
目次
1. 解析手法の概要
2. 1位のパイプライン
3. データセット作成
4. モデル作成
5. モデル評価
1. 解析手法の概要
この記事は、kaggle1位の解析手法:Help Protect the Great Barrier Reef 【2版】のシリーズの第2番です。第1番は下記はリングです。
kaggle1位の解析手法:Help Protect the Great Barrier Reef 【1 第2版】
1位~5位の解析手法は下記のパスです。
1st Place Solution Trust CV
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/307878
2nd Solution – YOLOv5
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/307760
3rd place solution – Team Hydrogen
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/307707
4th Place Solution – CenterNet
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/307626
5th place solution, poisson blending,detection and tracking
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/308007
2. 1位のパイプライン
1位のパイプラインはデータ加工、物体検出のモデルと分類スコア、後処理、モデル評価の流れにしました。
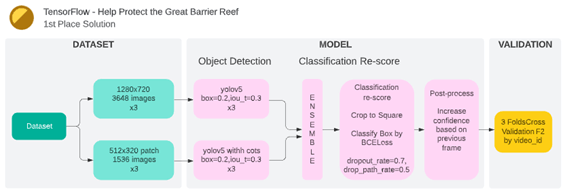
3. データセット作成
二つのデータセット作成パイプラインがあります。
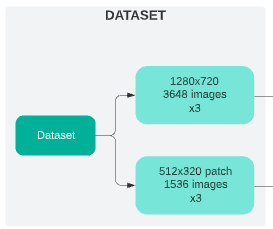
- 3つの1280 x 720の3648枚の画像データセット
- 3つの512 x 320 パッチの1536枚の画像データセット
画像パッチ:元の画像(1280×720)を複数の(512×320)画像にしました
4. モデル作成
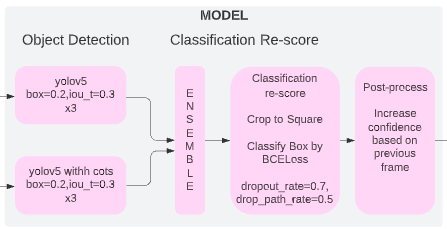
4.1 物体検出のモデル
物体検出のモデル
– 6つのyolov5モデル、3つは3648イメージでトレーニング済み、3つは1536イメージパッチでトレーニングします。
– 画像パッチが境界近くのボックスを削除してから、それらのパッチでベビーベッドを使用してyolov5のみをトレーニングします。
– デフォルトのbox=0.2、iou_t=0.3に基づいていくつかのyoloハイパーパラメータを変更しました。
– Data Augmentation:yolov5のデフォルトの拡張に基づいて、回転、ミックスアップ、albumentationsを追加しました。転置してからHSVを削除しました。
Data Augmentationの解説:KerasでのData Augmentationの解説
– これらの6つのyolov5モデルをアンサンブルすると、CV0.716が得られました。
4.2 分類スコア
– 予測されたすべてのボックス(3倍のOOF)を、conf>0.01で正方形に切り取ります。 正方形の辺の長さは、予測されたボックスのmax(length、width)であり、その後20%拡大しました。
– この画像の各予測ボックスとGTボックスのiou値の最大値としてiouを計算します。
– 各クロップドボックスの分類ターゲット:iou> 0.3、iou> 0.4、iou> 0.5、iou> 0.6、iou> 0.7、iou> 0.8、およびiou> 0.9簡単に言えば、iouは7つのビンに分割されます。 例:[1,1,1,0,0,0,0]は、iouが0.5〜0.6であることを示します。
– 推論中、分類スコアとして7つのビン出力を平均します。
– 次に、BCELossを使用して、これらのトリミングされたボックスを256×256または224×224のサイズでトレーニングします。
– 非常に高いdropout_rateまたはdrop_path_rateは、分類モデルのパフォーマンスを向上させるのに大いに役立ちます。 dropout_rate=0.7およびdrop_path_rate=0.5を使用します。
– 拡張:hflip、vflip、transpose、45°回転およびカットアウト。
– 最良の分類モデルはCVを0.727に上げることができます。
– いくつかの分類モデルをアンサンブルした後、CVは0.73+になります。
4.3 後処理
– 最後に、単純な後処理を使用して、CVを0.74+にさらに高めます。
– たとえば、モデルは#NフレームでいくつかのボックスBを予測し、信頼性の高いBからボックスを選択します。これらのボックスは、「アテンションエリア」としてマークされます。
– #N + 1、#N + 2、#N + 3フレームで、conf> 0.01の予測ボックスの場合、「アテンションエリア」が0より大きいIoUがある場合は、これらのボックスのスコアをスコアでブーストします。
score += confidence * IOU
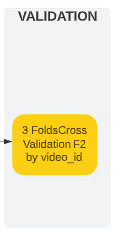
5. モデル評価
video_id別の3分割交差検定をおこないました。
F2 = 0.74+ by 3-fold cross validation (video_id split)

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト