関連記事: U-net(画像セグメンテーション)の解説
先日の記事はU-net(画像セグメンテーション)の解説について解説しました。画像認識技術は画像分類・物体検出・セグメンテーションなどの技術があります。今回の記事は画像認識技術の違いを開設したいと思います。
目次
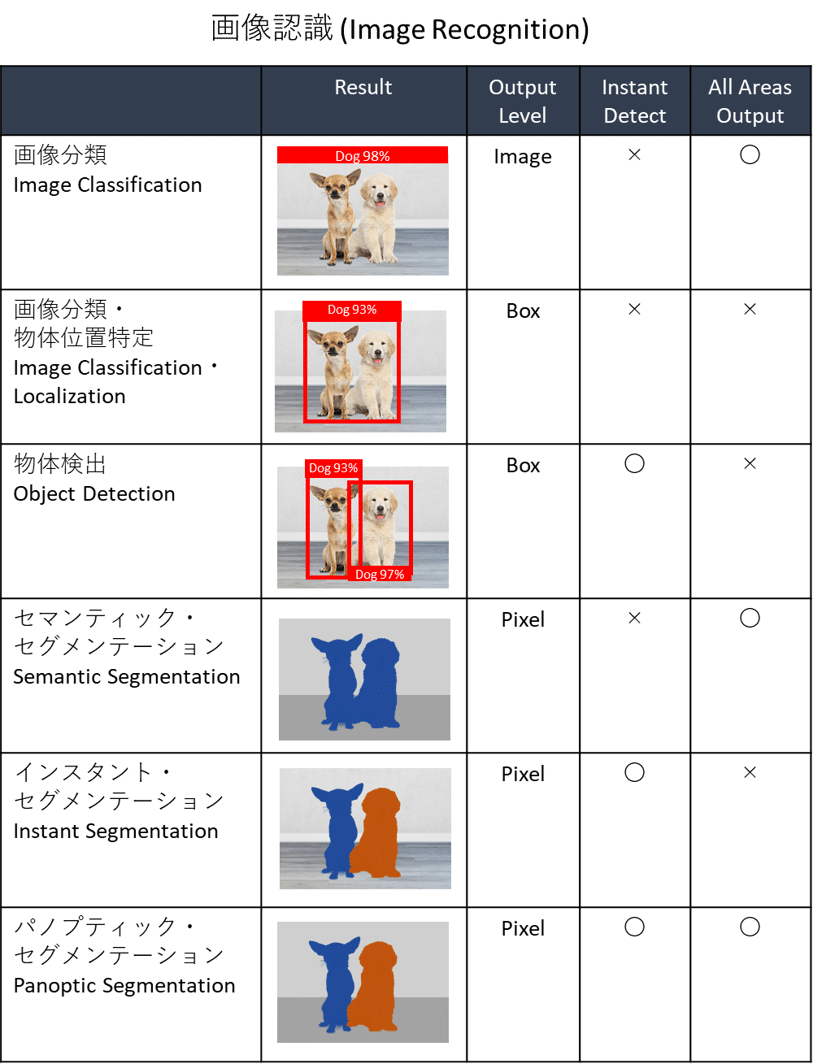
1. 画像認識(Image Recognition)とは
2. 画像分類(Image Classification)とは
3. 画像分類・物体位置特定(Image Classification・Localization)とは
4. 物体検出(Object Detection)とは
5. セグメンテーション(Segmentation)
_5.1 セマンティック・セグメンテーション(Semantic Segmentation)とは
_5.2 インスタント・セグメンテーション(Instant Segmentation)とは
_5.3 パノプティック・セグメンテーション(Panoptic Segmentation)とは
6. まとめ
1. 画像認識(Image Recognition)とは
画像認識(Image Recognition)とは、画像や動画データから特徴をつかみ、対象物を識別するパターン認識技術の一つです。画像データから、対象物や、対象物の特徴(形状、寸法、数、明暗、色など)を抽出/分析/識別して認識検出する手法です。
コンピュータが画像認識を行うためには、前段階として、画像から対象物を抽出する必要があります。
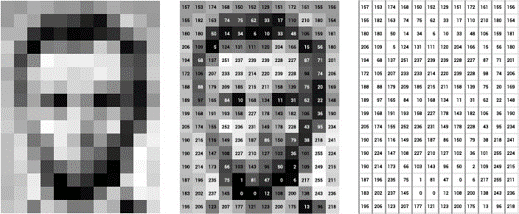
下記の8ビットのグレースケール画像から、すべてのデジタル画像は0〜255の範囲の値を持つピクセルによって形成されます。0は黒、255は白です。 カラフルな画像の場合は、赤、緑、青の3つのマップと、0〜255の範囲のすべてのピクセルが含まれます。
画像認識を利用することで、顔認証システムや不審者検知、文字認識(OCR)、不適切画像の検出、
工場でのイレギュラー検知など幅広い分野で活用することができます。
今回の記事は物体検出の分野を中心にします。
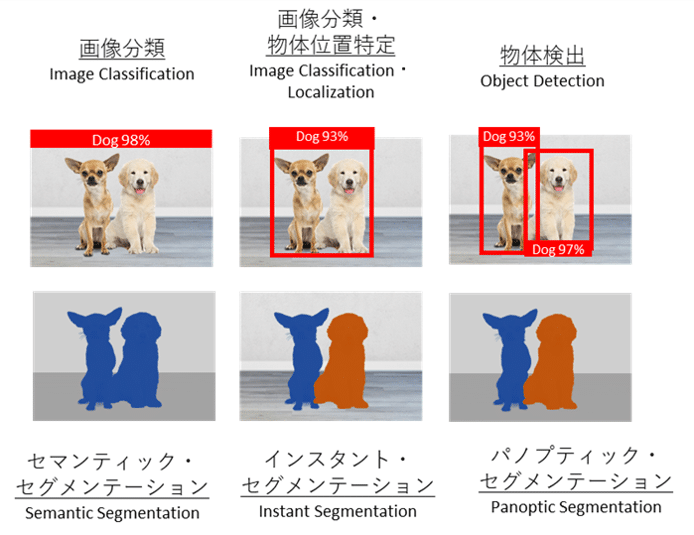
2. 画像分類(Image Classification)とは
画像分類とは、機械学習やディープラーニングモデルで、画像を何らかの主題に基づき分類する処理方法です。いくつかの分類手法があります。教師あり学習では、ラベル付けされたデータセットを用いて、モデルを学習させていきます。
画像分類の結果は各クラスの予測信頼度です。

classes = [“dog”, “cat”, “nothing”] prediction = [ 0.8 , 0.1 , 0.15]
代表的なモデル:
Xception
https://arxiv.org/abs/1610.02357
VGG
https://arxiv.org/pdf/1409.1556.pdf
ResNet
https://arxiv.org/abs/1512.03385
Inception
https://arxiv.org/abs/1409.4842
MobileNet
https://arxiv.org/abs/1704.04861
DenseNet
https://arxiv.org/abs/1608.06993
代表的な評価指標:混合行列(Confusion Matrix)、正解率(Accuracy)、適合率(Precision)、再現率(Recall)、F値(F-measure)
3. 画像分類・物体位置特定(Image Classification・Localization)とは
画像分類・物体位置特定とは、画像内のクラスと物体の位置を検出する方法です。画像から物体のクラスを予測する代わりに、クラスとその物体を含む矩形(バウンディングボックスという)を予測する必要があります。1つの画像は1つのクラスを検出します。
モデルの結果はクラス名、クラスの予測信頼度、バウンディングボックスです。

# class label classes = [“dog”] prediction = [ 0.8] # Bounding Box legend = [ “X-Position", "Y-Position", "Length", Height”] prediction = [130, 285, 100, 185]
代表的な評価指標:mAP、IoU
4. 物体検出(Object Detection)とは
物体検出とは 画像内のクラスと物体の位置を検出しますが、複数種類の物体を1つの画像で検出すると、マルチクラスの物体検出です。入力画像から固定サイズのウィンドウをすべての可能な位置で取得して、これらのパッチ(領域)を画像分類器に入力します。
モデルの結果はクラス名、クラスの予測信頼度、バウンディングボックスです。

# class label classes = [“dog”, “dog”] prediction = [ 0.98, 0.97] # Bounding Box legend = [ “X-Position", "Y-Position", "Length", Height”] prediction = [130, 285, 100, 185], [130, 285, 100, 185]
代表的なモデル:
R-CNN
https://arxiv.org/abs/1311.2524
Fast R-CNN
https://arxiv.org/abs/1504.08083
SSD: Single Shot MultiBox Detector
https://arxiv.org/abs/1512.02325
Mask R-CNN
https://arxiv.org/abs/1703.06870
YOLOv3: An Incremental Improvement
https://arxiv.org/abs/1804.02767
RetinaNet
https://arxiv.org/abs/1905.10011
代表的な評価指標:mAP(mean Average Precision)、IoU(Intersection over Union)
5.1 セマンティック・セグメンテーション(Semantic Segmentation)とは
セマンティック・セグメンテーションとは 画像のピクセルを「どの物体クラス(カテゴリー)に属するか」で分類する方法です。画像上の全ピクセルをクラスに分類することです。同クラス間で重なりがある場合、同クラスの領域として認識するため、物体ごとの認識・カウントができません。
モデルの結果は各ピクセルのクラス情報です。

代表的なモデル:
U-NET
https://arxiv.org/abs/1505.04597
MULTISCALE
https://ieeexplore.ieee.org/document/568922
代表的な評価指標:IoU and per-pixel accuracy
5.2 インスタント・セグメンテーション(Instant Segmentation)とは
インスタント・セグメンテーションとは 画像のピクセルを「どの物体クラス(カテゴリー)に属するか、どのインスタンスに属するか」で分類する方法です。物体ごとの領域を分割しかつ物体の種類を認識することです。RoI(region of interest)に対して segmentation を行うので、画像全てのピクセルに対してラベルを振ることは行いません。
モデルの結果は各ピクセルのクラス情報です。

代表的なモデル:
Mask R-CNN
https://arxiv.org/abs/1703.06870
DeepMask
https://github.com/facebookresearch/deepmask
FCIS
https://arxiv.org/abs/1611.07709
代表的な評価指標:
average precision over different IoU thresholds
5.3 パノプティック・セグメンテーション(Panoptic Segmentation)とは
パノプティック・セグメンテーションはSemantic Segmentation とInstance Segmentationを組み合わせた方法です。全てのピクセルにラベルが振られ、かつ数えられる物体に関しては、個別で認識した結果が返されます。
モデルの結果は各ピクセルのクラス情報です。

代表的なモデル:
Panoptic Feature Pyramid Network
https://arxiv.org/abs/1901.02446
UPSNet
https://arxiv.org/abs/1901.03784
代表的な評価指標:
Panoptic Quality (PQ)
6. まとめ
今回は画像分類(Image Classification)、画像分類・物体位置特定(Image Classification・Localization)、物体検出(Object Detection)、セマンティック・セグメンテーション(Semantic Segmentation)、インスタント・セグメンテーション(Instant Segmentation)、パノプティック・セグメンテーション(Panoptic Segmentation)を紹介しました。下記の表に6つの画像認識技術をまとめました。