
目次
1. Affinity-lossとは
2. 使い方
1 Affinity-lossとは
Affinity-lossは、単一の定式化で分類とクラスタリングを共同で実行するハイブリッド損失関数です。この手法は、ユークリッド空間の「親和性測定」に基づいて、次の利点があります。
(1) 分類境界に対する最大マージン制約の直接施行
(2) 等間隔で等距離のクラスター中心を確保するための扱いやすい方法
(3) 特徴空間での多様性と識別可能性をサポートするために、複数のクラス プロトタイプを学習する柔軟性。
論文:https://arxiv.org/pdf/1901.07711.pdf
Affinity Loss は、分類とクラスタリングを 同時におこなうことができます。 ユークリッド空間での柔軟な定式化により、クラス間のマージンの適用、学習したクラスターの制御、クラス プロトタイプの数、およびクラス間の距離が可能になります。
MNIST データ (数字 0 ~ 4 のサンプルの 10% のみを保持することによって) でトレーニングされます。
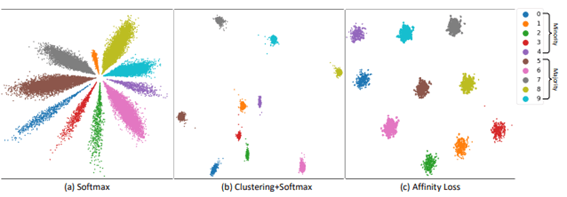
(a) ソフトマックス損失は、角度空間で花びらを学習します。少数派クラスの特徴ベクトルは弱く (長さが短く)、占める角度空間が少ないことに注意してください。
(b) センターロスは、クラスタリングを実行することにより、クラス内変動を低減します。 ただし、マイノリティ クラスのベクトルは中心付近に密集する傾向があり、互いに混同されます。
(c) 提案されたアフィニティ損失は、多数派クラスと少数派クラスの両方について、均一な形状の等間隔クラスターを学習します。
2. 使い方
koshian2のgithubはサンプルコードを共有致します。
https://github.com/koshian2/affinity-loss
Clustering Affinityのレイヤー
| from affinity_loss import * x = ClusteringAffinity(10, 1, 10.0)(some_input) # n_classes, n_centroids, sigma |
モデルのコンパイル
| model.compile(“adam”, affinity_loss(0.75), [acc]) |
実行の結果
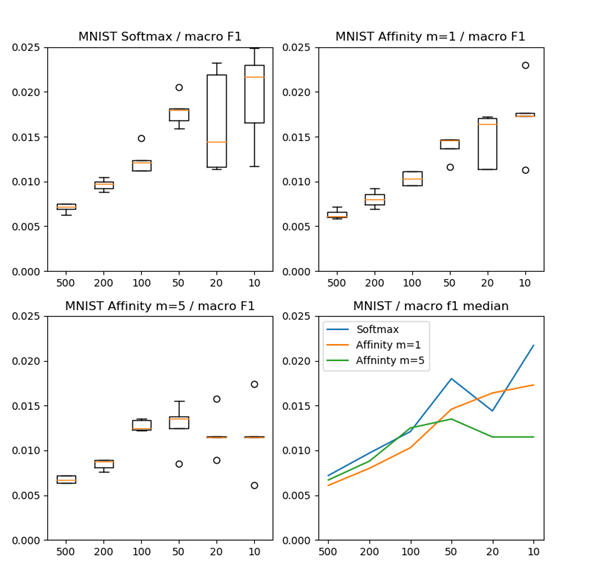
MNISTの手書き数字6万サンプルです。
MNIST, lambda=0.75, sigma=10. Evaluate on macro f1-score.
| # samples per class on test data | Softmax | Affinity m=1 | Affinity m=5 |
| 500 | 99.28% | 99.39% | 99.33% |
| 200 | 99.03% | 99.20% | 99.12% |
| 100 | 98.79% | 98.97% | 98.75% |
| 50 | 98.20% | 98.54% | 98.65% |
| 20 | 98.56% | 98.36% | 98.85% |
| 10 | 97.83% | 98.27% | 98.85% |

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト