
目次
1.距離ベース(Distance-based)
2.間隔ベース(Interval-based)
3.辞書ベース(Dictionary-based)
4.頻度ベース(Frequency-based)
5.シェイプレットベース(Shapelet-based)
6.ハイブリッド(Hybrid)
一般的な分類アルゴリズムはデータの時間順序に含まれる情報を無視します。時系列分類アルゴリズムは、時系列分類の問題に対して表形式の分類器よりもパフォーマンスが優れている傾向があります。
sktimeには、時系列分類のための多くのアルゴリズムがあります。この記事は時系列分類アルゴリズムの5つのカテゴリを紹介します。
1.距離ベース(Distance-based )
これらの分類アルゴリズムは、距離メトリックを使用して分類します。
K-Nearest Neighbors (Dynamic Time Warping)
代表的なk最近傍(KNN)アルゴリズムは、ユークリッド距離メトリック(Euclidean distance) をdynamic time warping(DTW)メトリックに置き換えることにより、時系列に適合させることができます。DTWは、時間、速度、または長さが正確に一致しない可能性がある2つのシーケンス間の類似性を測定します。
メリット
KNN+DTWは、シンプルでよい結果であり、ハイパーパラメータ調整を必要がありません。ベンチマークのベースアルゴリズムとしてよく利用します。
デメリット
KNN+DTWは、計算に多くのスペースと時間を必要とします。
シリーズが特定のクラスに割り当てられた理由に関する限られた情報を提供します。
ノイズの多いデータはパフォーマンスが低下する可能性があります。
DTW(Dynamic Time Warping)動的時間伸縮法の記事
2.間隔ベース(Interval-based )
時系列フォレスト分類(Time Series Forest Classifier)
時系列フォレスト(TSF)分類は、ランダムフォレスト分類器をシリーズデータに適合させます。下記のような計算を行います。
- ランダムな開始位置とランダムな長さで、シリーズをランダムな間隔に分割します。
- 各区間から特徴量(平均、標準偏差、および勾配)を抽出します。
- 抽出された特徴量で決定木を学習します。
- 必要な数のツリーが構築し、学習時間が終わるまで、手順1〜3を繰り返します。
新しいデータは、モデルのすべての木の過半数の投票に従って分類されます。
メリット
実験的研究により、時系列フォレストは、動的なタイムワーピングを伴う最近傍などのベースラインよりも優れていることが示されています
時系列フォレストも計算効率が高いです。
時系列フォレストは解釈可能なモデルです。
サンプルコード:
3.辞書ベース(Dictionary-based )
辞書ベースの分類子は、最初に実数値の時系列を一連の離散的な「単語」に変換します。 分類は、抽出された単語の特徴量を分類します。
辞書分類子はすべて同じコアプロセスを使用します。長さwのスライディングウィンドウがシリーズ全体で実行されます。 ウィンドウごとに、一連の数値は長さlの「単語」に変換されます。 この単語はαの可能な文字で構成されています。
ボス(BOSS:Bag of SFA Symbols )
BOSS分類器の単語の特徴は、Symbolic Fourier Approximation(SFA)変換を使用してシリーズから抽出されます。下記のような計算します。
- ウィンドウのフーリエ変換を計算します(正規化が発生した場合、最初の項は無視されます)
- Multiple Coefficient Binning(MCB)を使用して、最初のl個のフーリエ項をシンボルに離散化し、「単語」を形成します。 MCBは、連続する時系列を文字のシーケンスにビン化する教師ありアルゴリズムです。
- これらの単語の辞書は、ウィンドウがスライドするときに作成され、各単語の頻度のカウントを記録します。 同じ単語が2つ以上の連続するウィンドウで生成された場合、その単語は1回だけカウントされます。 スライディングウィンドウが完了すると、シリーズは辞書に基づいてヒストグラムに変換されます。
- 最後に、シリーズから抽出された単語ヒストグラムで任意の分類器をトレーニングできます。
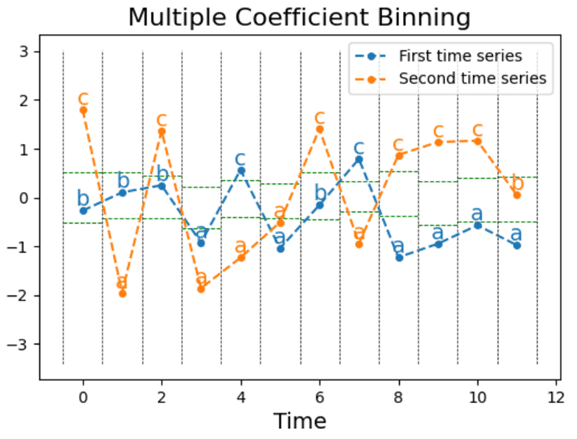
ボスアンサンブル(BOSS Ensemble)
ボスアンサンブルは、前述のBOSS分類器のアンサンブルです。 BOSSアンサンブルは、個々のBOSS分類器のパラメーター(l、α、w、およびp)全体でグリッド検索を実行します。 (pは、サブシリーズが正規化されるかどうかを制御します。)アンサンブルは、精度が最良の分類器の92%以内の精度を持つメンバーのみを保持します。
メリット
ボスアンサンブルは、いくつかの論文で最も正確な辞書ベースの分類アルゴリズムでした。
デメリット
事前定義された大きなパラメータ空間を検索するため、BOSSは時間のオーバーヘッドを伴い、メモリ使用量が不安定になるリスクがあります。
可縮ボス(cBOSS:Contractable BOSS)
cBOSSは、BOSSのようにパラメーター空間全体にわたってグリッド検索を実行する代わりに、置換せずにパラメーター空間からランダムにサンプリングします。 次に、cBOSSは各基本分類子のデータをサブサンプリングします。
メリット
cBOSSは、特定のパフォーマンスしきい値を超えるすべての分類子を保持するのではなく、固定数の基本分類子を保持することにより、BOSSのメモリ要件を改善します。 最後に、cBOSSは、トレインの精度に応じて、各基本分類器の寄与を指数関数的に重み付けします。
4.頻度ベース(Frequency-based)
頻度ベースの分類器は、系列から抽出された頻度データに依存しています。
ランダム区間スペクトルアンサンブル(RISE:Random Interval Spectral Ensemble)
RISEは、2つの点で時系列フォレストとは異なります。 まず、ツリーごとに1つの時系列間隔を使用します。 次に、要約統計量の代わりに、シリーズから抽出されたスペクトル特徴を使用してトレーニングされます。
RISEは、次のようないくつかのシリーズ間特徴抽出トランスフォーマーを使用します。
・適合した自己回帰係数(Fitted auto-regressive coefficients)
・推定された自己相関係数(Estimated autocorrelation coefficients)
・パワースペクトル係数(Power spectrum coefficients)
RISEは、次のような学習を行います。
- 系列のランダムな間隔を選択します(長さは2の累乗です)。(最初のツリーには、シリーズ全体を使用します)
- 各シリーズの同じ間隔で、シリーズ間特徴抽出トランスフォーマー(自己回帰係数、自己相関係数、およびパワースペクトル係数)を適用します。
- 抽出された特徴を連結して、新しいトレーニングセットを形成します
- 決定木分類器をトレーニングする
- アンサンブル1–4
クラス確率は、基本分類子の投票の割合として計算されます。
メリット
RISEは、単一のツリーを構築する時間の適応モデルを作成しまから、非常に大きな間隔が非常に少ないツリーを意味する可能性がある長いシリーズ(オーディオなど)が適当にします。
5.シェイプレットベース(Shapelet-based )
シェイプレットは、クラスを表すサブシーケンス、または時系列の小さなサブシェイプです。 これらは、「同じクラス内のシリーズ間の位相に依存しない局所的な類似性」を検出するために使用できます。
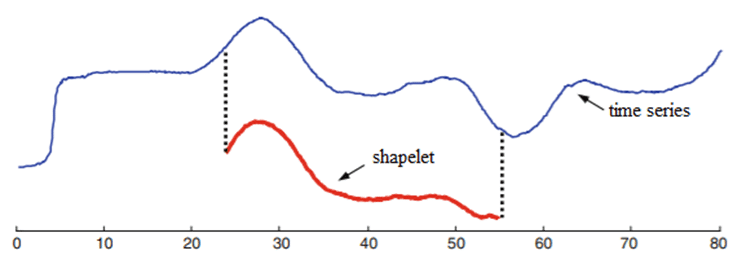
一つのシェイプレットは、時系列の間隔です。 任意のシリーズの間隔を列挙できます。 たとえば、[1,2,3,4]には、[1,2]、[2,3]、[3,4]、[1,2,3]、[2,3,4]の5つの間隔があります。シェイプレットベースの分類器は、識別力のあるシェイプレットを検索します。
シェイプレット変換分類(Shapelet Transform Classifier)
次のような学習を行います。
- アルゴリズムは最初にデータセットの上位k個のシェイプレットを識別します。
- 新しいデータセットのk個の特徴が計算されます。 各フィーチャは、k個のシェイプレットのそれぞれまでのシリーズの距離として計算され、シェイプレットごとに1つの列があります。
- 最後に、任意のベクトルベースの分類アルゴリズムをシェイプレット変換されたデータセットに適用できます。
シェイプレットはランダムに検索します。 考慮される各シェイプレットは、情報ゲインに従って評価されます。 最強の重複しないシェイプレットが保持されます。
サンプルコード:
https://github.com/alan-turing-institute/sktime
アンサンブル分類(Ensemble Classifiers)
6.ハイブリッド(Hybrid)
ハイブコート(HIVE-COTE)
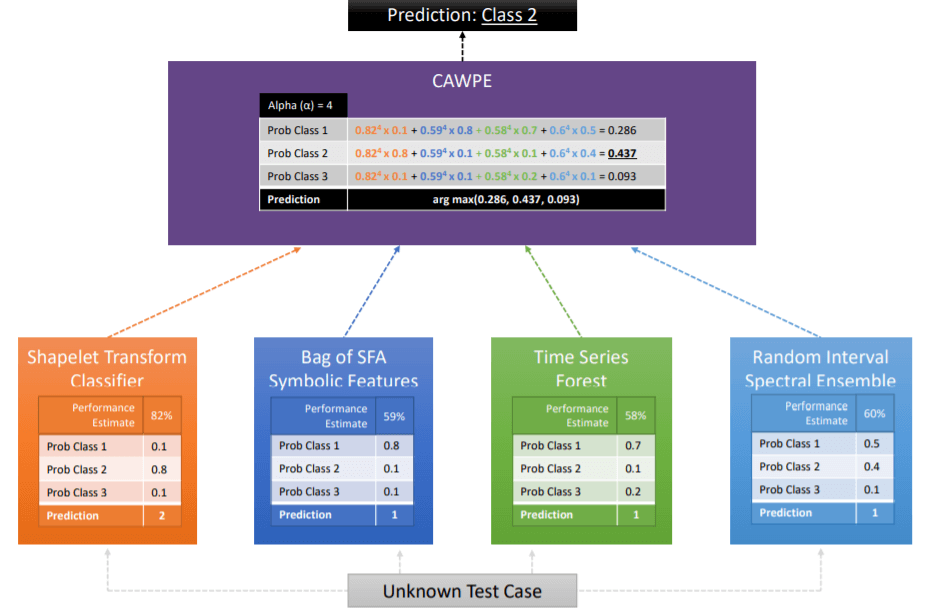
変換ベースのアンサンブルの階層的投票集合(HIVE-COTE)は、前述の分類子に基づいて構築されたメタアンサンブルです。
HIVE-COTE予測は、そのメンバー(シェイプレット変換分類子、BOSS、時系列フォレスト、およびRISE)によって生成された予測の加重平均です。
各サブ分類器は、各クラスの確率を推定します。次に、コントロールユニットはこれらの確率(CAPWE)を組み合わせます。重みは、トレーニングデータで見つかった分類器の相対的な推定品質として割り当てられます。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト