
目次
1. SPOCU活性化関数の概要
1.1 SPOCU活性化関数とは
1.2 SPOCU関数
2. 実験
2.1 ライブラリインポート
2.2 データ読み込み
2.3 データ加工
2.4 SPOCUの活性化関数を作成
2.5 Reluの活性化関数を作成
2.6 まとめ
関連記事:活性化関数のまとめ
1. SPOCU活性化関数の概要
1.1 SPOCU活性化関数とは
SPOCU活性化関数とは scaled polynomial constant unit activationの略称であり、物理学をベースとしているパーコレーションベースの活性化関数です。統計物理学と数学のパーコレーション理論は、スポンジのような媒質に水がしみこむ現象のモデルとして言われています。それ以外にも、パーコレーション理論とモンテカルロシミュレーションの組み合わせる事によって、ハードウェアのアモルファスシステムでのイオン移動と電子伝達をシュミレートできると言われています。
SPOCU活性化関数は、ウィスコンシン診断乳がん(WDBC)データセットや大規模データセットMNISTなど、大規模データセットと小規模データセットの両方でSPOCUの検証に成功しました。
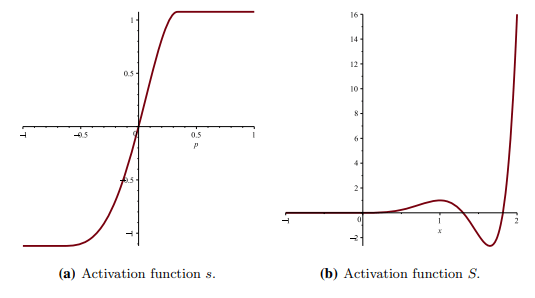
SPOCUの論文
https://link.springer.com/article/10.1007/s00521-020-05182-1
1.2 SPOCU関数
ライブラリのインストール
| python3 -m pip install spocu |
Tensorflow
| from spocu.spocu_tensorflow import SPOCU
alpha = 3.0937 beta = 0.6653 gamma = 4.437
spocu = SPOCU(alpha, beta, gamma) X = tf.Variable(tf.random.normal([10, 10], stddev=5, mean=4) ) |
Pytorch
| from spocu.spocu_pytorch import SPOCU
alpha = 3.0937 beta = 0.6653 gamma = 4.437
spocu = SPOCU(alpha, beta, gamma)
x = torch.rand((10,10)) |
ライブラリの詳細
https://pypi.org/project/spocu/
2. 実験
データセット:CIFAR-10 は、32×32 のカラー画像からなるデータセットで、その名の通り10クラスあります。全体画像数は60000件となり、そのうち50000件が訓練用データ、残り10000件がテスト用データに分けます。
モデル:SPOCUの活性化関数のモデル vs Reluの活性化関数のモデル
モデル評価:Accuracy
2.1 ライブラリインポート
ライブラリのインストール
| !python3 -m pip install spocu |
| import tensorflow as tf from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.2 データ読み込み
Tensorflowのデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
データを確認します。
| # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |

2.3 データ加工
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.4 SPOCUの活性化関数を作成
活性化関数を作成
| from spocu.spocu_tensorflow import SPOCU
alpha = 3.0937 beta = 0.6653 gamma = 4.437
spocu = SPOCU(alpha, beta, gamma)
X = tf.Variable(tf.random.normal([10, 10], stddev=5, mean=4) ) print(spocu(X)) |
tf.Tensor(
[[ 8.4149773e+01 1.9841893e+04 -1.5838286e+00 -1.3333118e+00
-2.9531121e-02 7.3747699e+02 1.0704442e+00 7.4381940e+02
8.1893950e+03 -1.6258037e-01]
…
[-1.5838286e+00 -8.1286488e+00 -1.5587455e+00 -1.4028144e+00
2.7075113e+02 1.8905088e+04 -1.5974003e+00 1.5053761e+02
-9.8039503e+00 -5.6544733e-01]], shape=(10, 10), dtype=float32)
活性化関数のモデルを作成
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=spocu, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=spocu)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 2304) 0
_________________________________________________________________
dense (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 49s 12ms/step – loss: 1.7538 – accuracy: 0.3802 – val_loss: 1.3060 – val_accuracy: 0.5435…
Epoch 50/50
500/500 [==============================] – 6s 11ms/step – loss: 0.4263 – accuracy: 0.8520 – val_loss: 1.3312 – val_accuracy: 0.6546
モデル評価
| # plotting the metrics
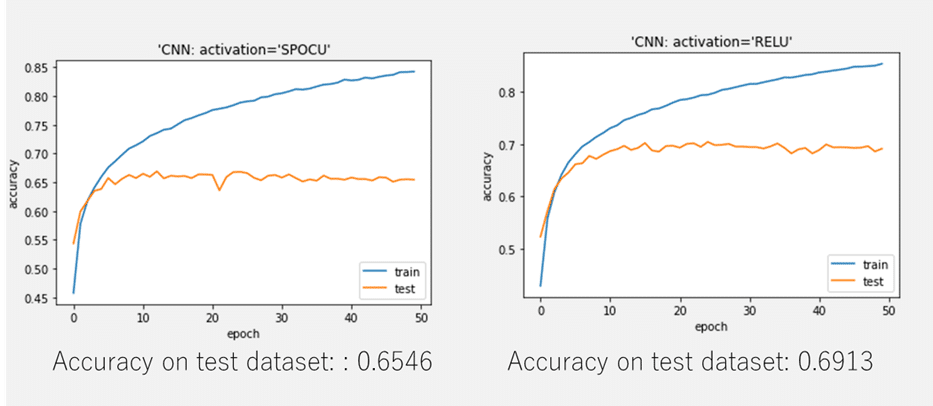
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: activation=’SPOCU'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
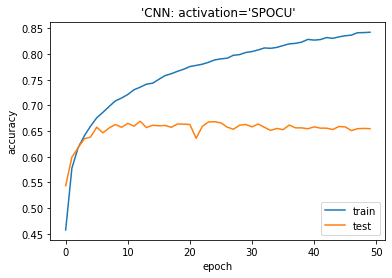
| from sklearn.metrics import accuracy_score
y_pred = model.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6546
2.5 Reluの活性化関数を作成
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model2 = Sequential() model2.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model2.add(MaxPool2D()) model2.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model2.add(MaxPool2D()) model2.add(Flatten()) model2.add(Dense(10, activation=’softmax’)) model2.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model2.summary()) |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルを学習します。
| model2.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
history2 = model2.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test))
|
Epoch 1/50
500/500 [==============================] – 3s 6ms/step – loss: 1.8103 – accuracy: 0.3455 – val_loss: 1.3376 – val_accuracy: 0.5236
…
Epoch 50/50
500/500 [==============================] – 3s 5ms/step – loss: 0.4076 – accuracy: 0.8583 – val_loss: 1.1002 – val_accuracy: 0.6913
| # plotting the metrics
plt.plot(history2.history[‘accuracy’]) plt.plot(history2.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘CNN: activation=’RELU'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
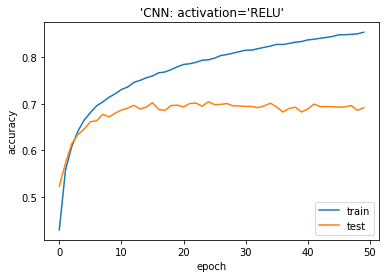
| from sklearn.metrics import accuracy_score
y_pred = model2.predict_classes(X_test) acc_score = accuracy_score(y_test, y_pred) print(‘Accuracy on test dataset:’, acc_score) |
Accuracy on test dataset: 0.6913
2.6 まとめ
CIFAR-10のデータセットで、SPOCUの活性化関数のモデル と RELUの活性化関数のモデルを作成しました。SPOCUとRELUの結果は同じくらいの結果でした。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト