Kaggleなどのデータ分析競技といえば、XGBoost, Light GBM, CatBoost の決定木アルゴリズムをよく使われています。分類分析系と予測分析系の競技のKaggleの上位にランクされています。今回の記事はCatBoostの新しい決定木アルゴリズムを解説します。
目次
1. CatBoostとは
2. 実験・コード
__2.1 データロード
__2.2 10,000件くらいサンプルデータを作成
__2.3. XGBoost グリッドサーチで 81モデルから最適なパラメータを探索
__2.4 XGBoost 最適なパラメータのモデルを作成
__2.5. Light GBM グリッドサーチで 81モデルから最適なパラメータを探索
__2.6 Light GBM最適なパラメータのモデルを作成(Categorial Feature除く)
__2.7 Light GBM最適なパラメータのモデルを作成(Categorial Feature含む)
__2.8. CatBoost グリッドサーチで 81モデルから最適なパラメータを探索
__2.9 CatBoost 最適なパラメータのモデルを作成(Categorial Feature除く)
__2.10 CatBoost 最適なパラメータのモデルを作成(Categorial Feature含む
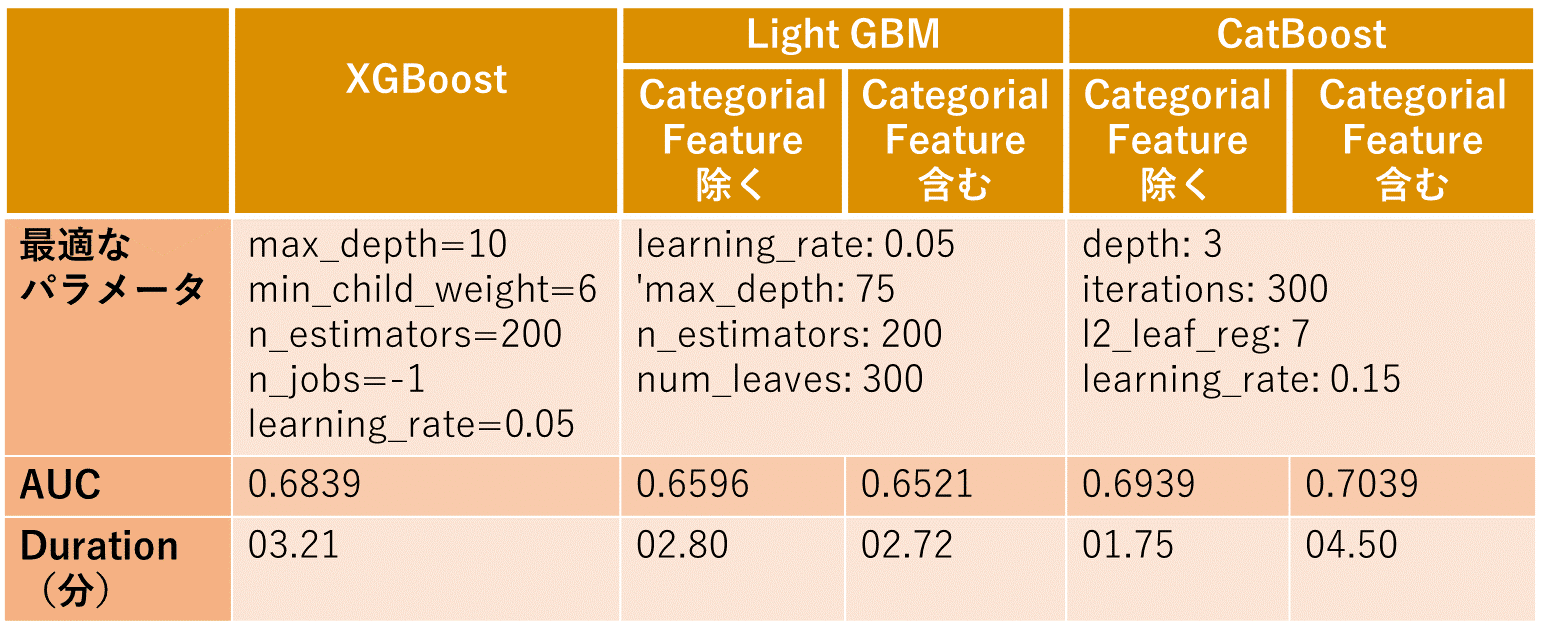
3. モデル評価評価:学習時間 AUC
1. CatBoostとは
CatBoostはCategory Boostingの略で、決定木ベースの勾配ブースティングに基づく機械学習ライブラリ。2017にYandex社からCatBoostが発表されました。
特徴:
1)回帰予測、分類の教師あり学習に対応
2)過学習を減らして、高い精度、学習速度を誇る
3)GPU、マルチGPUに対応
決定木ベースのアルゴリズムの歴史

CatBoostは、オーバーフィットを減らし、データセット全体をトレーニングに使用できるようにする、より効率的な戦略を使用します。
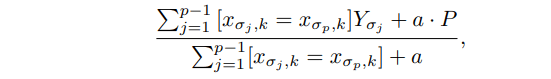
Pおよびパラメーターa> 0(事前分布の重み)。
最初のイテレーションで、アルゴリズムは最初のツリーを学習してトレーニングエラーを減らします。通常、このモデルには重大なエラーがあります。 データをオーバーフィットするため、ブースティングで非常に大きなツリーを構築することはお勧めできません
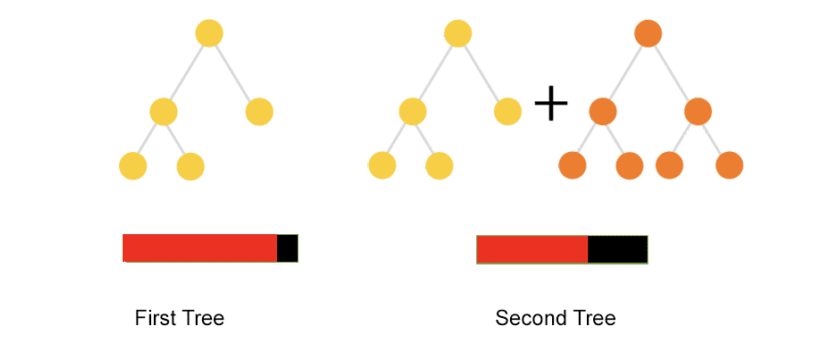
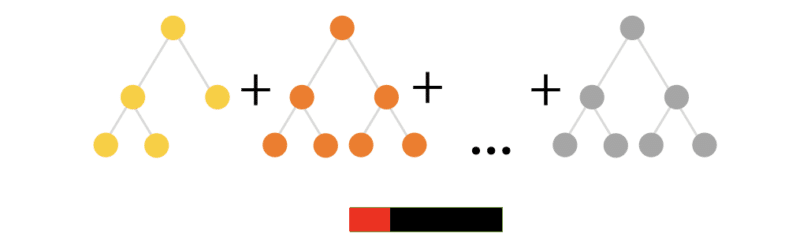
2番目のイテレーション。アルゴリズムはもう1つのツリーを学習して、最初のツリーで発生したエラーを減らします。 アルゴリズムは、適切な品質モードを構築するまでこの手順を繰り返します。
CatBoostの論文: http://learningsys.org/nips17/assets/papers/paper_11.pdf
CatBoostのライブラリ – https://catboost.ai/
2. 実験・コード
環境:google colab Python3 GPU
ライブラリ:XGboost、Light GBM、CatBoost
2.1 データロード
データセット:2015 Flight Delays (5,819,079行、565MB) The U.S. Department of Transportation’s (DOT) US米国の交通統計局により、フライトの遅延とキャンセルのデータ
(https://www.kaggle.com/usdot/flight-delays)
%%time import pandas as pd data_path = "/content/drive/My Drive/dataset/flights/flights.csv" data = pd.read_csv(data_path)
CPU times: user 15.3 s, sys: 362 ms, total: 15.7 s
Wall time: 16.2 s
data.head(3)

2.2 サンプルデータ作成
data = data.sample(frac = 0.002, random_state=10) print(data.count())
YEAR 11638
MONTH 11638
DAY 11638
DAY_OF_WEEK 11638
AIRLINE 11638
FLIGHT_NUMBER 11638
TAIL_NUMBER 11594
ORIGIN_AIRPORT 11638
DESTINATION_AIRPORT 11638
SCHEDULED_DEPARTURE 11638
DEPARTURE_TIME 11427
DEPARTURE_DELAY 11427
TAXI_OUT 11424
WHEELS_OFF 11424
SCHEDULED_TIME 11638
ELAPSED_TIME 11394
AIR_TIME 11394
DISTANCE 11638
WHEELS_ON 11421
TAXI_IN 11421
SCHEDULED_ARRIVAL 11638
ARRIVAL_TIME 11421
ARRIVAL_DELAY 11394
DIVERTED 11638
CANCELLED 11638
CANCELLATION_REASON 214
AIR_SYSTEM_DELAY 2148
SECURITY_DELAY 2148
AIRLINE_DELAY 2148
LATE_AIRCRAFT_DELAY 2148
WEATHER_DELAY 2148
dtype: int64
データ加工
%%time
import numpy as np
import time
from sklearn.model_selection import train_test_split
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"],
random_state=10, test_size=0.25)CPU times: user 70.6 ms, sys: 823 µs, total: 71.4 ms
Wall time: 71.6 ms
XGBoost
2.3. XGBoost グリッドサーチで 81モデルから最適なパラメータを探索
import xgboost as xgb
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
from datetime import datetime
start_time = datetime.now()
# パラメータ調整
model = xgb.XGBClassifier()
param_dist = {"max_depth": [10,30,50],
"min_child_weight" : [1,3,6],
"n_estimators": [200],
"learning_rate": [0.05, 0.1,0.16],}
# グリッドサーチの設定
xgb_grid_search = GridSearchCV(model, param_grid=param_dist, cv = 3, verbose=3, n_jobs=-1, scoring="roc_auc")
xgb_grid_search.fit(train, y_train)
print(xgb_grid_search.best_params_)
print(xgb_grid_search.best_index_)
print(xgb_grid_search.best_score_)
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))
Fitting 3 folds for each of 27 candidates, totalling 81 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 28 tasks | elapsed: 1.4min
[Parallel(n_jobs=-1)]: Done 81 out of 81 | elapsed: 3.7min finished
{'learning_rate': 0.05, 'max_depth': 10, 'min_child_weight': 6, 'n_estimators': 200}
2
0.6766358303944008
Duration: 0:03:46.873801
2.4 XGBoost 最適なパラメータのモデルを作成
start_time = datetime.now()
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
xgb_model = xgb.XGBClassifier(max_depth=10, min_child_weight=6, n_estimators=200, n_jobs=-1 , verbose=1,learning_rate=0.05)
# モデルを学習
xgb_model.fit(train,y_train)
# AUCのモデル評価
print("AUC =", auc(xgb_model, train, test))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))AUC = (0.977650094493346, 0.6839265704161672)
Duration: 0:00:03.215976
Light GBM
2.5. Light GBM グリッドサーチで 81モデルから最適なパラメータを探索
import lightgbm as lgb
from sklearn import metrics
from datetime import datetime
start_time = datetime.now()
# パラメータ調整
lg = lgb.LGBMClassifier(silent=False)
param_dist = {"max_depth": [25,50, 75],
"learning_rate" : [0.01,0.05,0.1],
"num_leaves": [300,900,1200],
"n_estimators": [200]
}
# グリッドサーチの設定
lg_grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 3, scoring="roc_auc", verbose=5)
lg_grid_search.fit(train,y_train)
print(lg_grid_search.best_params_)
print(lg_grid_search.best_index_)
print(lg_grid_search.best_score_)
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))Fitting 3 folds for each of 27 candidates, totalling 81 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 14 tasks | elapsed: 20.1s
/usr/local/lib/python3.6/dist-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak.
"timeout or by a memory leak.", UserWarning
[Parallel(n_jobs=-1)]: Done 68 tasks | elapsed: 1.6min
[Parallel(n_jobs=-1)]: Done 81 out of 81 | elapsed: 1.9min finished
{'learning_rate': 0.05, 'max_depth': 75, 'n_estimators': 200, 'num_leaves': 300}
15
0.6704275313151552
Duration: 0:01:58.034424
2.6 Light GBM最適なパラメータのモデルを作成(Categorial Feature除く)
# Categorical Features除く
start_time = datetime.now()
def auc2(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict(train)),
metrics.roc_auc_score(y_test,m.predict(test)))
# データセットの設定
d_train = lgb.Dataset(train, label=y_train, free_raw_data=False)
params = {"max_depth": 75, "learning_rate" : 0.05, "num_leaves": 300, "n_estimators": 200}
# Categorical Features除く
lgb_model = lgb.train(params, d_train)
print("AUC =", auc2(lgb_model, train, test))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))AUC = (1.0, 0.6596555518539831)
Duration: 0:00:02.807290
2.7 Light GBM最適なパラメータのモデルを作成(Categorial Feature含む)
# Catgeorical Features含む
start_time = datetime.now()
cate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT"]
lgb_model = lgb.train(params, d_train, categorical_feature = cate_features_name)
print("AUC =", auc2(lgb_model, train, test))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))AUC = (1.0, 0.6521800579464349)
Duration: 0:00:02.723219
CatBoost
2.8. CatBoost グリッドサーチで 81モデルから最適なパラメータを探索
!pip install catboost
Collecting catboost
Downloading https://files.pythonhosted.org/packages/39/51/bfab1d94e2bed6302e3e58738b1135994888b09f29c7cee8686d431b9281/catboost-0.17.3-cp36-none-manylinux1_x86_64.whl (62.5MB)
|████████████████████████████████| 62.5MB 74.6MB/s
Requirement already satisfied: plotly in /usr/local/lib/python3.6/dist-packages (from catboost) (4.1.1)
Requirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from catboost) (0.10.1)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from catboost) (3.0.3)
Requirement already satisfied: pandas>=0.24.0 in /usr/local/lib/python3.6/dist-packages (from catboost) (0.24.2)
Requirement already satisfied: numpy>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from catboost) (1.16.5)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from catboost) (1.12.0)
Requirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from catboost) (1.3.1)
Requirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.6/dist-packages (from plotly->catboost) (1.3.3)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost) (2.4.2)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost) (1.1.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost) (0.10.0)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost) (2.5.3)
Requirement already satisfied: pytz>=2011k in /usr/local/lib/python3.6/dist-packages (from pandas>=0.24.0->catboost) (2018.9)
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from kiwisolver>=1.0.1->matplotlib->catboost) (41.2.0)
Installing collected packages: catboost
Successfully installed catboost-0.17.3
2.8. CatBoost グリッドサーチで 81モデルから最適なパラメータを探索
import catboost as cb
from datetime import datetime
start_time = datetime.now()
# パラメータ調整
params = {'depth': [3, 5, 7],
'learning_rate' : [0.03, 0.1, 0.15],
'l2_leaf_reg': [1,3,7],
'iterations': [300]}
ctb = cb.CatBoostClassifier(eval_metric="AUC", logging_level='Silent')
ctb_grid_search = GridSearchCV(ctb, params, scoring="roc_auc", cv = 3, verbose=2)
ctb_grid_search.fit(train, y_train)
print(ctb_grid_search.best_params_)
print(ctb_grid_search.best_index_)
print(ctb_grid_search.best_score_)
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))Fitting 3 folds for each of 27 candidates, totalling 81 fits
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03 ......
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03, total= 1.4s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03 ......
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 1.4s remaining: 0.0s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03 ......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.03, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1 .......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1 .......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1 .......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.1, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15 ......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15 ......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15 ......
[CV] depth=3, iterations=300, l2_leaf_reg=1, learning_rate=0.15, total= 1.3s
[CV] depth=3, iterations=300, l2_leaf_reg=3, learning_rate=0.03 ......
[CV] depth=3, iterations=300, l2_leaf_reg=3, learning_rate=0.03, total= 1.4s
[CV] depth=3, iterations=300, l2_leaf_reg=3, learning_rate=0.03 ......
...........
[CV] depth=7, iterations=300, l2_leaf_reg=7, learning_rate=0.15, total= 3.2s
[Parallel(n_jobs=1)]: Done 81 out of 81 | elapsed: 2.9min finished
{'eval_metric': 'AUC', 'logging_level': 'Silent', 'depth': 3, 'iterations': 300, 'l2_leaf_reg': 7, 'learning_rate': 0.15}
{'depth': 3, 'iterations': 300, 'l2_leaf_reg': 7, 'learning_rate': 0.15}
8
0.6888360823801398
Duration: 0:02:58.684757
2.9 CatBoost 最適なパラメータのモデルを作成(Categorial Feature除く)
# Categorical features除く
start_time = datetime.now()
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=3, iterations= 300, l2_leaf_reg= 7, learning_rate= 0.15, logging_level='Silent')
clf.fit(train,y_train)
print("AUC =", auc(clf, train, test))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))UC = (0.7868498404068541, 0.6939698499709401)
Duration: 0:00:01.753843
2.10 CatBoost 最適なパラメータのモデルを作成(Categorial Feature含む)
# Categorical features含む
start_time = datetime.now()
cat_features_index = [0,1,2,3,4,5,6]
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=3, iterations= 300, l2_leaf_reg= 7, learning_rate= 0.15, logging_level='Silent')
clf.fit(train,y_train, cat_features= cat_features_index)
print("AUC =", auc(clf, train, test))
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))AUC = (0.7894243204961788, 0.7039958234724883)
Duration: 0:00:04.504826
3. モデル評価評価:学習時間 AUC
XGNoost, Light GBM, CatBoostの決定木モデルを比較しました。予測精度は CatBoostが最も良くて、特にCategorial Feature含むのモデルです(0.7039)。実行時間を見ると、早いモデルはCategorial Feacture除くのCatBoostだが、一番遅いモデルはCategorial Feature含むのCatBoostingです。