![]()
![]()
![]()
![]()
目次
1. 階層的クラスタリングの概要
__1.1階層的クラスタリング (hierarchical clustering)とは
__1.2所と短所
__1.3 凝集クラスタリングの作成手順
__1.4 sklearn のAgglomerativeClustering
__1.5 距離メトリック (Affinity)
__1.6 距離の計算(linkage)
2. 実験・コード
__2.1 環境の準備
__2.2 データロード
__2.3 Euclidean距離のモデル学習・可視化
__2.4 Manhattan距離のモデル学習・可視化
__2.5 Cosine距離のモデル学習・可視化
1.1 階層的クラスタリング (hierarchical clustering)とは
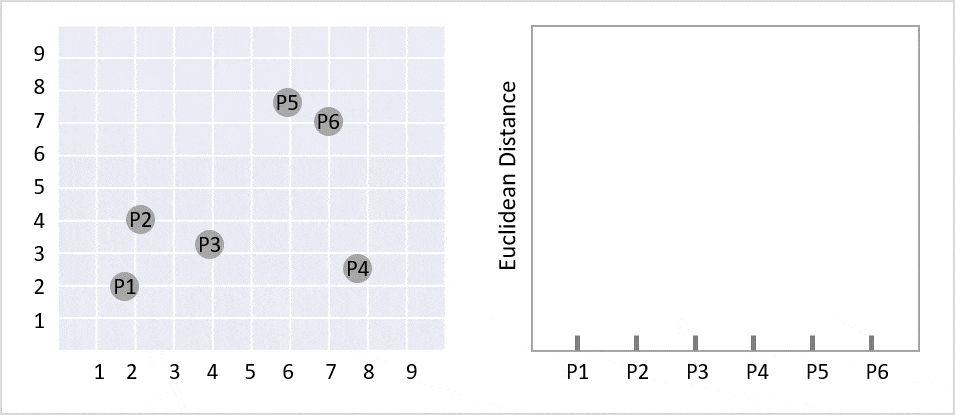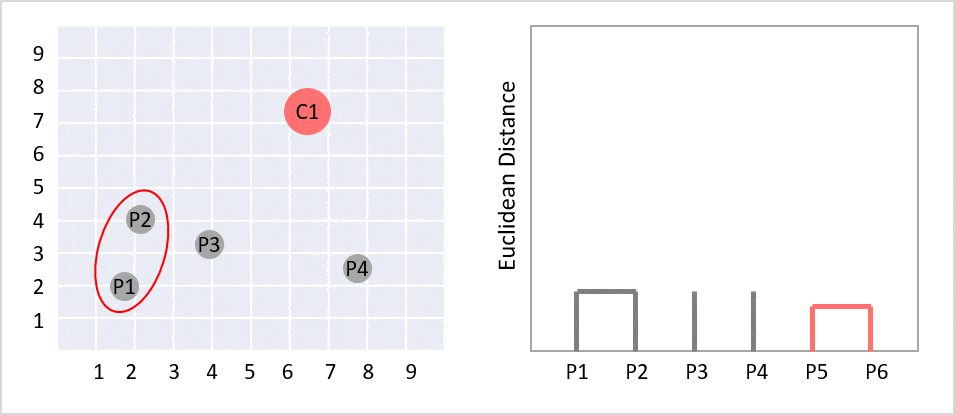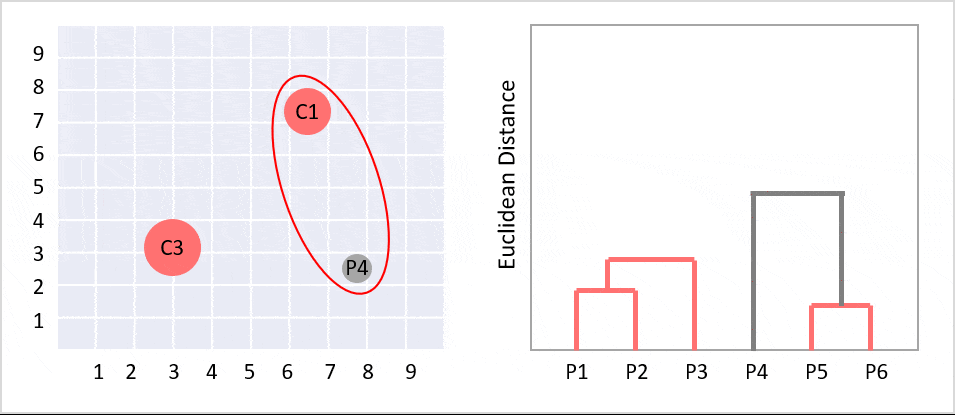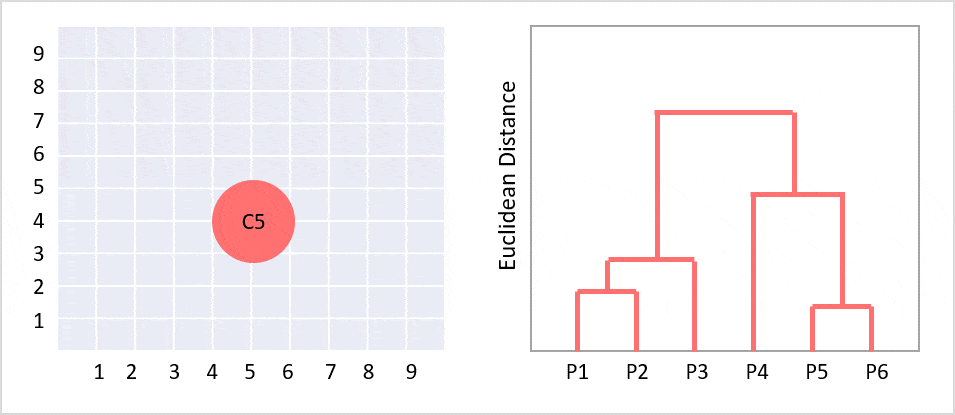
階層的クラスタリングとは、個体からクラスターへ階層構造で分類する分析方法の一つです。樹形図(デンドログラム)ができます。デンドログラムとは、クラスター分析において各個体がクラスターにまとめられていくさまを樹形図の形で表したもののことです。ツリーのルートは、すべてのデータをクラスターで分類しており、一番下の部分は1件のデータになっています。
左側の図はクラスタリングする前のデータ分布で例えばこれを階層型クラスタリングしたものが右側の図になります(gifで過程が見えるようになっています)。この樹形図のグラフをよく階層型クラスターと呼びます。
1.2 階層的クラスタリングの長所と短所
クラスタリング手法の中でもkmeanのような非階層型クラスタリングと比べた時に以下のメリットとデメリットがあります。
長所
・特定の数のクラスター(すなわち、k平均)の仮定なし
・可視化でクラスタリングの様子が自分で確認できる
短所
・ノイズや外れ値に敏感です。
・分類の対象が多い場合はkmeanよりも遅くなりがちなことがある。
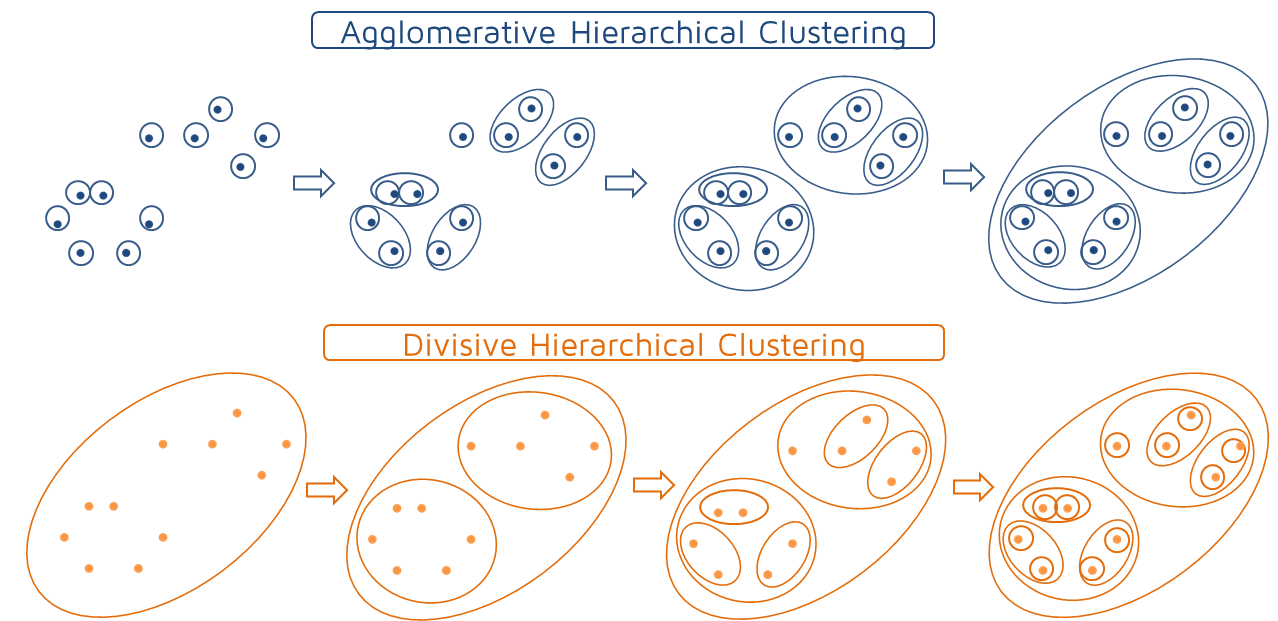
代表的な階層型クラスタリングアルゴリズムには2つあります。
凝集性(Agglomerative)—ボトムアップアプローチ。 多くの小さなクラスターから始め、それらを結合して大きなクラスターを作成します。
分割型(Divisive) —トップダウンアプローチ。 小さなクラスターに分割するのではなく、単一のクラスターから始めます。
1.3 凝集クラスタリングの作成手順
1. 個々のデータが,それぞれ孤立したクラスタを形成している状態から開始します。
2. 全てのクラスタ対の間の距離を計算し,最も近いクラスタ対を見つけます。最も近いクラスタを併合し,この新しいクラスタにします。
3.クラスタが1つだけになるまで、手順2を繰り返します。
1.4 sklearn のAgglomerativeClustering
class sklearn.cluster.AgglomerativeClustering(n_clusters=2, *, affinity=’euclidean’, memory=None, connectivity=None, compute_full_tree=’auto’, linkage=’ward’, distance_threshold=None)
n_clustersint or None, default=2
クラスターの数。
affinitystr or callable, default=’euclidean’
「ユークリッド」、「マンハッタン」、「コサイン」などの距離のパラメーターです。
memorystr or object with the joblib.Memory interface, default=None
ツリーの計算の出力をキャッシュするために使用されます。使うと高速になりまうs。
connectivityarray-like or callable, default=None
各サンプルについて、データの特定の構造に従って、隣接するサンプルを定義します。
compute_full_tree‘auto’ or bool, default=’auto’
n_clustersでツリーの数に停止します。 これは、クラスターの数がサンプルの数と比較して多い場合に、計算時間を短縮するのに役立ちます。
linkage{“ward”, “complete”, “average”, “single”}, default=”ward”
リンケージアルゴリズムは、観測セット間で使用する距離を決定します。
distance_thresholdfloat, default=None
距離がこのしきい値を超えている場合、クラスターはマージされません。
1.5 距離メトリック (Affinity)
データポイント間の距離の計算に使用する方法は、最終結果に影響します。
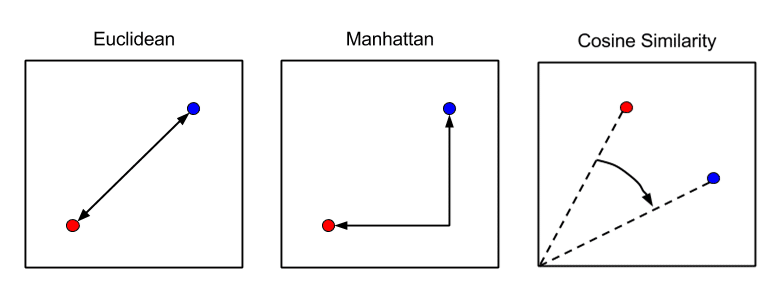
ユークリッド距離(Euclidean Distance)
最も一般的な距離はユークリッド距離でしょう。ユークリッド距離は、人が定規で測るような距離のことです。i 番目のサンプルと j 番目のサンプルとの間の距離 di,j は以下の式のように計算されます。
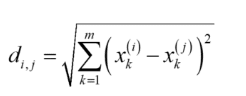
ここで m は変数の数、xk(i) は i 番目のサンプルにおける、k 番目の変数の値です。
マンハッタン距離(Manhattan Distance)
マンハッタン距離は、碁盤の目のように区画された道しか通れない状況で測るような距離です。シティブロック距離とも呼ばれます。距離 di,j は以下のように計算されます。
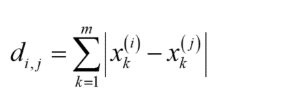
ここで m は変数の数、xk(i) は i 番目のサンプルにおける、k 番目の変数の値です。
サイン類似度(Cosine Similarity Distance)
ベクトル空間モデルにおいて、文書同士を比較する際に用いられる類似度計算手法です。-1から1までの値をとり、数値が大きくなるほど類似度が高いです。
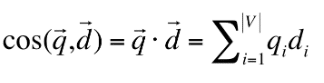
1.6 距離の計算(linkage)
クラスター間の距離の計算方法です。基本的には、Ward法が用いられます。
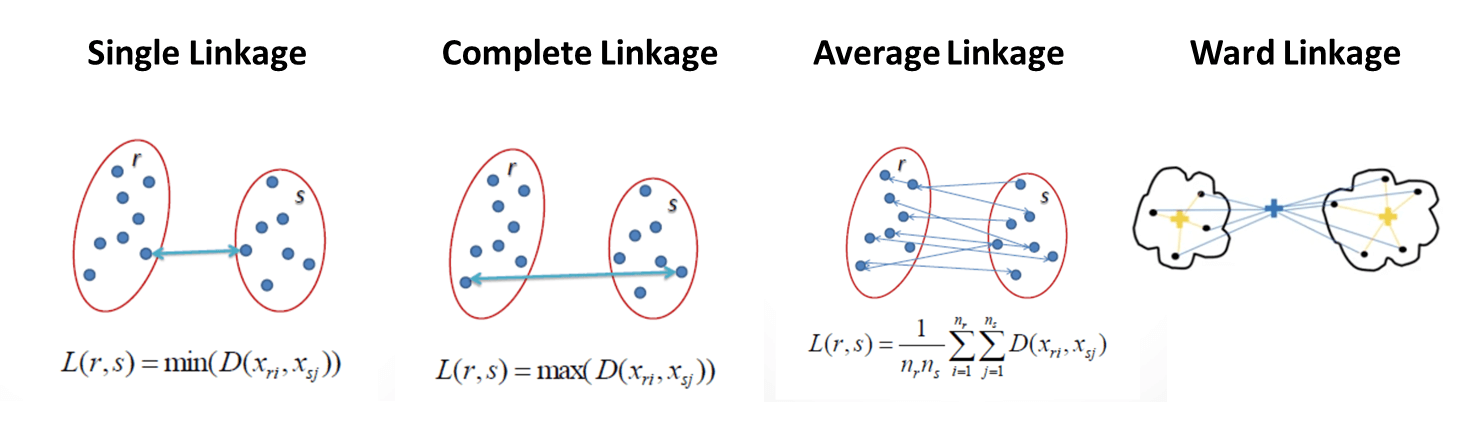
単リンク法 (Single Linkage)
2つのクラスタの距離は、各クラスター内の2点間の最短距離です。単一のリンケージは、クラスターのペアの最も近い観測間の距離を最小化します。
完全リンク法(Complete Linkage)
2つのクラスタの距離は、各クラスターの2つのポイント間の最長距離です。 最大または完全なリンケージは、クラスターのペアの観測間の最大距離を最小化します。
平均法(Average Linkage)
クラスターの距離は、1つのクラスター内の各ポイントから他のクラスター内のすべてのポイントまでの平均距離です。 平均リンケージは、クラスターのペアのすべての観測間の距離の平均を最小化します。
ウォード法(Ward Linkage)
クラスターの距離は、すべてのクラスター内の差の2乗の合計です。 ウォード法は、すべてのクラスター内の差の2乗の合計を最小化します。
2. 実験・コード
環境の概要
環境:Google Colab
データセット:
Iris (アヤメ属) に属する 3 品種、setosa、versicolor、versinicaの特徴量測定値とクラスデータが収められています。
実験:Euclidean、Manhattan、Euclidean
2.1 環境の準備
ライブラリのインポート
import numpy as np from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram from sklearn.datasets import load_iris from sklearn.cluster import AgglomerativeClustering
2.2 データロード
Irisデータセットはアヤメの種類と特徴量に関するデータセットです。3種類のアヤメの分類をやっているのは、Euclidean以外が上手く下のほうで3つに別れている事がわかります。
iris = load_iris() iris
{‘DESCR’: ‘.. _iris_dataset:\n\nIris plants dataset\n——————–\n\n**Data Set Characteristics: …
‘data’: array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
…
[5.9, 3. , 5.1, 1.8]]),
‘feature_names’: [‘sepal length (cm)’,
‘sepal width (cm)’,
‘petal length (cm)’,
‘petal width (cm)’],
‘filename’: ‘/usr/local/lib/python3.6/dist-packages/sklearn/datasets/data/iris.csv’,
‘target’: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
‘target_names’: array([‘setosa’, ‘versicolor’, ‘virginica’], dtype='<U10′)}
X = iris.data X.shape
(150, 4)
可視化関数を作成
def plot_dendrogram(model, **kwargs):
# Create linkage matrix and then plot the dendrogram
# create the counts of samples under each node
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_,
counts]).astype(float)
# Plot the corresponding dendrogram
dendrogram(linkage_matrix, **kwargs)2.3 Euclideanモデル学習・可視化
# setting distance_threshold=0 ensures we compute the full tree. model = AgglomerativeClustering(affinity='euclidean', linkage='ward', distance_threshold=0, n_clusters=None) model = model.fit(X)
デンドログラム
plt.title('Euclidean, linkage=ward')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.show()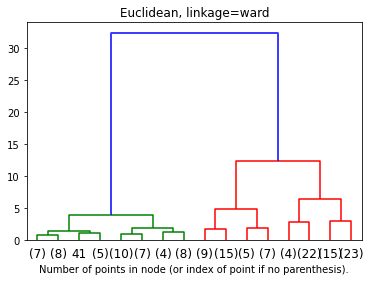
2.4 Manhattanモデル学習・可視化
model = AgglomerativeClustering(affinity='manhattan', linkage='average', distance_threshold=0, n_clusters=None) model = model.fit(X)
デンドログラム
Manhattan のアルゴリズムによって、距離が短くになります。
plt.title('Manhattan, linkage=average')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.show()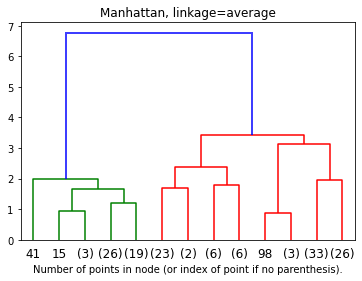
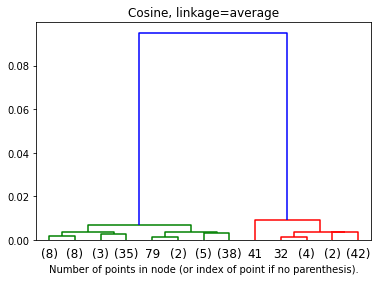
2.5 Cosineモデル学習・可視化
model = AgglomerativeClustering(affinity='cosine', linkage='average', distance_threshold=0, n_clusters=None) model = model.fit(X)
デンドログラム
Cosineのアルゴリズムによって、距離が長くになります。
plt.title('Cosine, linkage=average')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.show()