目次
1. ASHRAE 消費エネルギー予測のコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
2. 1位の解析手法
___2.1 前処理
___2.2 フィギュア・エンジニアリング
___2.3 モデル
2. 1位の解析手法
Isamu & Mattのチームのコメントを解説します。
https://www.kaggle.com/c/ashrae-energy-prediction/discussion/124709
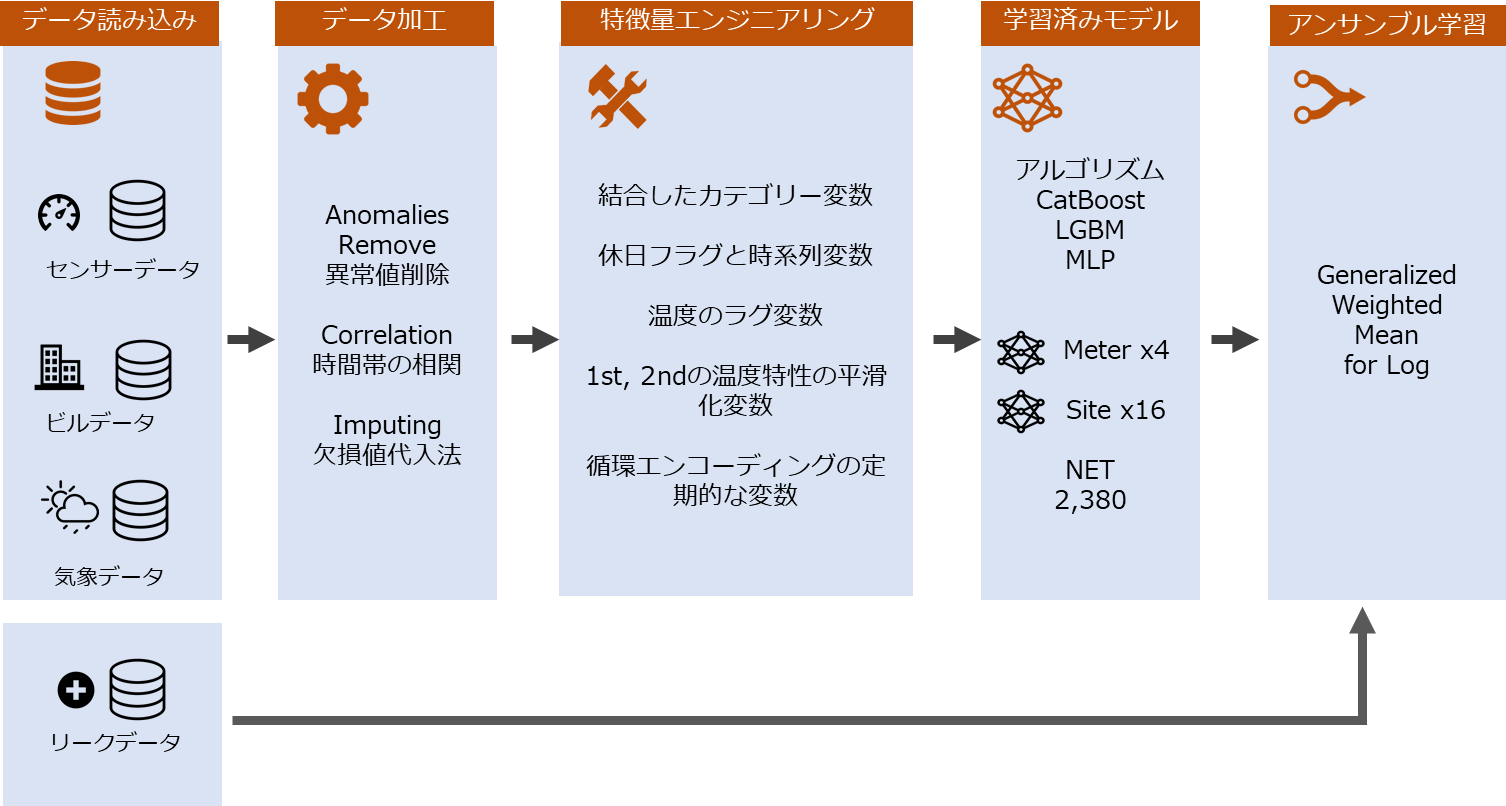
2.1 前処理
2.1.1 異常値削除(Remove anomalies)
このコンペでは、データのクリーンアップが非常に重要でした。 想定されているのは、データに予測不可能な、したがって学習不可能な異常があり、トレーニングされた場合、予測の品質が低下するということです。 3種類の異常を特定して除外しました。
1.長い定数値
2.大きな正/負のスパイク
3.目視検査によって決定された追加の異常
これらの異常のいくつかは、サイトの複数の建物にわたって一貫していることがわかりました。 サイト内のすべての建物を使用して潜在的な異常を検証しました。複数の建物で同時に異常が発生した場合、これが実際に真の異常であると合理的に確信できます。 これにより、必ずしも一定値の長いストリークや大きなスパイクの一部ではない異常を取り除くことができました。
2.1.2 温度のデータを欠損値代入法Impute Missing Temperature Values
温度メタデータに多くの欠損値がありました。 線形補間を使用して欠落データを補完することがわかりました。
2.1.3 タイムゾーンの加工(Local Time Zone Correlation)
トレイン/テストデータのタイムゾーンは、気象メタデータのタイムゾーンとは異なりましたので、タイムゾーンのデータを加工しました。
2.1.4 ラベルの加工(Target Transformations)
最初はlog1p(meter_reading)を予測しました。site 0のkBTUをkWhに変換します。最後はlog1p(meter_reading/square_feet)の標準化にしました。(スコアが0.002上がった)
2.2 フィギュア・エンジニアリング
このコンペでは、機能エンジニアリングと機能選択にさまざまなアプローチを採用しました。下記の関数はモデルに強化関数:
・building_id と meterを結合して、カテゴリー変数
・休日フラグと時間の時系列変数
・温度のラグ変数
・Savitzky-Golayのフィルターで1st, 2ndの温度特性の平滑化変数
・循環エンコーディングの定期的な変数(hour_x = cos(2*pi*hour/24) and hour_y = sin(2*pi*hour/24))
2.3 モデル
複数なサブセットでCatBoost, LightGBM, とMLP のモデル作成しました。
・meterことに1モデル
・site_id ことに1モデル
・meterとsite_idことに1モデル
関連記事:
モデル検定
このコンテストで検証にさまざまなアプローチを試みました。検証セットとして連続した月を使用してK-Fold CVを試しました。さまざまな検証スキームを試すことで、最終的なアンサンブルに多様性を追加するモデルをトレーニングできました。次のコードは、検証月を取得する1つの方法を示しています。
import numpy as np def get_validation_months(n): ... return [np.arange(i, i+n) % 12 + 1 for i in range(12)] ... get_validation_months(6) [array([1, 2, 3, 4, 5, 6]), array([2, 3, 4, 5, 6, 7]), array([3, 4, 5, 6, 7, 8]), array([4, 5, 6, 7, 8, 9]), array([ 5, 6, 7, 8, 9, 10]), array([ 6, 7, 8, 9, 10, 11]), array([ 7, 8, 9, 10, 11, 12]), array([ 8, 9, 10, 11, 12, 1]), array([ 9, 10, 11, 12, 1, 2]), array([10, 11, 12, 1, 2, 3]), array([11, 12, 1, 2, 3, 4]), array([12, 1, 2, 3, 4, 5])]
アンサンブル学習(Ensembling)
パブリックLBへの過剰適合のリスクを低減し、ロバスト性を向上させるために、さまざまなモデルからの予測をアンサンブルしました。 ここに私たちがしたことのいくつかがあります:
・クリーンアップされたリークデータをホールドアウトセットとして使用して、第2ステージモデルを調整しました。
・平均ログ値を利用しました。expm1(mean(log1p(x)))
・一般化された加重平均を使用し、Optunaを使用してパラメーターを調整しました。
関連記事:
アンサンブル学習(Ensemble learning)解説と実験
Generalized mean
加重一般化平均を使用しました。
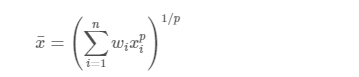
ライブラリのインポート
import os import optuna import numpy as np import pandas as pd import seaborn as sns from functools import partial from sklearn.metrics import mean_squared_error
データロード
%%time
root = '../input/ashrae-feather-format-for-fast-loading'
test = pd.read_feather(f'{root}/test.feather')
meta = pd.read_feather(f'{root}/building_metadata.feather')リークデータをロード
leak = pd.read_feather('../input/ashrae-leak-data-station/leak.feather')
leak.fillna(0, inplace=True)
leak = leak[(leak.timestamp.dt.year > 2016) & (leak.timestamp.dt.year < 2019)]
leak.loc[leak.meter_reading < 0, 'meter_reading'] = 0 # remove negative values
leak = leak[leak.building_id != 245]
submission_list = [
"20191214-catboost-no-split-1-100-v2/2019-12-14_catboost-no_split_1-100_v2",
"aggregate-models-v5/weighted_blend_2019-12-14_gbm_split_primary_use",
"aggregate-models-v5/weighted_blend_2019-12-10_gbm_with_trend",
]
for i,f in enumerate(submission_list):
x = pd.read_csv(f'../input/{f}.csv', index_col=0).meter_reading
x[x < 0] = 0
test[f'pred{i}'] = x
del xリークデータを加工
leak = pd.merge(leak, test[['building_id', 'meter', 'timestamp', *[f"pred{i}" for i in range(len(submission_list))], 'row_id']], "left")
leak = pd.merge(leak, meta[['building_id', 'site_id']], 'left')リークデータの可視化
for i in range(len(submission_list)):
sns.distplot(np.log1p(leak[f"pred{i}"]))
sns.distplot(np.log1p(leak.meter_reading))
leak_score = np.sqrt(mean_squared_error(np.log1p(leak[f"pred{i}"]), np.log1p(leak.meter_reading)))
print(f'score{i}={leak_score}')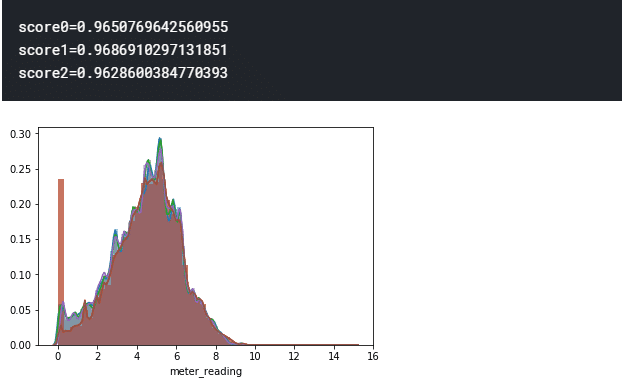
ブレンディングのリーク検証
# log1p then mean
log1p_then_mean = np.mean(np.log1p(leak[[f"pred{i}" for i in range(len(submission_list))]].values), axis=1)
leak_score = np.sqrt(mean_squared_error(log1p_then_mean, np.log1p(leak.meter_reading)))
print('log1p then mean score =', leak_score)![]()
![]()
# mean then log1p
mean_then_log1p = np.log1p(np.mean(leak[[f"pred{i}" for i in range(len(submission_list))]].values, axis=1))
leak_score = np.sqrt(mean_squared_error(mean_then_log1p, np.log1p(leak.meter_reading)))
print('mean then log1p score=', leak_score)![]()
![]()
Tune with Optuna
class GeneralizedMeanBlender():
"""Combines multiple predictions using generalized mean"""
def __init__(self, p_range=(-2,2)):
""""""
self.p_range = p_range
self.p = None
self.weights = None
def _objective(self, trial, X, y):
# create hyperparameters
p = trial.suggest_uniform(f"p", *self.p_range)
weights = [
trial.suggest_uniform(f"w{i}", 0, 1)
for i in range(X.shape[1])
]
# blend predictions
blend_preds, total_weight = 0, 0
if p <= 0:
for j,w in enumerate(weights):
blend_preds += w*np.log1p(X[:,j])
total_weight += w
blend_preds = np.expm1(blend_preds/total_weight)
else:
for j,w in enumerate(weights):
blend_preds += w*X[:,j]**p
total_weight += w
blend_preds = (blend_preds/total_weight)**(1/p)
# calculate mean squared error
return np.sqrt(mean_squared_error(y, blend_preds))
def fit(self, X, y, n_trials=10):
# optimize objective
obj = partial(self._objective, X=X, y=y)
study = optuna.create_study()
study.optimize(obj, n_trials=n_trials)
# extract best weights
if self.p is None:
self.p = [v for k,v in study.best_params.items() if "p" in k][0]
self.weights = np.array([v for k,v in study.best_params.items() if "w" in k])
self.weights /= self.weights.sum()
def transform(self, X):
assert self.weights is not None and self.p is not None,\
"Must call fit method before transform"
if self.p == 0:
return np.expm1(np.dot(np.log1p(X), self.weights))
else:
return np.dot(X**self.p, self.weights)**(1/self.p)
def fit_transform(self, X, y, **kwargs):
self.fit(X, y, **kwargs)
return self.transform(X)
X = np.log1p(leak[[f"pred{i}" for i in range(len(submission_list))]].values)
y = np.log1p(leak["meter_reading"].values)
gmb = GeneralizedMeanBlender()
gmb.fit(X, y, n_trials=20)
print(np.sqrt(mean_squared_error(gmb.transform(X), np.log1p(leak.meter_reading))))![]()
![]()
まとめ
全体のアンサンブル学習モデルのフローは下記になります。