10000件がテスト用データに分けます。
モデル:SPARSEMAXの活性化関数のモデル vs Reluの活性化関数のモデル
モデル評価:Accuracy
2.1 ライブラリインポート
ライブラリのインストール
| !pip install tensorflow-addons |
| import tensorflow as tf import tensorflow_addons as tfa from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.2 データ読み込み
Tensorflowのデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
データを確認します。
| c # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |
2.3 データ加工
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.4 SPARSEMAXの活性化関数を作成
活性化関数のモデルを作成
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=tfa.activations.sparsemax, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=tfa.activations.sparsemax)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 2304) 0
_________________________________________________________________
dense (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 46s 7ms/step – loss: 2.0359 – accuracy: 0.2583 – val_loss: 1.6034 – val_accuracy: 0.4351 …
Epoch 50/50
500/500 [==============================] – 3s 6ms/step – loss: 0.8768 – accuracy: 0.6937 – val_loss: 1.2110 – val_accuracy: 0.7054
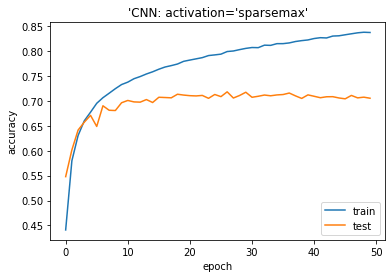
モデル評価
| # plotting the metrics
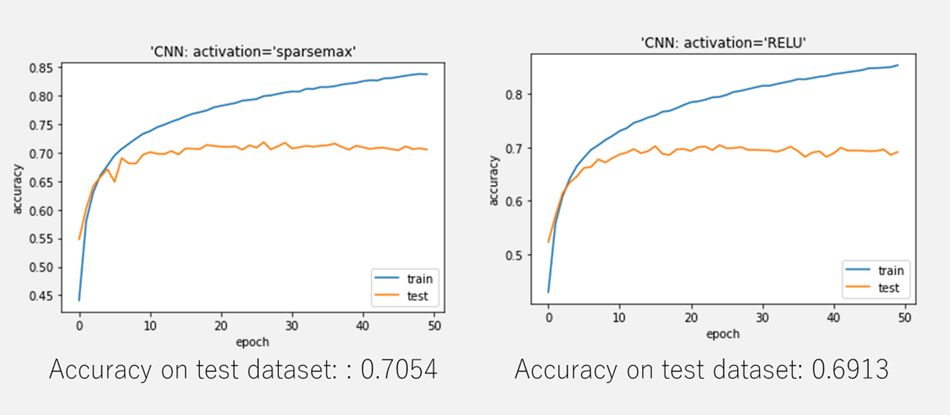
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: activation=’SPARSEMAX'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
| from sklearn.metrics import accuracy_score import numpy as np
y_pred_p = model.predict(X_test) y_pred = np.argmax(y_pred_p,axis=1)
acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.7054
2.5 Reluの活性化関数を作成
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model2 = Sequential() model2.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model2.add(MaxPool2D()) model2.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model2.add(MaxPool2D()) model2.add(Flatten()) model2.add(Dense(10, activation=’softmax’)) model2.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model2.summary())
|
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| model2.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
history2 = model2.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test))
|
Epoch 1/50
500/500 [==============================] – 3s 6ms/step – loss: 1.8103 – accuracy: 0.3455 – val_loss: 1.3376 – val_accuracy: 0.5236
…
Epoch 50/50
500/500 [==============================] – 3s 5ms/step – loss: 0.4076 – accuracy: 0.8583 – val_loss: 1.1002 – val_accuracy: 0.6913
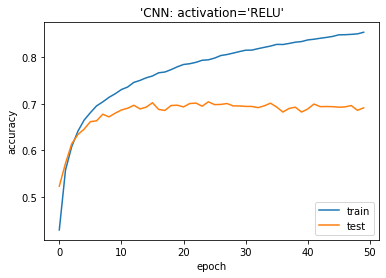
| # plotting the metrics
plt.plot(history2.history[‘accuracy’]) plt.plot(history2.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: activation=’RELU'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
| from sklearn.metrics import accuracy_score
y_pred = model2.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6913
2.6 まとめ
CIFAR-10のデータセットで、SPARSEMAXの活性化関数のモデル と RELUの活性化関数のモデルを作成しました。RELU に対して、SPARSEMAXの精度が同じくらいでした。

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属