
機械学習における「validation」は、一般的に「モデルの汎化性能の検証」を意味します。汎化性能とは「未知のデータに対する性能」のことです。今回はホールドアウト検証 (Hold-out Validation)と交差検証(Cross Validation)を解説します。
目次
1. ホールドアウト検証 (Hold-out Validation)
2. 交差検証 (Cross Validation)
3, train_test_split クラスAPI
4. cross_val_scoreクラスAPI
5. 実験・コード
__5.1 ホールドアウト検証
__5.2 交差検証
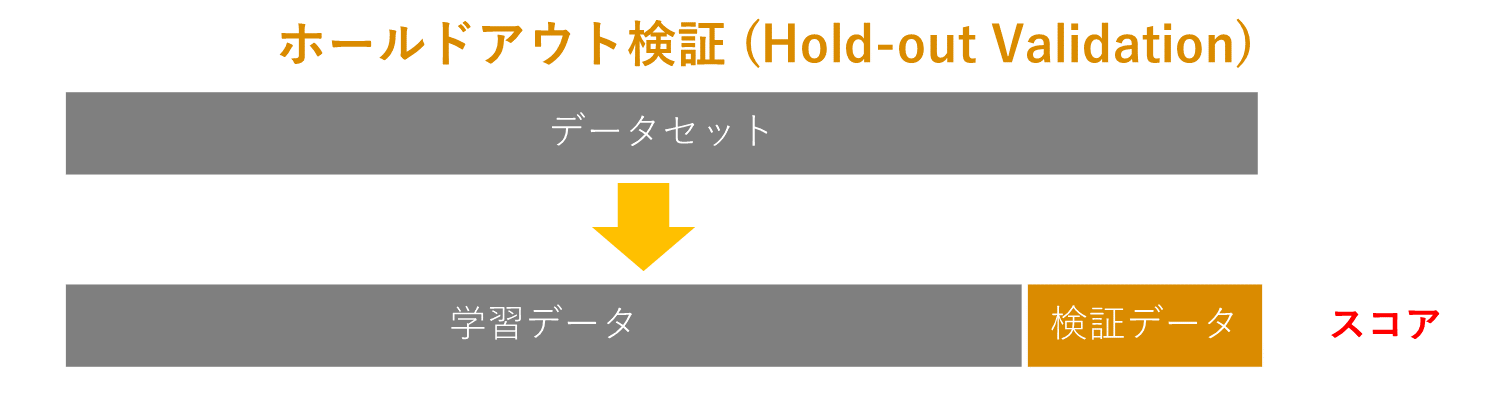
1. ホールドアウト検証 (Hold-out Validation)
ホールドアウト法は、モデルを作る学習データ (Train Data)と、モデルを評価するテストデータ(Test Data)に分割して評価します。モデルは未知のデータを予測しなければならないからです。学習データでテストしても、モデルの汎化能力は評価できません。下記のようなデータセットでスコアを計算します。
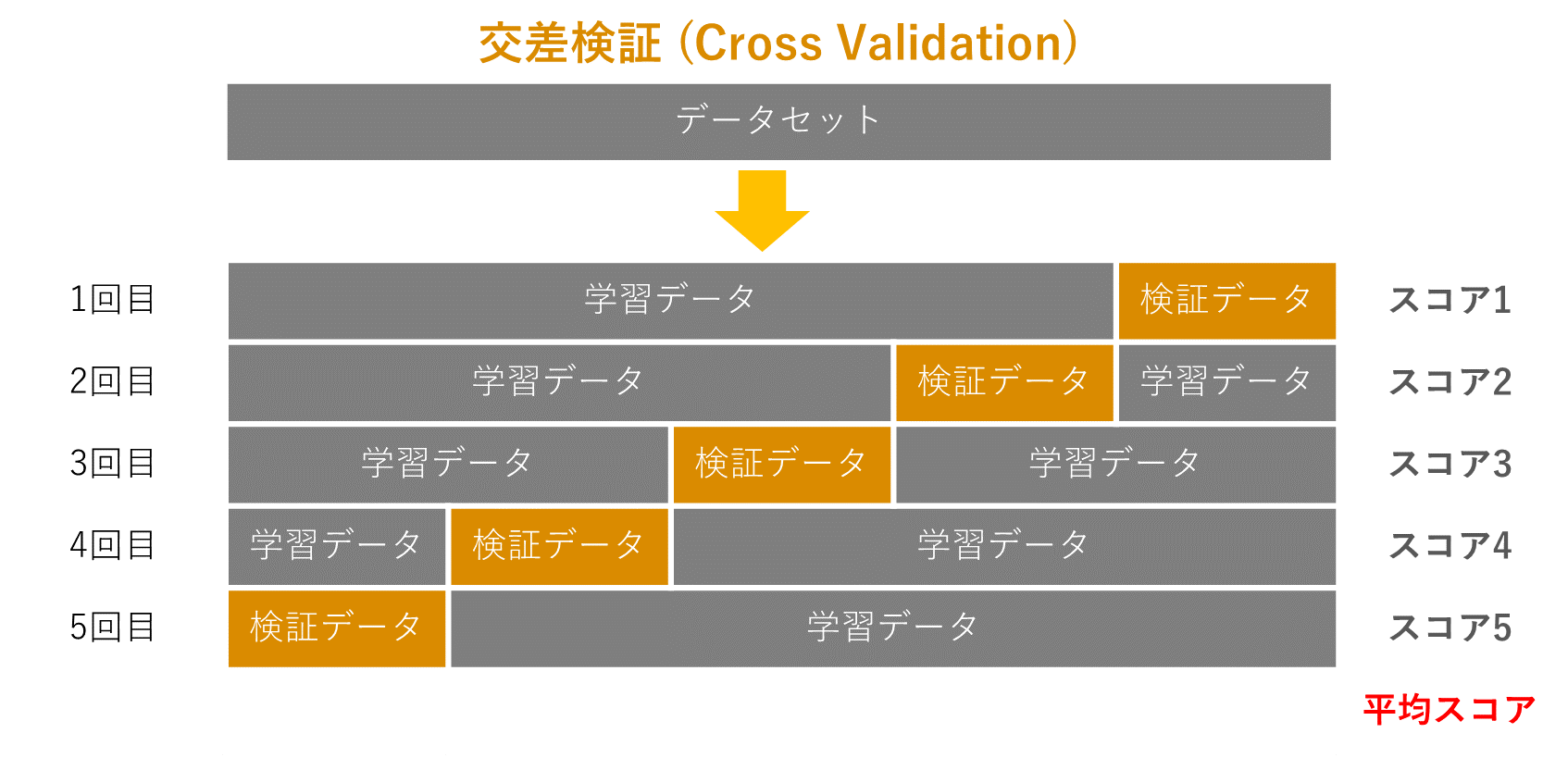
2. 交差検証 (Cross Validation)
交差検定では、用意したデータをK個に分割して、1回目はそのうちの一つをテストデータ、それ以外を学習データとして、学習・評価します。2回目は1回目と異なる別のデータをテストデータとして使い、3回目は1,2回目と異なるデータで評価をします。そして、各回で測定した精度の平均を取ります。下記のようなデータセットで平均スコアを計算します。
ホールドアウト検証の例よりも、更に汎用的に性能を確認できます。しかし、訓練とテストを K 回行うため、計算時間がかかります。
3, train_test_split クラスAPI
sklearn.model_selection.train_test_split(*arrays, **options)
引数
– X_train: 学習用の特徴行列
– X_test: テスト用の特徴行列
– y_train: 学習用の目的変数
– y_test: テスト用の目的変数
– test_size=: テスト用のデータを何割の大きさにするか test_size=0.2 で、2割をテスト用のデータとして置いておけます
– random_state=: データを分割する際の乱数のシード値
4. cross_val_scoreクラスAPI
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)
引数
– estimator: classifierの指定をします。
– X: 学習用のデータの指定
– y: テスト用のデータの指定
– groups : データセットをトレイン/テストセットに分割するときに使用されるサンプルのグループラベル。 「グループ」と組み合わせてのみ使用(GroupKFold)
– scoring: スコアのつけ方の指定。精度のaccuracyの他にもaverage_precisionやf1などがあります。詳細
– cv: データのsplitの方法を指定できます。デフォルトは3 fold
– n_jobs : 計算に使用するCPU数。 None は1CPU数。 -1は、すべてのプロセッサを使用すること。
– verbose: 0~3のいずれか。 詳細表示モード(0 = 表示なし,3 = 詳細)
5. 実験・コード
癌のデータのロジスティク回帰モデルを作成します。ホールドアウト検証と5Foldの交差検証を実験します。
5.1 ホールドアウト検証
#ライブラリのインポート
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
#scikit-learnより癌のデータを抽出する
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
#癌のデータを読み込む
X = pd.DataFrame(data=data.data, columns=data.feature_names)
y = pd.DataFrame(data=data.target)
#学習とテストを分ける
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=93)
#線形モデル(ロジスティク回帰)として測定器を作成する
from sklearn import linear_model
clf = linear_model.LogisticRegression()
model = clf.fit(X_train, y_train)
#スコア計算
print(f"スコア: {model.score(X_test, y_test)}")
スコア: 0.9824561403508771
5.2 交差検証
#ライブラリのインポート
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
#scikit-learnより癌のデータを抽出する
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
#癌のデータを読み込み
X = pd.DataFrame(data=data.data, columns=data.feature_names)
y = pd.DataFrame(data=data.target)
#線形モデル(ロジスティク回帰)として測定器を作成する
from sklearn import linear_model
clf = linear_model.LogisticRegression()
#Cross Validation
from sklearn.model_selection import cross_val_score
score = cross_val_score(clf, X, y, cv=5)
#正解率を出力する
print(f"スコア: {score}")
#平均値を出力する
print(f"平均値: {score.mean()}")
スコア: [0.93043478 0.93913043 0.97345133 0.95575221 0.96460177]
平均値: 0.9526741054251634