
目次
1. ThymeBoostとは
2. ThymeBoostの実験
2.1 環境構築
2.2 データ生成
2.3 モデル学習
2.4 結果の確認
2.5 可視化
1. ThymeBoostとは
ThymeBoost は、時系列分解と勾配ブースティングを組み合わせて、予測のための柔軟な組み合わせ時系列フレームワークです。 時系列をトレンド成分、季節成分、変化点、外れ値に分解できます。
下記のような手順です。
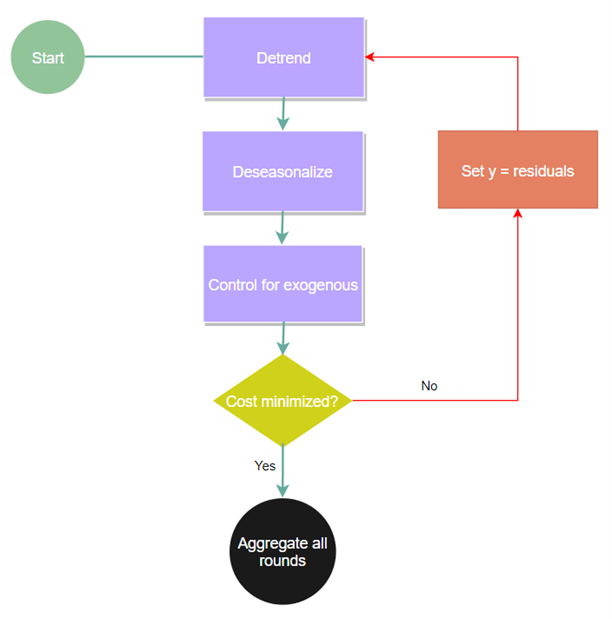
ThymeBoostのパラメータ
verbose: bool, オプション 情報を表示する設定
n_split_proposals : int、オプション 変更点に対して提案する分割の数。
approximate_splits:bool、 オプション Trueに設定する場合は、変化点を検出します。
exclude_splits : リスト、オプション 変更点を検索するときに除外するインデックスのリスト。
given_splits : リスト、オプション 変化点を検索するときに使用するインデックスのリスト。
cost_penalty : float、オプション 各ブースト ラウンドで適用されるペナルティ。 これにより、ブースターが非常に多くの小さな改善を行うのを防ぎます。(デフォルト= .001)
normalize_seasonality : bool、オプション マルチに対して季節平均を強制的に 0 または 1 にするかどうか。(デフォルト=True)
additive: bool、オプション プロセス全体が加法的か乗法的か。
regularization: float、オプション 各ブースティング ラウンドでグローバル コストにさらにペナルティを課すパラメータ。
n_rounds : int、オプション 終了までの設定された回数のブースト ラウンド。
smoothed_trend: bool、オプション トレンド コンポーネントになだめるようなものを適用するかどうか。
scale_type : 文字列、オプション 適用するスケーリングのタイプ。 オプションは [‘standard’, ‘log’] で、従来の標準化またはログを取得します。
trend_estimator : str、オプション [‘mean’, ‘median’, ‘linear’, ‘ransac’] の選択肢。(デフォルト=ransac)
fit_type : str、オプション グローバル フィッティングとローカル フィッティングのどちらを使用するか。 オプションは [‘local’, ‘global’] です。 (デフォルト=local)
season_estimator : str、オプション 季節成分を近似する方法。 (デフォルト=fourier)
season_period : int、オプション 季節的な頻度。 (デフォルト=None)
2. ThymeBoostの実験
環境: Google Colab
データセット: 生成した時系列データ
2.1 環境構築
ライブラリのインポート
| !pip install -q ThymeBoost |
ライブラリのインポート
| import numpy as np import matplotlib.pyplot as plt import seaborn as sns sns.set_style(“darkgrid”) from ThymeBoost import ThymeBoost as tb |
2.2 データ生成
トレンド、季節性、ノイズ、変化点、変動で時系列データを作成します。
| seasonality = ((np.cos(np.arange(1, 101))*10 + 50)) np.random.seed(100) true = np.linspace(-1, 1, 100) noise = np.random.normal(0, 3, 100) y = true + noise + seasonality
# Change point true = np.linspace(1, 50, 100) noise = np.random.normal(0, 1, 100) y = np.append(y, true + noise + seasonality)
# shift true = np.linspace(1, 20, 100) + 100 noise = np.random.normal(0, 1, 100) y = np.append(y, true + noise + seasonality)
plt.plot(y) plt.show() |

2.3 モデル学習
ThymeBoostのモデルを学習します。
| boosted_model = tb.ThymeBoost( approximate_splits=True, verbose=0, cost_penalty=.001, )
output = boosted_model.optimize(y, lag=10, optimization_steps=1, trend_estimator=[‘mean’, boosted_model.combine([‘ses’, ‘des’, ‘damped_des’])], seasonal_period=[0, 25], fit_type=[‘global’])
predicted_output = boosted_model.predict(output, 100) |
2.4 結果の確認
| output |
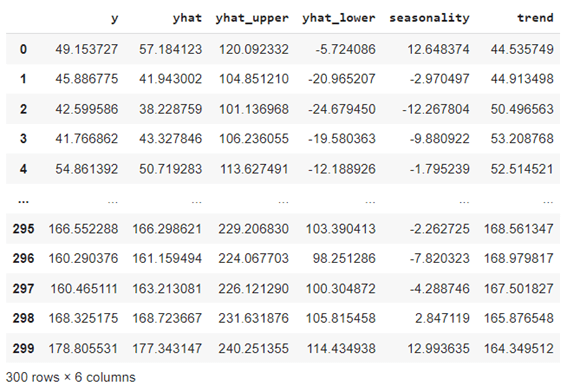
予測結果
トレンド成分、季節成分、変化点、外れ値など値を出力します。
| predicted_output |
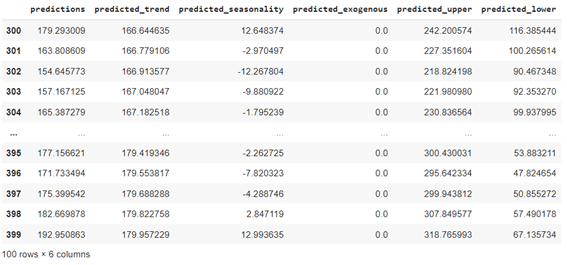
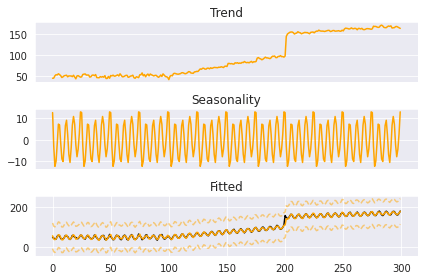
2.5 可視化
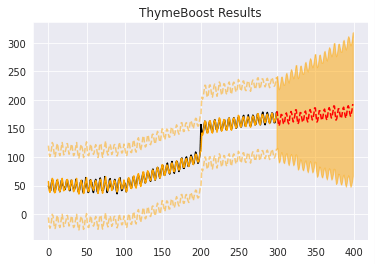
実績値と予測値を表示します。
| boosted_model.plot_results(output, predicted_output) |
トレンド成分、季節成分、変化点、など値を表示します。
| boosted_model.plot_components(output) |

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属