前回はkaggleコンペの「メルカリにおける値段推定」の1位の解析手法を話しました。内容が長いなので、3つの記事に分けました。今回は「Home Credit Default Risk 債務不履行の予測」のモデル作成について書きます。
目次
1. Home Credit Default Riskのコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の特徴量エンジニアリング
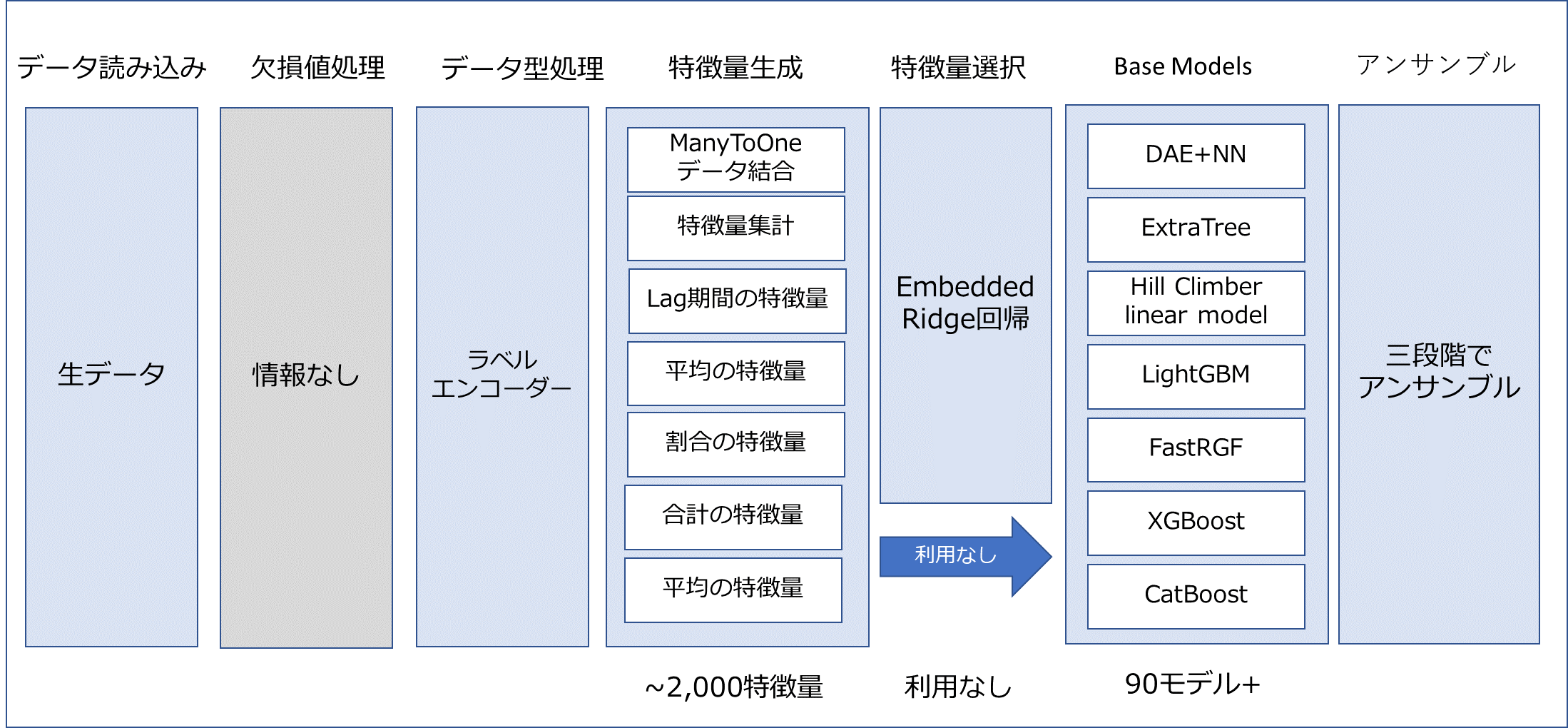
___2.1 特徴量生成
___2.2 カテゴリカル特徴量の処理
___2.3 特徴量選択
3. 1位のモデル作成
___3.1 3.1 Base Models
___3.2 アンサンブル学習(Ensemble learning)
___3.3 その他
3.1位のモデル作成
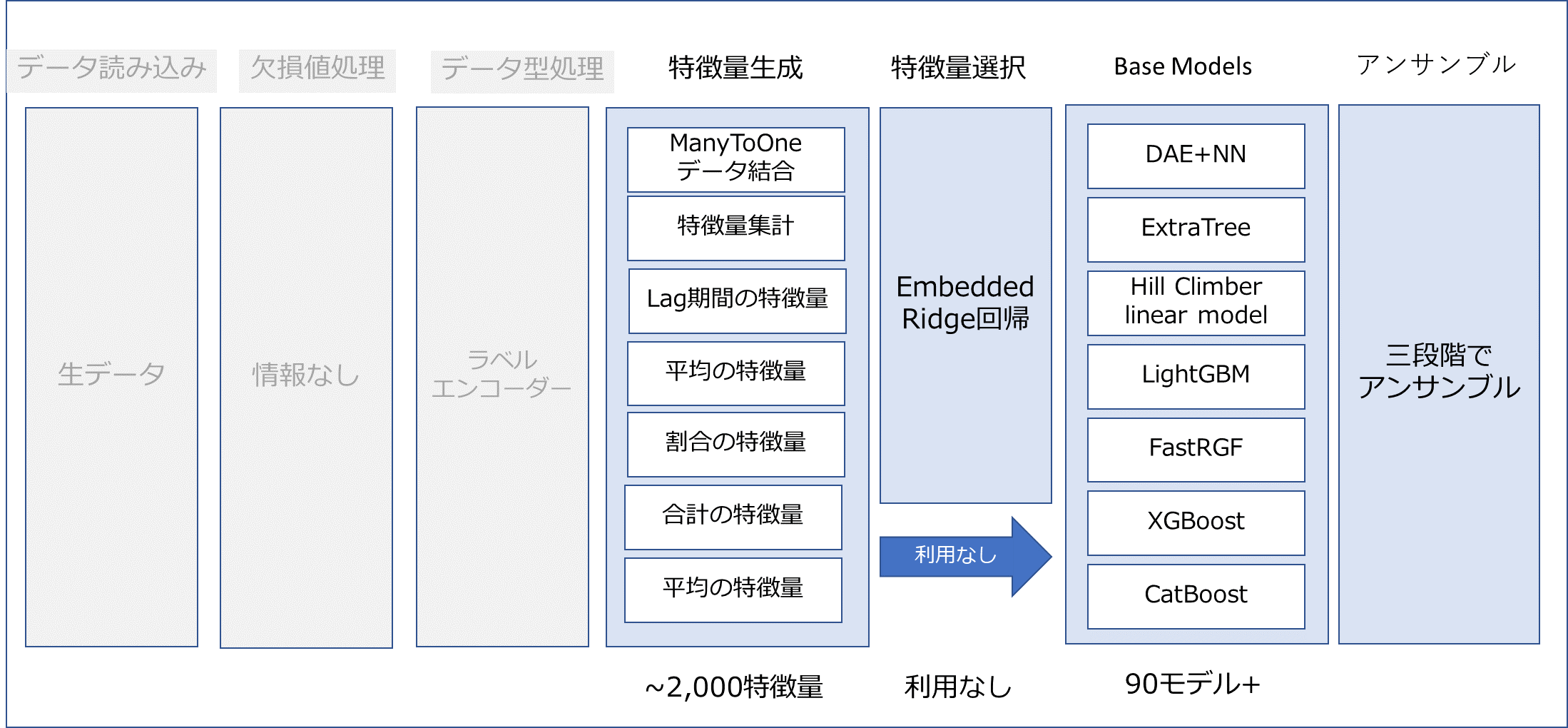
3.1 Base Models
モデル評価はStratifiedKFold, with 5-folds交差検証(Cross Validation)を利用しました。Stratified 普通のk-foldとも比較したが今回は大きな差はありません。
交差検証 (Cross Validation)
交差検定では、用意したデータをK個に分割して、1回目はそのうちの一つをテストデータ、それ以外を学習データとして、学習・評価します。2回目は1回目と異なる別のデータをテストデータとして使い、3回目は1,2回目と異なるデータで評価をします。そして、各回で測定した精度の平均を取ります。
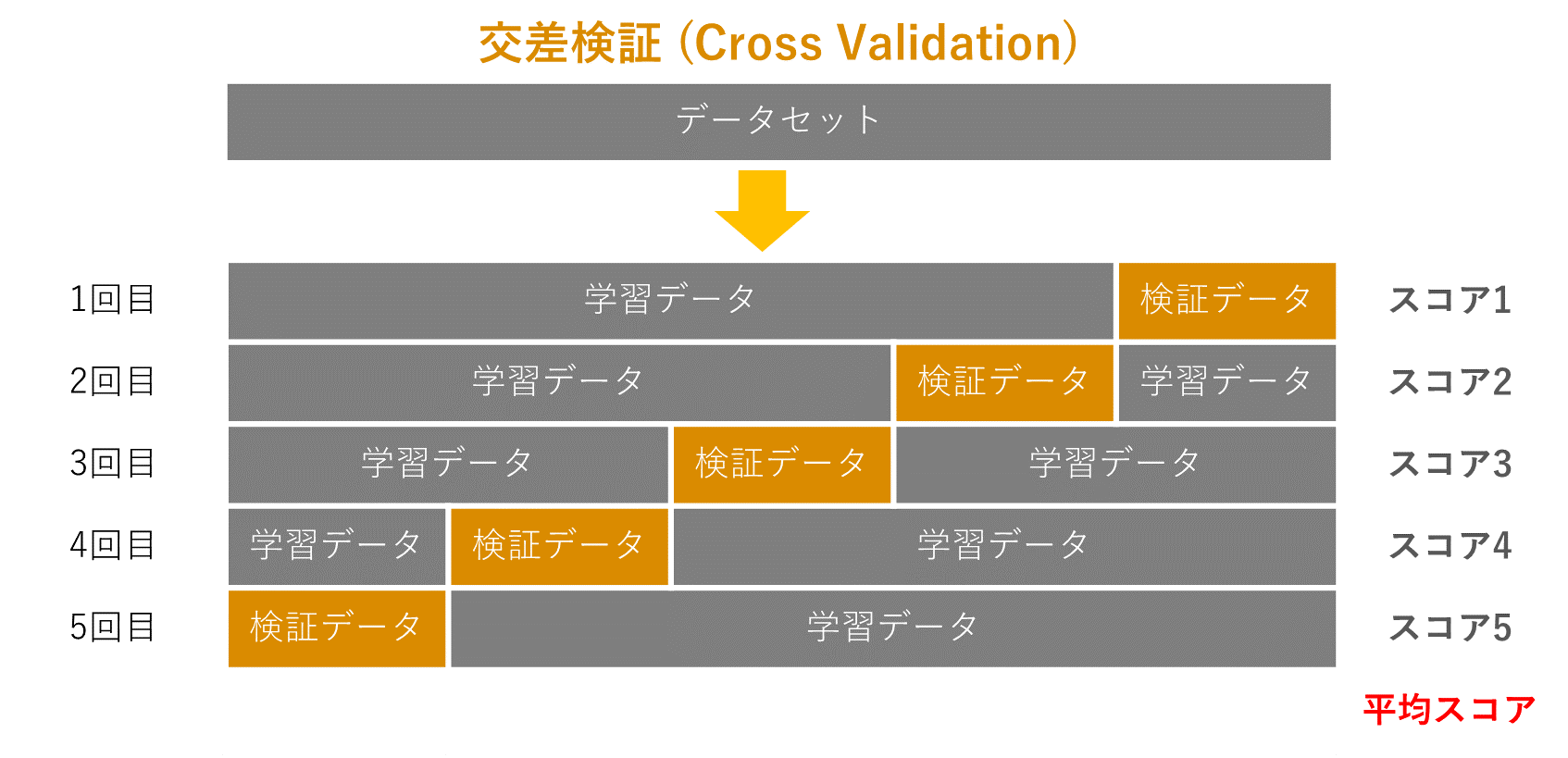
交差検証の説明はこちらです。
・LightGBM, XGBoost, FastRGF, FFM を使ったがCVは良くなかった。
・Catboostはあまり性能良くなかったが、結果の多様性的に良かったと思っています。
・ExtraTrees はCVが高かった。(CV: 0.80665, LB:80842, PB: 80565)(パラメタ:maxdepth=4 highly regularized minsamplesleaf=1000)
・DAE+NN (Denoising Auto Encoder Neural Network)がNN単体よりもいい精度が出た
NNのパラメータ設定:
入力データは 正規化してrankGaussにします。
欠損値は0. Iに変換しました。
DAE: swapnoise=0.2, 1000 epochs, Supervised nn: lRate=2.5e-5, dropout=0.5, 50 epochs approx (until overfitting), logloss optimized. 最初の教師なしDAEは10000-10000-10000NN.
隠れ層は1000-1000 NN, ReLU, Optimizer SGD, minibatchsize=128, small lRateDecay。
GTX1080Tiで約1日がかかりました。
各モデルの説明は:
LightGBM
FastRGF(Fast Regularized Greedy Forest)
FFM(Field-aware Factorization Machines)
3.2 アンサンブル学習(Ensemble learning)
アンサンブル学習とは、個々に学習した複数の学習器を融合させて汎化能力(未学習データに対する予測能力)を向上させ、一つの学習器を作成することをアンサンブル学習と呼ばれます。
三段階でアンサンブルを行った。
レベル1ではNN, XGBoost, LightGBM, Hill Climber linear model
レベル2のレイヤーではNN, ExtraTreeとHill Climber
最終層では3つのモデルの平均を利用します。
1層500ReLUユニットのNNをstackingにりようしました。(lRate=1e-3 , lRateDecay=0.96, dropout=0.3)
3.3 その他
あまりハイパーパラメータチューニングに時間をかけられなかった
特徴量を補完しようとしたがそこまで役には立たなかった。(imputed features)
まとめ
体のパイプラインは下記の図です。