
目次
1. SELU活性化関数の概要
1.1 SELU活性化関数とは
1.2 SELU定義
1.3 SELUの特徴
2. 実験
2.1 データロード
2.2 データ前処理
2.3 SELU活性化関数のモデル作成
2.4 RELU活性化関数のモデル作成
2.5 まとめ
記事:活性化関数のまとめ
1. SELU活性化関数の概要
1.1 SELU活性化関数とは
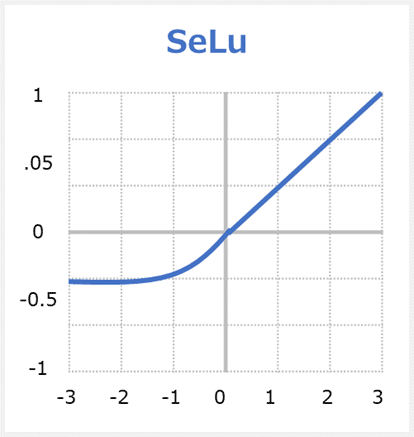
SELUはScaled Exponential Linear Unitsの英略称で、活性化関数の一つです。
SELUは勾配消失問題(Vanishing Gradient)を対応できます。何故ならばSELUは「0」を基点として、入力値が0以下なら「0」~「-λα」の間の値を、0より上なら「入力値をλ倍した値」を返します。ReLUおよびELUの拡張版です。
論文:https://arxiv.org/pdf/1706.02515.pdf
Tensorflow: https://www.tensorflow.org/api_docs/python/tf/nn/selu
PyTorch: https://pytorch.org/docs/stable/generated/torch.nn.SELU.html
1.2 SELU定義
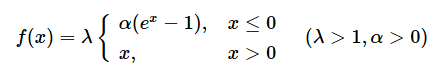
xが入力データで、f(x)が出力結果である。
x ≦ 0の場合は、f(x)=λ × α × (ex-1)となる
x > 0の場合は、f(x)=λ × xとなる。
1.3 SELUの特徴
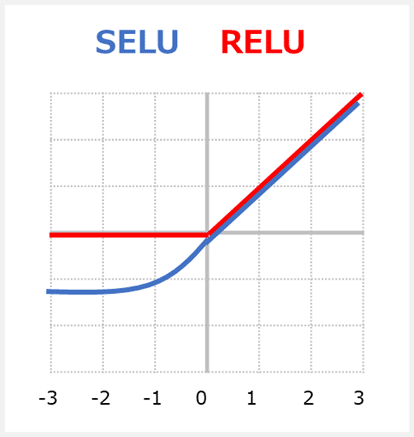
SELUはこの優れた自己正規化の品質を備えており、勾配消失を恐れる必要はありません。 今後、ReLUの代わりにSELUを使用する必要がある理由は3つあります。
1)ReLUと同様に、SELUは勾配消失に問題がないため、ディープニューラルネットワークを有効にします。
2)ReLUとは対照的に、Dying ReLUが起こりません(0以下での収束しない現象)。
3)SELUは、バッチ正規化と組み合わせた場合でも、他の活性化関数よりも速く、よりよく学習すると言われています。
2. 実験
データセット:cifar10: 60000枚の32ピクセルx32ピクセルの画像。10クラス([0] airplane (飛行機)、[1] automobile (自動車)、[2] bird (鳥)、[3] cat (猫)、[4] deer (鹿)、[5] dog (犬)、[6] frog (カエル)、[7] horse (馬)、[8] ship (船)、[9] truck (トラック))
モデル:CNN SELU活性化関数 vs CNN RELU活性化関数
ライブラリのインポート
| import tensorflow as tf from keras.datasets import cifar10 import matplotlib.pyplot as plt |
2.1 データロード
keras.datasetsからcifar10のデータセットを読み込みます。
| # Splite train and test data (X_train, y_train), (X_test, y_test) = cifar10.load_data()
# setting class names class_names=[‘airplane’, ‘automobile’ ,’bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’] |
サンプル画像データを表示します。
| # show sample image
def show_img (img_no): plt.imshow(X_train[img_no]) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.xlabel(“Label: ” + str(y_train[img_no][0])+ ” ” + class_names[y_train[img_no][0]]) plt.show()
show_img(1) |

2.2 データ前処理
データを正規化します。
| # Normalize X_train=X_train/255.0 X_test=X_test/255.0
print(‘X_train shape:’, X_train.shape) print(‘X_test shape:’, X_test.shape) |
X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
2.3 SELU活性化関数のモデル作成
SELU活性化関数のCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’selu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’selu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model.summary()) |
| model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) |
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルコンパイル
| model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) |
モデルを実行します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 3s 5ms/step – loss: 1.7464 – accuracy: 0.3737 – val_loss: 1.3841 – val_accuracy: 0.5074
…
Epoch 50/50
500/500 [==============================] – 2s 5ms/step – loss: 0.4617 – accuracy: 0.8407 – val_loss: 1.3470 – val_accuracy: 0.6424
モデル評価
| # plotting the metrics
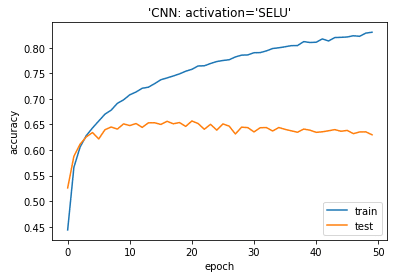
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘Dense: activation=’SELU'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
2.4 RELU活性化関数のモデル作成
RELU活性化関数のCNNモデルを作成します。
| from keras.models import Sequential from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation=’relu’, input_shape=(32, 32, 3))) model.add(MaxPool2D()) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation=’relu’)) model.add(MaxPool2D()) model.add(Flatten()) model.add(Dense(10, activation=’softmax’)) model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’]) print(model.summary()) |
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 2304) 0
_________________________________________________________________
dense (Dense) (None, 10) 23050
=================================================================
Total params: 42,442
Trainable params: 42,442
Non-trainable params: 0
_________________________________________________________________
None
モデルコンパイル
| model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) |
モデルを実行します。
| history = model.fit(X_train, y_train, batch_size=100, epochs=50, verbose=1, validation_data=(X_test, y_test)) |
Epoch 1/50
500/500 [==============================] – 10s 5ms/step – loss: 1.8073 – accuracy: 0.3477 – val_loss: 1.3547 – val_accuracy: 0.5239
…
Epoch 50/50
500/500 [==============================] – 2s 4ms/step – loss: 0.4513 – accuracy: 0.8425 – val_loss: 1.0626 – val_accuracy: 0.6962
モデル評価
| # plotting the metrics
plt.plot(history.history[‘accuracy’]) plt.plot(history.history[‘val_accuracy’]) plt.title(‘model accuracy’) plt.ylabel(‘accuracy’) plt.xlabel(‘epoch’) plt.title(“‘Dense: activation=’RELU'”) plt.legend([‘train’, ‘test’], loc=’lower right’) plt.show() |
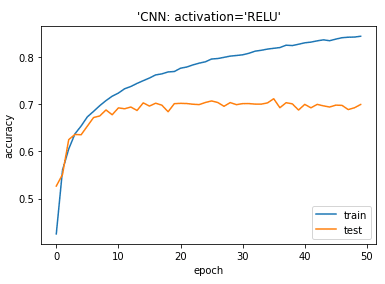
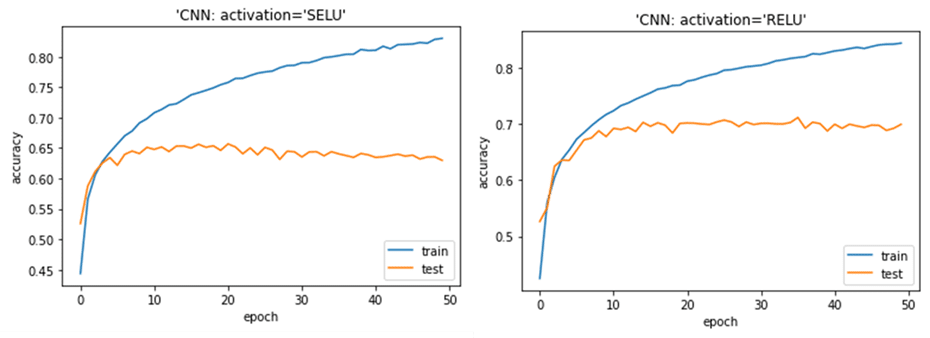
2.5 まとめ
cifar10データセットでSELU活性化関数のCNNモデルとRELU活性化関数のCNNモデルを作成しました。どちらもよいモデルができましたが、SELUの方が過学習の結果になりました。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト