
Stanford ML Groupは予測の不確かさを扱える新しい勾配ブースティング「NGBoost」を発表された。今回の記事はNGBoostを解説と実験したいです。
関連記事: 決定木分析、ランダムフォレスト、Xgboost、LightGBM
目次:
1. NGBoostとは
2. NGBoostの特徴
3. 実験・コード
__3.1 データ読み込み
__3.2 Xgboost、LightGBM、NGBoost
__3.3 モデル評価
__3.4 可視化
4. まとめ
1. NGBoostとは
勾配ブースティング(Gradient Boosting)は、いくつかの弱学習器(または基本学習器)が加法アンサンブルで結合されています。NGBoostアルゴリズムは、ブースティングを使用して条件付き確率分布のパラメーターを推定する、確率的予測のための教師あり学習方法です。
NGBoostの論文: NGBoost: Natural Gradient Boosting for Probabilistic Prediction
https://arxiv.org/abs/1910.03225
https://stanfordmlgroup.github.io/projects/ngboost/
アルゴリズムには3つの構成要素があります。
Base learner (f)
Parametric probability distribution (Pθ)
Proper scoring rule (S)

Base Learner
決定木などのアルゴリズム
Probability Distribution
出力する確率分布、正規分布、ラプラス分布などの分布設定
Scoring rule
MLE, CRPSなどのスコア関数
2. NGBoostの特徴
NGBoostの特徴は、確率分布のパラメーターを決定する問題として、自然勾配をキャストして勾配ブーストを実行することです。
通常の勾配は、マルチパラメーター確率分布(正規分布など)の学習には非常に不適切な場合があります。 自然な勾配を使用した学習ダイナミクスは、下記の確率回帰の例に見られるように、はるかに安定し、より良い適合をもたらす傾向があります。
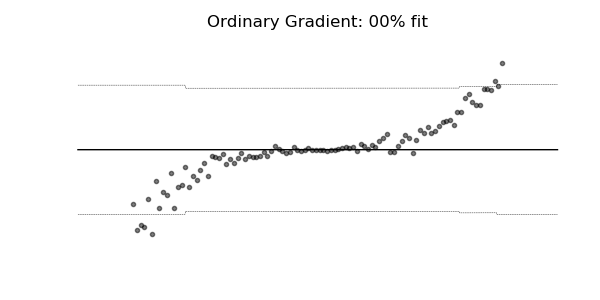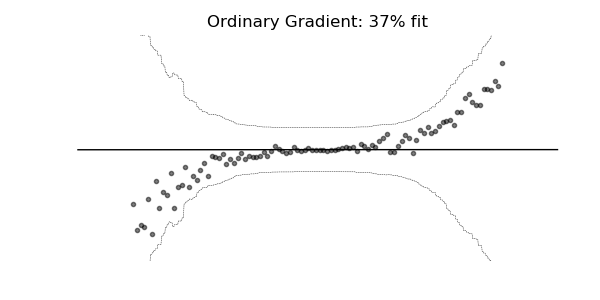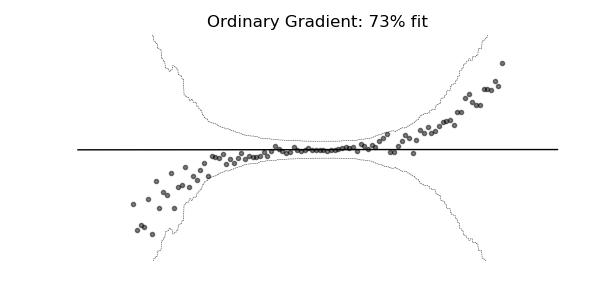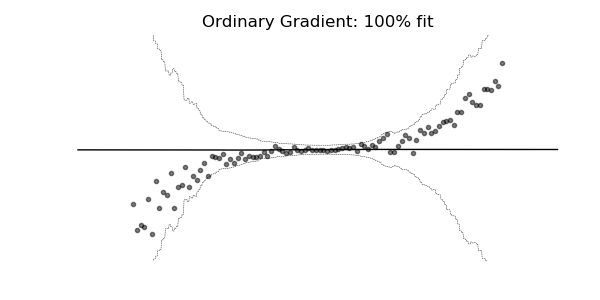
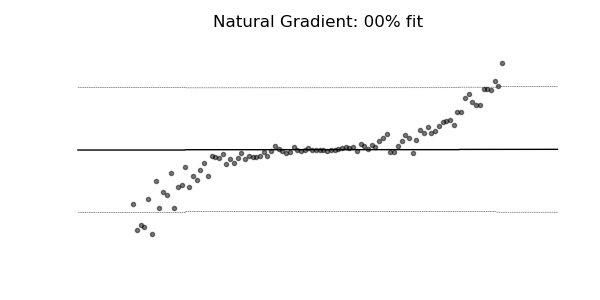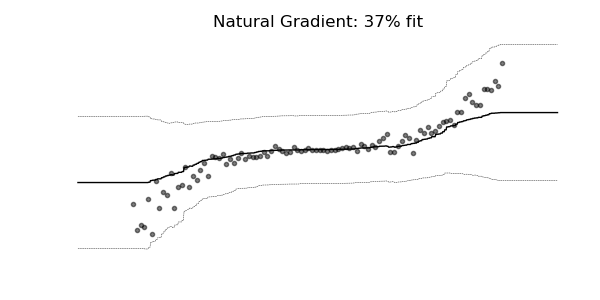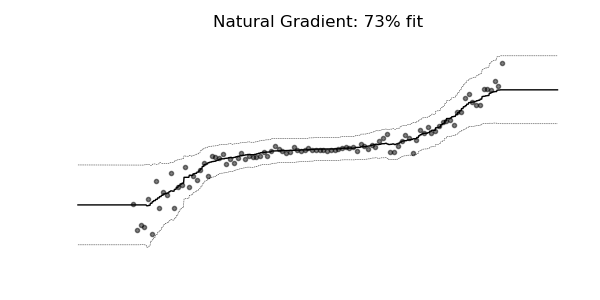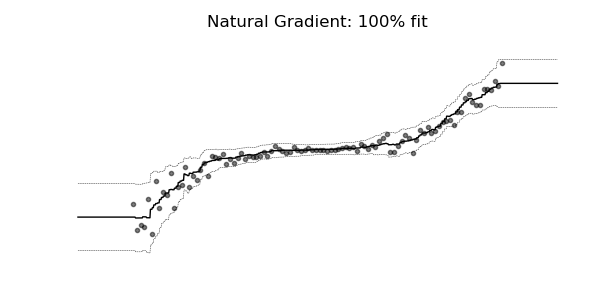
3. 実験・コード
データセット:scikit-learnの load_boston
モデル:Xgboost、LightGBM、NGBoost
モデル評価: RMSE(Root Mean Square Error)(二乗平均平方根誤差)
環境:Google Colab (CPU)
環境設定:
ライブラリのインストール
!pip install ngboost
ライブラリのインポート
# ライブラリのインポート import pandas as pd import numpy as np from tqdm import tqdm from datetime import datetime # データロード from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split # モデル from xgboost import XGBRegressor from lightgbm import LGBMRegressor from ngboost.ngboost import NGBoost from ngboost.learners import default_tree_learner from ngboost.scores import MLE from ngboost.distns import Normal, LogNormal # 検定 from sklearn.metrics import mean_squared_error from math import sqrt # 可視化 import matplotlib.pyplot as plt
3.1 データ読み込み
# サンプルデータの読み込み
seed = 20
result = {}
# サンプルデータロード
loaded_data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, test_size=0.2, random_state=seed)
print('X_train Shape:', X_train.shape)
print('y_train Shape:', y_train.shape)
print('X_test Shape:', X_test.shape)
print('y_test Shape:', y_test.shape)X_train Shape: (455, 30)
y_train Shape: (455,)
X_test Shape: (114, 30)
y_test Shape: (114,)
3.2 Xgboost、LightGBM、NGBoost
xgboost
# モデル作成
start_time = datetime.now()
xgb_rg = XGBRegressor(objective='reg:squarederror')
xgb_rg.fit(X_train, y_train)
# 推論
y_pred_xgb = pd.DataFrame(xgb_rg.predict(X_test))
# 検証
result[('1_xgboost', 'RMSE')] = round(sqrt(mean_squared_error(y_test,y_pred_xgb)),4)
result[('1_xgboost', 'Runtime')] = datetime.now() - start_timelightGBM
# モデル作成
start_time = datetime.now()
lgbm_rg = LGBMRegressor(eval_metric='rmse')
lgbm_rg.fit(X_train, y_train)
# 推論
y_pred_lgb = pd.DataFrame(lgbm_rg.predict(X_test))
# 検証
result[('2_lightGBM', 'RMSE')] = round(sqrt(mean_squared_error(y_test,y_pred_lgb)),4)
result[('2_lightGBM', 'Runtime')] = datetime.now() - start_timeNGBoost
# モデル作成
start_time = datetime.now()
ngb_rg = NGBoost(Base=default_tree_learner, Dist=Normal, natural_gradient=True, verbose=False)
ngb_rg.fit(X_train, y_train, X_val=X_test, Y_val=y_test)
# 推論
y_pred_ngb = pd.DataFrame(ngb_rg.predict(X_test))
y_dists = ngb_rg.pred_dist(X_test)
# 検証
result[('3_NGBoost', 'RMSE')] = round(sqrt(mean_squared_error(y_test,y_pred_ngb)),4)
result[('3_NGBoost', 'Runtime')] = datetime.now() - start_time3.3 モデル評価
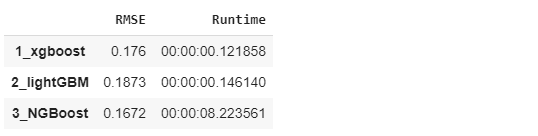
モデルのデフォルトのパラメータにしました。なのでどちらが性能がいいかはわかりませんが、NGBoostはよい結果になっています。
# モデル評価 result_df = pd.Series(result).unstack().reindex(columns=['RMSE', 'Runtime']) result_df
3.4 可視化
テストデータの分布とそれぞれのXgboost、LightGBM、NGBoostの予測値を可視化しました。テストデータが114件あるので、グラフは114個出力されます。モデルの予測結果は正規分布を利用しているので、平均を点推定していることがわかります。
# データ処理
offset = np.ptp(y_pred_ngb)*0.1
y_range = np.linspace(min(y_test)-offset, max(y_test)+offset, 200).reshape((-1, 1))
dist_values = y_dists.pdf(y_range).transpose()
y_pred_xgb_p = y_pred_xgb.values.tolist()
y_pred_lgb_p = y_pred_lgb.values.tolist()
y_pred_ngb_p = y_pred_ngb.values.tolist()
# グラフ作成
plt.figure(figsize=(15, 50))
for idx in tqdm(np.arange(X_test.shape[0])):
plt.subplot(30, 5, idx+1)
plt.plot(y_range, dist_values[idx])
plt.vlines(y_pred_ngb_p[idx], 0, max(dist_values[idx]), "r", label="ngb pred")
plt.vlines(y_pred_xgb_p[idx], 0, max(dist_values[idx]), "yellow", label="xgb pred")
plt.vlines(y_pred_lgb_p[idx], 0, max(dist_values[idx]), "purple", label="lgb pred")
plt.vlines(y_test[idx], 0, max(dist_values[idx]), "pink", label="ground truth")
plt.legend(loc="best")
plt.title(f"idx: {idx}")
plt.xlim(y_range[0], y_range[-1])
plt.tight_layout()
plt.show()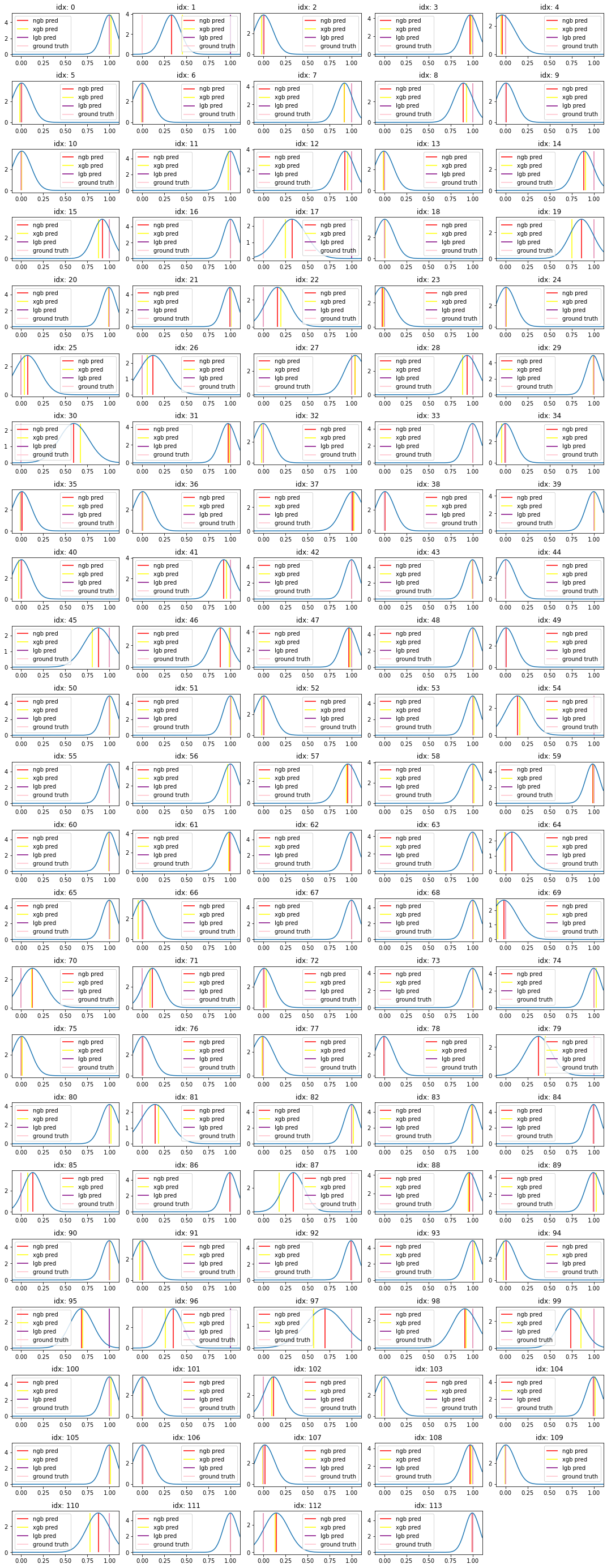
まとめ
今回はNGBoostのアルゴリズムを解説しました。実験はbostonのデータセットとデフォルトのパラメータにして、xgboost、lightGBM、NGBoostを実験しました。モデルのチュニックしなくて、NGBoostは一番低いエラーになります。ただ、NGBoostの実行時間はxgboostとlightGBMより遅いをわかりました。